6.13. HTTP关键字¶
使用HTTP特定的粘滞缓冲区提供了一种有效检查HTTP协议的特定字段的方法。在规则中指定粘滞缓冲区后,后面应该跟一个或多个doc:payload-keywords。
许多粘性缓冲区在旧的“内容修饰符”表示法中有遗留变体。看见 修饰词 了解更多信息。作为复习生:
'粘性缓冲区' 首先放置,其后的所有关键字将应用于该缓冲区,例如:
alert http any any -> any any (http.response_line; content:"403 Forbidden"; sid:1;)
粘滞缓冲区适用于它后面的所有“有效负载”关键字。例如。 content , isdataat , byte_test , pcre 。
'内容修饰符' 回顾一下规则,例如:
alert http any any -> any any (content:"index.php"; http_uri; sid:1;)
内容修饰符仅适用于前面的 content 关键字。
以下 请求 关键字可用:
关键字 |
传统内容修改器 |
方向 |
|---|---|---|
http.uri |
http_uri |
请求 |
http.uri.raw |
http_raw_uri |
请求 |
http.method |
http_method |
请求 |
http.request_line |
HTTP_REQUEST_LINE(*) |
请求 |
http.request_body |
http_client_body |
请求 |
http.header |
http_header |
两个 |
http.header.raw |
http_raw_header |
两个 |
http.cookie |
http_cookie |
两个 |
http.user_agent |
http_user_agent |
请求 |
http.host |
http_host |
请求 |
http.host.raw |
http_raw_host |
请求 |
http.accept |
HTTP_Accept(*) |
请求 |
http.accept_lang |
HTTP_ACCEPT_LANG(*) |
请求 |
http.accept_enc |
HTTP_Accept_enc(*) |
请求 |
http.referer |
HTTP_REFERER(*) |
请求 |
http.connection |
HTTP_CONNECTION(*) |
请求 |
http.content_type |
HTTP_CONTENT_TYPE(*) |
两个 |
http.content_len |
HTTP_CONTENT_LEN(*) |
两个 |
http.start |
HTTP_START(*) |
两个 |
http.protocol |
HTTP_PROTOCOL(*) |
两个 |
http.header_names |
HTTP_HEADER_NAMES(*) |
两个 |
*)粘性缓冲区
以下 响应 关键字可用:
关键字 |
传统内容修改器 |
方向 |
|---|---|---|
http.stat_msg |
http_stat_