用户指南¶
图像数据表示法¶
这个 otb::Image 类遵循以下精神 Generic Programming ,其中类型与类的算法行为分开。OTB支持任何像素类型和任何空间维度的图像。
- 创建一个图像。请参见示例 Image1.cxx 。
- 从文件中读取图像。请参见示例 Image2.cxx 。
- 访问像素数据。请参见示例 Image3.cxx 。
- 定义原点和间距。请参见示例 Image4.cxx 。
- 访问图像元数据。请参见示例 MetadataExample.cxx 。
- 矢量图像。请参见示例 VectorImage.cxx 。
- 从缓冲区导入图像数据。请参见示例 Image5.cxx 。
- 图像列表。请参见示例 ImageListExample.cxx 。
读写图像¶
本章介绍支持将图像读写到文件的工具包架构。OTB不强制执行任何特定的文件格式,相反,它提供了从ITK继承的结构,支持各种格式,当新格式出现时,用户可以很容易地扩展这些格式。

Fig. 7 ImageIO类的协作图。
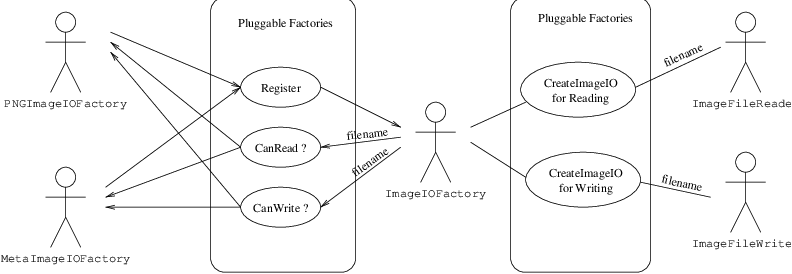
Fig. 8 ImageIO工厂的用例。
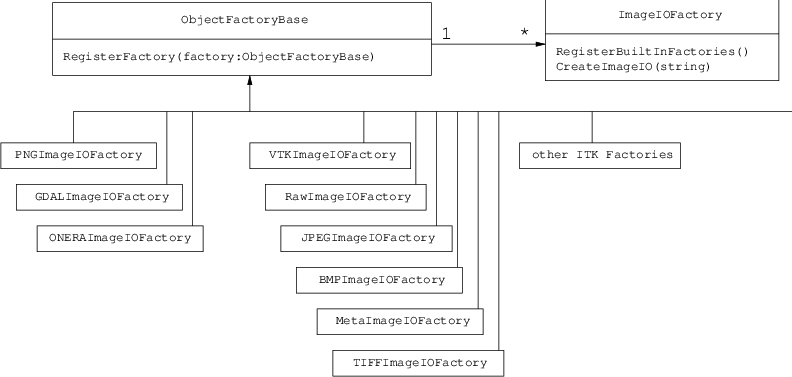
Fig. 9 ImageIO工厂的类图。
- 基本的例子。请参见示例 ImageReadWrite.cxx 。
- 阅读、选角和书写图像。请参见示例 ImageReadCastWrite.cxx 。
- 提取区域。请参见示例 ImageReadRegionOfInterestWrite.cxx 。
读写矢量图像¶
像素类型为向量、协变向量、数组或复合体的图像在图像处理中非常常见。这些类型的图像的用途之一是处理复杂的SLC SAR图像。
- 阅读和书写复杂的图像。请参见示例 ComplexImageReadWrite.cxx 。
- 读写多波段图像。请参见示例 MultibandImageReadWrite.cxx 。
- 提取ROI。请参见示例 ExtractROI.cxx 。
- 阅读影像系列。请参见示例 ImageSeriesIOExample.cxx 。
辅助数据的读写¶
正如我们在上一章中所看到的,OTB具有读取和处理图像的强大能力。然而,图像并不是我们需要处理的唯一数据类型。图像的特点是具有规则的采样网格。对于某些数据,例如数字高程模型(DEM)或激光雷达,这一点限制太多,我们需要其他表示法。
矢量数据也被用来表示地图对象、分割结果等:基本上,所有可以被看到的东西都是点、线或面。OTB提供了访问此类数据的功能。
- 正在读取DEM文件。请参见示例 DEMToImageGenerator.cxx 。
- 使用OTB进行高程管理。请参见示例 DEMHandlerExample.cxx 。
有关表示DEM的更多示例,请参见 [sec:ViewingAltitudeImages] 。
- 读写shapefile和KML。请参见示例 VectorDataIOExample.cxx 。
基本过滤¶
本章介绍OTB中最常用的过滤器。大多数滤镜都是用来处理图像的。它们将接受一个或多个图像作为输入,并产生一个或多个图像作为输出。OTB基于ITK的数据流水线架构,在该架构中,一个过滤器的输出作为输入传递给另一个过滤器。(见第节 [sec:DataProcessingPipeline] 有关更多信息,请参见第页。)
阈值操作用于根据指定的一个或多个值(称为 threshold 值)。以下各节介绍如何使用OTB执行阈值操作。
- 设置点的阈值。请参见示例 ThresholdToPointSetExample.cxx 。
OTB和ITK提供了许多滤镜,允许对图像层执行基本操作(阈值、比率、层组合...)。它允许创建在每个步骤定义操作的处理链,并将它们组合到数据管道中。但该库还提供了在单个滤镜中对图像执行更通用的复杂数学运算的可能性: otb::BandMathImageFilter 更近的是, otb::BandMathImageFilterX 。
现在可以使用新版本的BandMath过滤器;在新功能中,引入了表示多波段像素的变量,以及表示像素邻域的变量。类名称为 otb::BandMathImageFilterX 。
- BandMath过滤器。请参见示例 BandMathFilterExample.cxx 。
- BandMathX过滤器。请参见示例 BandMathXImageFilterExample.cxx 。
- 均值检测器的比率。请参见示例 TouziEdgeDetectorExample.cxx 。
- 均值漂移滤波和聚类。请参见示例 MeanShiftSegmentationFilterExample.cxx 。
- 边缘保持相干斑抑制滤光片。请参见示例 LeeImageFilter.cxx 。请参见示例 FrostImageFilter.cxx 。
- 保边马尔可夫随机场。请参见示例 MarkovRestorationExample.cxx 。
视差图估计¶
本章介绍OTB中可用于估计图像之间的几何差异的工具。
我们要解决的问题是不同传感器采集的图像的视差图自动估计问题。我们所说的不同传感器,是指产生具有不同辐射特性的图像的传感器,即测量不同物理量的传感器:工作在不同光谱波段的光学传感器、雷达和光学传感器等。
对于这类图像对,经典的精细相关方法不能总是提供所需的精度,因为这种相似性度量(相关系数)只能测量辐射计量的仿射变换的相似性。
关于我们想要做什么,可以问两个主要问题:
- 例如,我们能定义雷达和光学图像之间的相似性吗?
- 何去何从 fine registration 指的是几何扭曲如此之大,信息源可能位于不同的地方(例如,光学图像中建筑物屋顶的边缘可以产生相同的边缘,而雷达图像中的墙与地面的反弹可以产生相同的边缘)?
我们可以说,不同传感器获得的同一物体的图像是同一现实的两种不同表现。对于相同的空间位置,我们有两种不同的衡量标准。这两个信息来自相同的来源,因此它们有许多共同的信息。这种关系可能不是完美的,但可以用一种相对的方式进行评估:比较不同的几何扭曲,并保留导致两种测量之间最强联系的那一种。
在处理使用相同(类型)传感器获取的图像时,可以使用一种非常有效的方法。由于相关系数度量对于相似图像是稳健和快速的,所以人们可以将其应用于一幅图像的每一个像素,以便在另一幅图像中搜索对应的HP。因此,可以构建变形栅格(变形贴图的采样)。如果该网格的采样步长足够短,则不需要使用解析模型进行内插,并且可以估计高频变形。得到的网格可以用作重采样网格,从而获得配准图像。
毫无疑问,这种方法与图像内插技术(以估计亚像素变形)和多分辨率策略相结合,可以在变形估计方面获得最佳性能,从而实现图像自动配准。
遗憾的是,在多传感器的情况下,不能使用相关系数。因此,我们将尝试寻找可以应用于多传感器情况的相似性度量,其方法与相关系数相同。
我们首先给出几个允许图像配准问题形式化的定义。首先,我们定义了主映像和从映像:
主图像:其他图像将被配准的图像;其几何形状被视为参考。
从图像:为了配准到主图像而要进行几何变换的图像。
两个主要概念是 similarity measure 而其中一个 geometric transformation :
让我们 I 和 J 成为两个形象,让我们 c 一种相似准则,我们称相似度量为任何标量的严格正函数:
S_c(I,J)=f(I,J,c)。
S_c 具有绝对最大值时,两个图像 I 和 J 是 identical 在标准的意义上 c 。
几何变换 T 是一个运算符,它应用于坐标 (x,y) 在从属图像中的一个点,给出坐标 (u,v) 其主映像中的HP:
\left( \begin{array}{c} u\\ v\\ \end{array}\right) = T \left( \begin{array}{c} x\\ y\\ \end{array}\right)
最后给出了图像配准问题的定义:
注册问题:
确定几何变换 T 这最大化了主图像之间的相似性 I 以及转型的结果 T\circ J :
Arg_max_T(S_c(i,Tcic J));
重新采样 J 通过应用 T 。
几何变形建模¶
定义的几何变换 [defin-T] 用于校正两个待配准图像之间的现有变形。该变形包含链接到观察到的场景和采集条件的信息。根据它们的物理来源,它们可以分为3类:
- 与传感器的平均姿态有关的变形(入射角、有无偏航转向等);
- 与立体视觉有关的变形(主要是由于地形);
- 变形与获取过程中的姿态变化有关(振动主要存在于推扫式传感器中)。
这些变形的特征是它们的空间频率和强度,如表所示 [tab-deform] 。
| 强度 | 空间频率 | |
|---|---|---|
| 中庸态度 | 强壮 | 低 |
| 立体声 | 5~6成熟 | 高级和中级 |
| 态度演变 | 低 | 低至中等 |
表:几何形变源的特征
根据要校正的变形类型,其模型将有所不同。例如,如果唯一要校正的变形是由平均姿态引入的变形,则获取几何体的物理模型(与图像内容无关)就足够了。如果传感器未知,这种变形可以用一个简单的分析模型来近似。当要建模的变形是高频时,解析(参数)模型不适合进行精细配准。在这种情况下,必须使用变形的精细采样,这意味着使用变形网格。对于主图像的一组像素,这些网格给出了它们在从图像中的位置。
以下几点总结了变形建模的问题:
- 解析模型只是变形的近似值。它通常通过以下方式获得:
- 直接来自物理模型,而不使用任何图像内容信息。
- 通过估计先验模型的参数(多项式、仿射等)。这些参数可以估计:
- 或者通过求解通过取HP获得的方程来实现。HP可以手动或自动提取。
- 或者通过最大化全局相似性度量来实现。
- 变形栅格是变形贴图的采样。
最后一点意味着网格的采样周期必须足够短才能考虑高频变形(香农定理)。当然,如果变形是非平稳的(这通常是地形变形的情况),采样可能是不规则的。
作为结论,我们可以说这个定义 [defin-recal] 将注册问题作为优化问题提出。这种优化可以是全局的,也可以是局部的,具有相似性度量,该相似性度量也可以是局部的或全局的。所有这些都在表格中综合 [tab-approches] 。
| 几何模型 | 相似性度量 | 最佳化 |
|---|---|---|
| 物理模型 | 无 | 全球 |
| 分析模型 | 本地 | 全球 |
| 具有先验的HP | ||
| 分析模型 | 全球 | 全球 |
| 没有先验的HP | ||
| 栅极 | 本地 | 本地 |
表:图像配准方法
理想的配准方法是在相似性和形变两方面局部优化配准,以获得最好的配准质量。这是在使用具有密集采样的变形栅格时的情况。不幸的是,这种情况的计算量最大,通常使用网格的低采样率,或者评估一小部分像素中的相似性来估计分析模型。这两种选择都会导致局部配准误差,根据地形的不同,局部配准误差可能达到几个像素。
即使这种配准精度在许多应用中(正射配准、导入到地理信息系统中等)是足够的,但在数据融合、多通道分割或变化检测的情况下是不可接受的。这就是为什么我们将重点放在使用密集网格的变形估计问题上。
相似性度量¶
我们正在寻找的几何变形的精细建模需要估计主图像中从属图像中几乎每个像素的坐标。在经典的单传感器情况下,我们使用相关系数,如下所示。
几何变形用局部刚体位移来模拟。人们想要估计从属图像内主图像的每个像素的坐标。这可以由与主图像的每个像素相关联的位移向量来表示。该向量场的两个组件(线和列)中的每一个都称为变形栅格。
我们使用主图像中的一个小窗口,并测试从属图像内勘探区内每个可能的移位的相似性(图 [zones] )。
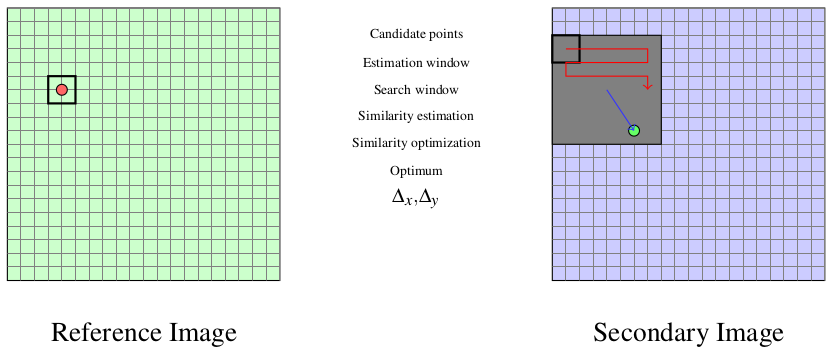
Fig. 10 相关面的估计。
这意味着对于每个位置,我们都要计算相关系数。结果是一个相关曲面,其最大值给出了两个图像之间最有可能的局部偏移:
&\rho_{I,J}(\Delta x, \Delta y) = \\ &\frac{1}{N}\frac{\sum_{x,y}(I(x,y)-m_I)(J(x+\Delta x,y+\Delta y)-m_J)}{\sigma_I \sigma_J}.
在这个表达式中, N 是分析窗口的像素数, m_I 和 m_J 是各个图像的分析窗口内的估计平均值 I 和图像 J 和 \sigma_I 和 \sigma_J 就是它们的标准差。
可以将质量标准应用于估计的最大值,以便给出估计的移位的置信度:峰的宽度、最大值等。可以通过对滑动窗口应用分数移位来测量亚像素移位。这可以通过图像内插来实现。
该过程的有趣参数包括:
- 勘探区域的大小:它决定了算法的计算量(我们想要减少它),但它必须足够大才能处理大变形。
- 滑动窗口的大小:相关系数估计的稳健性随着窗口大小的增加而增加,但局部刚性移位的假设对于大窗口可能不成立。
在多传感器的情况下,相关系数不能用于原始灰度级图像。它可以用于提取的特征(边缘等),但特征提取会引入定位误差。此外,当图像来自使用非常不同的模式的传感器时,可能很难在两幅图像中找到相似的特征。在这种情况下,可以尝试在像素级别找到相似性,但使用其他相似性度量并应用与我们刚才描述的相同的方法。
给出了相似性度量的定义 [def-simil] 。该程序的难点在于找出函数 f 它恰当地代表了标准 c 。我们也需要它 f 使用小窗口可以轻松而可靠地进行评估。
相关系数¶
在此提醒我们计算两个图像窗口之间的相关系数 I 和 J 。窗口内像素的坐标由 (x,y) :
\rho(I,J) = \frac{1}{N}\frac{\sum_{x,y}(I(x,y)-m_I)(J(x,y)-m_J)}{\sigma_I \sigma_J}.
In order to qualitatively characterize the different similarity measures we propose the following experiment. We take two images which are perfectly registered and we extract a small window of size N\times M from each of the images (this size is set to 101\times 101 for this experiment). For the master image, the window will be centered on coordinates (x_0, y_0) (the center of the image) and for the slave image, it will be centered on coordinates (x_0+\Delta x, y_0). With different values of \Delta x (from -10 pixels to 10 pixels in our experiments), we obtain an estimate of \rho(I,J) as a function of \Delta x, which we write as \rho(\Delta x) for short. The obtained curve should have a maximum for \Delta x =0, since the images are perfectly registered. We would also like to have an absolute maximum with a high value and with a sharp peak, in order to have a good precision for the shift estimate.
- 规则网格视差图估计。请参见示例 FineRegistrationImageFilterExample.cxx 。
- 立体重建。请参见示例 StereoReconstructionExample.cxx 。
正射纠正与地图投影¶
如果在图像元数据中没有合适的传感器模型可用,OTB提供了从图像估计传感器模型的可能性。
- 评估传感器型号。请参见示例 EstimateRPCSensorModelExample.cxx 。
方法的局限性¶
正如你现在可能了解的,准确的地理参考需要准确的DEM和准确的传感器模型和参数。在由不同传感器或不同几何构型在同一区域获取多幅图像的情况下,地理参考(地理坐标)或正射校正(地图坐标)通常是不够的。事实上,在处理图像序列时,我们通常希望对它们进行比较(融合、变化检测等)。在像素级别。
由于常见的DEM和传感器参数不能达到这样的精度,我们必须使用巧妙的策略来提高图像的联合配准。经典的方法是通过获取图像之间的同源点进行配准来精炼传感器参数。这称为捆绑块平差,将在即将推出的OTB版本中实施。
即使对模型参数进行细化,也无法消除DEM精度带来的误差。在这种情况下,可以应用图像到图像配准。这些方法将在各章中介绍 [chap:ImageRegistration] 和 [sec:DisparityMapEstimation] 。
- OTB矫正术。请参见示例 OrthoRectificationExample.cxx 。
- 矢量数据投影操作。请参见示例 VectorDataProjectionExample.cxx 。
- 几何投影操作。请参见示例 GeometriesProjectionExample.cxx 。
- 矢量数据区提取。请参见示例 VectorDataExtractROIExample.cxx 。
辐射测量学¶
遥感不仅仅是拍照的问题,而且--主要是--也是测量物理价值的问题。为了正确处理物理震级,必须对传感器提供的数值进行校准。之后,可以计算出几个具有物理意义的指数。
辐射测量指数¶
引言¶
对于多光谱传感器,可以计算几个指数,组合几个光谱波段来显示仅使用一个波段不明显的特征。指数可以显示:
- 植被(选项卡 [tab:vegetationindices] )
- 土壤(选项卡 [tab:soilindices] )
- 水(选项卡 [tab:waterindices] )
- 建成区(选项卡 [tab:builtupindices] )
植被指数是用于测量生物量或植被活力的定量指标,通常由几个光谱波段的组合形成,这些波段的值被相加、除以或相乘,以产生指示植被数量或活力的单个值。
OTB中提供了许多索引,并在表中列出 [tab:vegetationindices] 至 [tab:builtupindices] 以及他们的推荐信。
| NDVI | 归一化差异植被指数 |
| RVI | 植被比率指数 |
| PVI | 垂直植被指数 |
| SAVI | 土壤调整型植被指数 |
| TSAVI | 转化土壤调整植被指数 |
| MSAVI | 改良土壤调整型植被指数 |
| MSAVI2 | 改良土壤调整型植被指数 |
| GEMI | 全球环境监测指数 |
| WDVI | 加权差值植被指数 |
| AVI | 角度植被指数 |
| ARVI | 耐大气植被指数 |
| TSARVI | 转化土壤调整植被指数 |
| EVI | 增强型植被指数 |
| IPVI | 红外植被百分比指数 |
| TNDVI | 转换后的NDVI |
表:植被指数
| IR | 红度指数 |
| IC | 颜色索引 |
| IB | 华晨指数 |
| IB2 | 华晨指数 |
表:土壤指数
| SRWI | 简单比水指数 |
| NDWI | 归一化差值水分指数 |
| NDWI2 | 归一化差值水分指数 |
| MNDWI | 修正的归一化差分水分指数 |
| NDPI | 归一化差值池塘指数 |
| NDTI | 归一化差分浊度指数 |
| SA | 光谱角度 |
表:水指数
| NDBI | 归一化差异组合指数 |
| ISU | 已构建索引曲面 |
表:综合指数
不同索引的用法非常相似,在接下来的几节中只给出几个例子。
NDVI¶
NDVI是许多尝试中最成功的一种,它简单而快速地识别植被覆盖的区域和它们的 condition 在多光谱遥感数据中,它仍然是最广为人知和最常用的绿色植物活体冠层检测指标。一旦证明了探测植被的可行性,用户往往也会使用NDVI来量化植物冠层的光合作用能力。然而,如果做得不好,这可能是一项更为复杂的任务。
- 阿维。请参见示例 ARVIMultiChannelRAndBAndNIRVegetationIndexImageFilter.cxx 。
- 阿维。请参见示例 AVIMultiChannelRAndGAndNIRVegetationIndexImageFilter.cxx 。
大气改正¶
请参见示例 AtmosphericCorrectionSequencement.cxx 。
图像融合¶
卫星传感器在特性方面呈现出重要的多样性。有些提供高空间分辨率,而另一些则专注于提供几个光谱波段。融合过程将来自不同特征的不同传感器的信息聚集在一起,以获得两个世界的最佳结果。
遥感领域中的大多数融合方法都涉及到 pansharpening technique 。这种融合将来自一颗卫星的全色传感器的图像(高空间分辨率数据)与多光谱(XS)数据(多个光谱波段的较低分辨率)相结合,生成具有高分辨率和多个光谱波段的图像。以下几个优势使这种情况变得更容易:
- PAN和XS图像是从同一颗卫星同时拍摄的(或延迟很短);
- 成像区域是两个场景所共有的;
- 许多卫星提供这些数据(Spot 1-5,Quickbird,Pleiades)
这种情况在文献中研究得很多,方法也有很多。OTB目前只有很少的可用的,但这应该很快就会发展起来。
简单平移锐化¶
查看数据全色锐化的一种简单方法是,在相同分辨率下,全色通道是XS通道的总和。在将两个图像放在相同的几何图形中后,经过正射校正(参见第 [sec:Ortho] )通过对XS图像进行过采样,我们可以进行数据融合。
其思想是对全色波段应用低通滤波,以使其具有与XS数据相同的光谱内容(在傅立叶域中)。然后,我们用这个低通全色对XS数据进行归一化,并将结果与原始全色带相乘。
这一过程如图所示 [fig:PanSharpening] 。
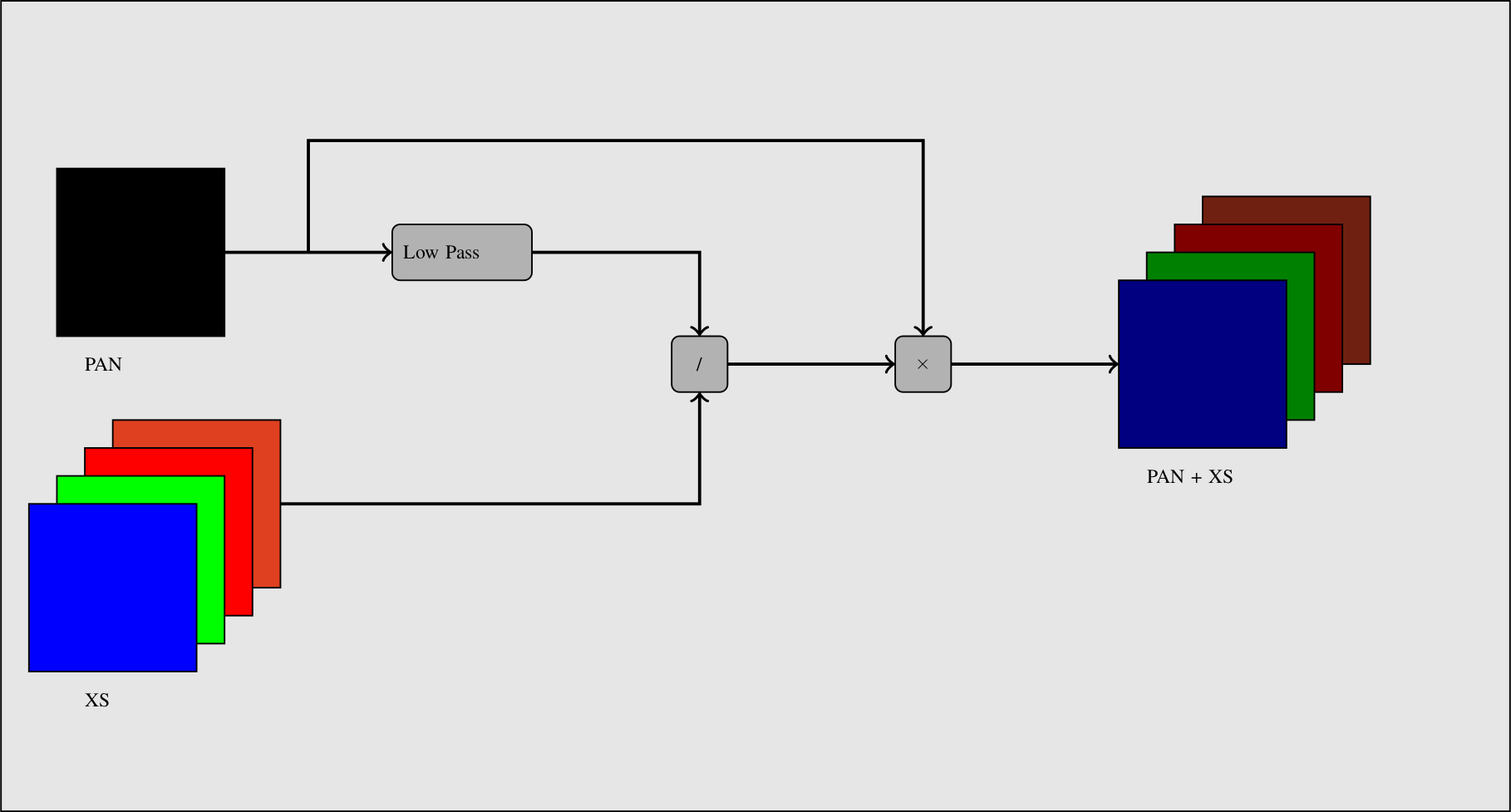
Fig. 11 简单的泛锐化程序。
请参见示例 PanSharpeningExample.cxx 。
贝叶斯数据融合¶
请参见示例 BayesianFusionImageFilter.cxx 。
特征提取¶
利息点¶
- 哈里斯探测器。请参见示例 HarrisExample.cxx 。
- 冲浪探测器。请参见示例 SURFExample.cxx 。
- 线条检测。请参见示例 RatioLineDetectorExample.cxx 。请参见示例 CorrelationLineDetectorExample.cxx 。请参见示例 AsymmetricFusionOfLineDetectorExample.cxx 。
- 分段提取。请参见示例 LineSegmentDetectorExample.cxx 。
- 直角探测器。请参见示例 RightAngleDetectionExample.cxx 。
几何矩¶
复数矩¶
复数几何矩定义为:
c_{pq} = \int\limits_{-\infty}^{+\infty}\int\limits_{-\infty}^{+\infty}(x + iy)^p(x- iy)^qf(x,y)dxdy,
哪里 x 和 y 是图像的坐标 f(x,y) , i 是虚数单位, p+q 的顺序是 c_{pq} 。几何矩在比例更改的情况下特别有用。
- 图像的复杂时刻。请参见示例 ComplexMomentsImageFunctionExample.cxx 。
- 路径的复杂时刻。请参见示例 ComplexMomentPathExample.cxx 。
胡朋友圈¶
利用代数矩理论,H.ming-Kuel得到了一族关于平面变换的7个不变量,称为Hu不变量。这些不变量可以看作是复矩的非线性组合。在过去的30年里,Hu不变量在目标识别中得到了广泛的应用,因为它们对旋转、缩放和平移都是不变的。
\begin{array}{cccc} \phi_1 = c_{11};& \phi_2 = c_{20}c_{02};& \phi_3 = c_{30}c_{03};& \phi_4 = c_{21}c_{12};\\ \phi_5 = Re(c_{30}c_{12}^3);& \phi_6 = Re(c_{21}c_{12}^2);& \phi_7 = Im(c_{30}c_{12}^3).&\\ \end{array}
已经使用这些不变量来识别飞机轮廓。Flusser和Suk已经使用它们进行图像配准。
- 胡舒立的朋友圈。请参见示例 HuMomentsImageFunctionExample.cxx 。
弗洛瑟时刻¶
几位作者对Hu不变量进行了修改和改进。Flusser利用这些时刻来产生一个新的高阶描述子家族。这些描述符随比例和旋转而不变。它们有以下表达式:
\begin{array}{ccc} \psi_1 = c_{11} = \phi_1; & \psi_2 = c_{21}c_{12} = \phi_4; & \psi_3 = Re(c_{20}c_{12}^2) = \phi_6;\\ \psi_4 = Im(c_{20}c_{12}^2); & \psi_5 = Re(c_{30}c_{12}^3) = \phi_5; & \psi_6 = Im(c_{30}c_{12}^3) = \phi_7.\\ \psi_7 = c_{22}; & \psi_8 = Re(c_{31}c_{12}^2); & \psi_9 = Im(c_{31}c_{12}~2);\\ \psi_{10} = Re(c_{40}c_{12}^4); & \psi_{11} = Im(c_{40}c_{12}^2). &\\ \end{array}
- Flusser Moments for Image。请参见示例 FlusserMomentsImageFunctionExample.cxx 。
云提取¶
- 云检测。请参见示例 CloudDetectionExample.cxx 。
图像模拟¶
本章介绍了图像仿真算法。利用物体的透射率和反射率以及传感器特性,可以生成逼真的高光谱合成数据集。本章包括PROSPECT(树叶光学特性)和SAIL(树冠双向反射)模型。植被光学特性采用PROSPECT模型进行建模。
PROSAIL模型¶
PROSAIL模型是前景叶光学特性模型和风帆冠层双向反射率模型的结合。PROSAIL还被用于开发恢复植被生物物理特性的新方法。它将冠层反射率的光谱变化与其方向性变化联系起来,前者主要与叶片生化含量有关,后者主要与冠层结构和土壤/植被对比度有关。这一环节是在不同尺度上同时估计在农业、植物生理学或生态学中应用的冠层生物物理/结构变量的关键。PROSAIL已成为最受欢迎的辐射传输工具之一,因为它易于使用,一般的健壮性,以及多年来实验室/野外/空间实验的一致性验证。在这里,我们提供了第一个示例,它返回从以下位置采样的波长的半球反射率和查看反射率 400 至 2500 nm 。输入是叶和传感器(内在和外在)特性。
请参见示例 ProsailModel.cxx 。
图像模拟¶
在这里,我们提出了一个完整的管道,利用传感器特性和物体的反射和透射率特性来模拟图像。此示例使用:
- 输入图像
- 标签图像:描述图像对象属性。
- 标签属性:描述每个标签特征。
- MASK:植被图像蒙版。
- 云遮罩(可选)。
- 采集参数文件:包含采集参数的文件。
- RSR文件:要使用的相对光谱响应的文件名。
- 传感器FTM文件:传感器空间内插的文件名。
算法分为以下几个步骤:
- 基于NDVI公式的LAI(叶面积指数)图像估计
- 传感器减少光谱响应(RSR)使用PROSAIL反射率输出在传感器光谱波段内插。
- 使用传感器RSR和传感器FTM模拟图像。
- LAI图像估计。请参见示例 LAIFromNDVIImageTransform.cxx 。
- 传感器RSR图像模拟。请参见示例 LAIAndPROSAILToSensorResponse.cxx 。
降维¶
降维是一个统计过程,它将多变量数据中的信息量集中到较少的变量(或维度)中。Fodor对该领域进行了一次有趣的审查。
虽然文献中有大量的非线性方法,但到目前为止,OTB只提供了应用于图像的线性降维技术。
通常,线性降维算法试图找到一组输入图像波段的线性组合,以最大化给定的标准,通常选择这样的标准,以便图像信息集中在第一个分量上。算法的不同之处在于优化的标准,以及它们对信号或图像噪声的处理。
在遥感图像处理中,降维算法无论是用于去噪,还是作为特征图像分类或高光谱图像分解的前期处理,都是人们非常感兴趣的。除去噪效果外,后两种降维方法的优点是降低了待分析数据的大小,从而在不损失太多精度的情况下加快了处理时间。
- 主成分分析。请参见示例 PCAExample.cxx 。
- 噪声调整的主成分分析。请参见示例 NAPCAExample.cxx 。
- 最大噪声分数。请参见示例 MNFExample.cxx 。
- 快速独立分量分析。请参见示例 ICAExample.cxx 。
- 最大自相关因子。请参见示例 MaximumAutocorrelationFactor.cxx 。
分类¶
机器学习框架¶
OTB分类是作为通用机器学习框架实现的,支持几种可能的机器学习库作为后端。基类 otb::MachineLearningModel 定义了这个框架。从现在的libSVM(历史上集成在OTB中的机器学习库)开始,OpenCV库()和Shark机器学习库()的机器学习方法都是可用的。该框架同时支持监督和非监督分类器。
可通过OTB内的同一通用接口获得的当前分类器列表为:
- LibSVM :基于libSVM的支持向量机分类器。
- SVM :基于OpenCV的支持向量机分类器,本身就是基于libSVM的。
- Bayes 基于OpenCV的正态贝叶斯分类器。
- Boost :基于OpenCV的Boost分类器。
- DT :基于OpenCV的决策树分类器。
- RF :OpenCV中基于随机树的随机森林分类器。
- KNN :基于OpenCV的K-近邻分类器。
- ANN :基于OpenCV的人工神经网络分类器。
- SharkRF :基于Shark的随机森林分类器。
- SharkKM :K是指基于Shark的无监督分类器。
这些型号具有通用接口,具有以下主要功能:
SetInputListSample(InputListSampleType* in):设置输入样本列表SetTargetListSample(TargetListSampleType* in):设置目标样本列表Train():根据输入样本训练模型Save():将模型保存到文件Load():从文件加载模型Predict():预测输入样本的目标值PredictBatch():对输入样本列表进行预测
从多线程筛选器或从单个位置调用该函数时,该函数可以是多线程的。在后一种情况下,它使用OpenMP创建多个线程。在模型类的顶部有一个工厂机制(请参见 otb::MachineLearningModelFactory )。给定一个输入文件,静态函数能够实例化正确类型的模型。
对于非监督模型,目标样本 still have to be set 。它们不会被使用,因此您可以用零填充ListSample。
培训模型¶
这些模型是从存储在a中的输入样本列表中训练的。对于监督分类器,他们还需要与每个输入样本相关联的目标列表。无论样本的来源是什么,在输入到模型中之前,都必须将其转换为A。
然后,可以设置特定于型号的参数。最后,该方法开始学习步骤。一旦训练好模型,就可以使用函数将其保存到文件中。下面的例子展示了如何做到这一点。
请参见示例 TrainMachineLearningModelFromSamplesExample.cxx 。
请参见示例 TrainMachineLearningModelFromImagesExample.cxx 。
模型的预测¶
对于预测步骤,通常的流程是:
- 从文件加载现有模型。
- 将要预测的数据转换为。
- 运行该函数。
有一个图像滤镜可以对整个图像执行这一步骤,支持流媒体和多线程: otb::ImageClassificationFilter 。
请参见示例 SupervisedImageClassificationExample.cxx 。
应用程序中的集成¶
这些分类器集成在多个OTB应用程序中。有一个基类提供了对所有分类器的轻松访问:LearningApplicationBase。因为每个机器学习模型都有一组特定的参数,所以基类知道如何用它的专用参数公开每种类型的分类器(这项任务有点乏味,所以我们只想实现它一次)。该方法创建一个名为的CHOICE参数,该参数包含不同的受支持分类器及其参数。
该功能提供了一种简单的方法来训练所选的分类器,以及相应的参数,并将模型保存到文件中。
另一方面,该函数允许从文件加载模型并将其应用于样本列表。
非监督分类¶
K-均值分类¶
KMeans算法已经在Shark库中实现,并被包装在OTB机器学习框架中。这是该框架中的第一个非监督算法。它可以以与其他机器学习模型相同的方式使用。请记住,即使非监督模型不使用样本上的标签信息,仍必须设置目标ListSample。可以使用以零填充的ListSample。
此模型使用具有以下参数的硬群集模型:
- 最大迭代次数
- 质心数(K)
- 归一化输入样本的选项
就像鲨鱼随机森林一样,训练步骤是平行的。
Kohonen的自组织映射¶
自组织映射(SOM)是Kohonen提出的一种无监督神经学习算法。该映射由相互竞争的相邻细胞组成,这些细胞通过相互作用进行调整,以匹配学习过程中给出的例子的特征模式。SOM通常位于平面(2D)上。
该算法实现了从高维特征空间到低维空间(通常是2D)的非线性投影。它能够在保持特征空间中存在的拓扑关系的同时,找到一组结构化数据与低维网络之间的对应关系。多亏了这种拓扑组织,最终的地图呈现了集群及其关系。

Fig. 12 Kohonen的自组织映射
A cell (or neuron) in the map is a good detector for a given input vector \underline x = \left[x_{1},x_{2},\cdots,x_{n}\right]^T\in \mathbb{R}^n if the latter is close to the former. This distance between vectors can be represented by the scalar product \underline{x}^T\cdot\underline{m_i}, but for most of the cases other distances can be used, as for instance the Euclidean one. The cell having the weight vector closest to the input vector is called the winner.
学习步骤的目标是获得代表输入示例集的映射。这是一个迭代过程,包括将每个输入示例传递给映射,测试每个神经元的响应,并修改映射以使其更接近示例。
SOM学习:
t=0 。
初始化贴图的权重向量(例如随机)。
而当 t< 迭代次数,执行:
k=0 。
而当 k< 例子的数量,做:
找到向量 \underline{m}_i(t) 从而将距离最小化 d(\underline{x}_k,\underline{m}_i(t))
对于一个社区来说 N_c(t) 在获胜单元格周围,应用变换:
\underline{m}_i(t+1)=\underline{m}_i(t)+\beta(t)\left[\underline{x}_k(t)-\underline{m}_i(t)\right]
k=k+1
t=t+1 。
在……里面 [khoupdate] , \beta(t) 是到获胜者单元的几何距离的递减函数。例如:
\beta(t)=\beta_0(t)e^{-\frac{\parallel \underline{r}_i - \underline{r}_c\parallel^2}{\sigma^2(t)}},
使用 \beta_0(t) 和 \sigma(t) 随时间递减的函数和 \underline{r} 单元格在输出地图空间中的坐标。
因此,算法在于使映射更接近学习集。利用Winner细胞周围的邻域,可以将地图组织成专门识别不同模式的区域。该邻域还确保拓扑上接近的单元在特征空间中定义的距离方面也是接近的。
- 建立一个颜色表。请参见示例 SOMExample.cxx 。
- SOM分类。请参见示例 SOMClassifierExample.cxx 。
- 多波段、流分类。请参见示例 SOMImageClassificationExample.cxx ..特克斯
随机期望最大化¶
随机期望最大化(SEM)方法是EM混合估计的随机版本,见部分 [sec:ExpectationMaximizationMixtureModelEstimation] 。它是由引入的,以防止EM方法从局部极小点收敛。它避免了在估计过程中集成随机抽样过程而产生的分析极大化问题。它引发了几乎肯定的(A.S.)收敛到算法。
根据EM混合估计的初始两步公式,结构方程可分解为3个步骤:
- E-step 计算每个测量向量到每个类别的预期隶属度值。
- S-step 根据在E步骤中计算的隶属度值,对每个类别执行隶属度向量的随机抽样。
- M-step 更新成员概率的参数(通过类及其继承的类定义的参数)。
在隶属度参数的评估以每个像素的空间邻域的隶属度值为条件的意义上,扫描电子显微镜的实现已经转向上下文扫描电子显微镜。
请参见示例 SEMModelEstimatorExample.cxx 。
马尔可夫随机场¶
马尔可夫随机场是一种概率模型,它使用邻域中像素之间的统计相关性来增加给定像素的值。
请参见示例 MarkovClassification1Example.cxx 。
请参见示例 MarkovClassification2Example.cxx 。
请参见示例 MarkovClassification3Example.cxx 。
请参见示例 MarkovRegularizationExample.cxx 。
分类地图的融合¶
邓普斯特·谢弗¶
一种使用邓普斯特-谢弗理论(http://en.wikipedia.org/wiki/Dempster-Shafer_theory)的更自适应的融合方法在OTB内可用。这种方法是自适应的,因为它是基于每个分类映射的每个类别标签的所谓信任函数。因此,每个分类像素与根据所使用的分类器的置信度相关联。在Dempster Shafer框架中,专家的观点(即具有高信任函数)被认为是真理。为了估计每个类别标签的置信度函数,我们对每个类别标签和每个分类映射使用信任质量的Dempster Shafer组合。在该框架中,每个像素的输出融合标签是具有最大置信度函数的像素。
与多数投票方法一样,Dempster Shafer融合处理具有最大置信度函数的非唯一类标签。在这种情况下,输出的融合像素被设置为未定值。
所有类别标签的置信度水平是通过比较分类图来估计的,以与基本事实融合,这导致了混淆矩阵。对于每个分类图,这些混淆矩阵然后被用来估计每个类别标签的置信度。
组合算法的数学表述¶
Dempster Shafer组合算法的数学公式描述可在以下OTB维基页面中找到:http://wiki.orfeo-toolbox.org/index.php/Information_fusion_framework.
- 邓普斯特·谢弗融合的一个例子。请参见示例 DempsterShaferFusionOfClassificationMapsExample.cxx 。
- 分类地图正规化。请参见示例 ClassificationMapRegularizationExample.cxx 。
基于对象的图像分析¶
- 基于辐射测量和统计属性的对象过滤。请参见示例 RadiometricAttributesLabelMapFilterExample.cxx 。
- 用于比较细分的胡佛指标。请参见示例 HooverMetricsEstimation.cxx 。
更改检测¶
平均差¶
最简单的变化检测器基于图像值的像素差值:
I_{D}(i,j)=i_{2}(i,j)-i_{1}(i,j)。
为了使算法对噪声具有健壮性,人们实际上使用了局部均值而不是像素值。
请参见示例 DiffChDet.cxx 。
平均比率¶
此检测器类似于前一个检测器,只是它使用比率而不是差值:
\displaystyle I_{R}(i,j) = \frac{\displaystyle I_{2}(i,j)}{\displaystyle I_{1}(i,j)}.
该比率的使用使得该检测器对乘性噪声具有较强的鲁棒性,这是对雷达图像中存在的斑点现象的一个很好的模型。
为了具有有界和归一化的检测器,实际上使用了以下表达式:
\displaystyle I_{R}(i,j) = 1 - min \left(\frac{\displaystyle I_{2}(i,j)}{\displaystyle I_{1}(i,j)},\frac{\displaystyle I_{1}(i,j)}{\displaystyle I_{2}(i,j)}\right).
请参见示例 RatioChDet.cxx 。
统计检测器¶
局部分布之间的距离¶
该探测器类似于均值探测器的比率(见上一节第7页)。然而,不是对均值进行比较,而是对两个随机变量(RV)的完全分布进行比较。
该检测器基于概率密度函数之间的Kullback-Leibler距离(Pdf)。在该图像对的每个像素的邻域中 I_1 和 I_2 要进行比较,本地pdf之间的距离 f_1 和 f_2 房车的数量 X_1 和 X_2 通过以下方式进行评估:
{\cal K}(X_1,X_2) &= K(X_1|X_2) + K(X_2|X_1) \\ \text{with} \qquad K(X_j | X_i) = \int_{R} \log \frac{f_{X_i}(x)}{f_{X_j}(x)} f_{X_i}(x) dx,\qquad i,j=1,2.
为了减少计算时间,本地pdf f_1 和 f_2 不是通过直方图计算来估计的,而是通过累积量展开来估计的,即埃奇沃斯展开,其基于房车的累积量:
f_X(x) = \left( 1 + \frac{\kappa_{X;3}}{6} H_3(x) + \frac{\kappa_{X;4}}{24} H_4(x) + \frac{\kappa_{X;5}}{120} H_5(x) + \frac{\kappa_{X;6}+10 \kappa_{X;3}^2}{720} H_6(x) \right) {\cal G}_X(x).
在等式中, {\cal G}_X 代表与RV具有相同均值和方差的高斯pdf X 。这个 \kappa_{X;k} 系数是阶的累积量 k ,以及 H_k(x) 是阶切比雪夫-埃尔米特多项式吗 k (有关更深层次的解释,请参见下文)。
请参见示例 KullbackLeiblerDistanceChDet.cxx 。
局部相关¶
相关系数衡量两个随机变量之间线性关系的可能性:
I_\rho(i,j) &= \frac{1}{N}\frac{\sum_{i,j}(I_1(i,j)-m_{I_1})(I_2(i,j)-m_{I_2})}{\sigma_{I_1} \sigma_{I_2}}\\ & = \sum_{(I_1(i,j),I_2(i,j))}\frac{(I_1(i,j)-m_{I_1})(I_2(i,j)-m_{I_2})}{\sigma_{I_1} \sigma_{I_2}}p_{ij}
哪里 I_1(i,j) 和 I_2(i,j) 是2个图像的像素值,并且 p_{ij} 是联合概率密度。这类似于使用线性模型:
I_2(i,j)=(i_1(i,j)-m_{I_1})frac{sigma_{I_2}}{sigma_{I_1}}+m_{I_2}
为此,我们用以下方法评估可能性 p_{ij} 。
关于差值探测器,该探测器对光照变化具有很强的鲁棒性。
请参见示例 CorrelChDet.cxx 。
多尺度探测器¶
分布间的Kullback-Leibler距离¶
该技术是对第节中提出的分布间距离变化检测器的扩展 [sec:KullbackLeiblerDistance] 。由于这种检测器是基于通过滑动窗口的累积量估计的,所以其思想是只要滑动窗口的尺寸增大,就通过考虑新的样本来更新累积量的估计。
让我们来考虑下面的问题:当一个人 N+1^{th} 观察 x_{N+1} 被添加到一组观察中 \{x_1, x_2, \ldots, x_N\} 已经考虑过了。中心时刻的演变可以用以下几个方面来描述:
\mu_{1,[N]} & = \frac{1}{N} s_{1,[N]} \\ \mu_{r,[N]} & = \frac{1}{N} \sum_{\ell = 0}^r \binom{r}{\ell} \left( -\mu_{1,[N]} \right)^{r-\ell} s_{\ell,[N]}
其中的符号 s_{r,[N]} = \sum_{i=1}^N x_i^r 已经被使用过。然后,还通过将矩转换为累积量来更新Edgeworth级数,方法是使用:
\kappa_{X;1} &= \mu_{X;1}\\ \kappa_{X;2} &= \mu_{X;2}-\mu_{X;1}^2\\ \kappa_{X;3} &= \mu_{X;3} - 3\mu_{X;2} \mu_{X;1} + 2\mu_{X;1}^3\\ \kappa_{X;4} &= \mu_{X;4} - 4\mu_{X;3} \mu_{X;1} - 3\mu_{X;2}^2 + 12 \mu_{X;2} \mu_{X;1}^2 - 6\mu_{X;1}^4.
它根据分析窗口的增大大小产生一组表示变化测量的图像。
请参见示例 KullbackLeiblerProfileChDet.cxx 。
多组分检测器¶
- 多变量蚀变检测器。请参见示例 MultivariateAlterationDetector.cxx 。
图像可视化与输出¶
在使用OTB处理您的图像后,您可能想要查看结果。因为它在某些情况下非常简单,在其他情况下可能会稍微棘手一些。例如,某些过滤器会将多边形列表作为输出。其他的可以返回一个图像,每个区域都有一个唯一的索引。在本节中,我们将提供几个示例来帮助您生成漂亮的输出,以便随时包含在您的出版物/演示文稿中。
图片¶
- 灰度图像。请参见示例 ScalingFilterExample.cxx 。
- 多波段图像。请参见示例 PrintableImageFilterExample.cxx 。
- 索引图像。请参见示例 IndexedToRGBExample.cxx 。
- 海拔图像。请参见示例 DEMToRainbowExample.cxx 。请参见示例 HillShadingExample.cxx 。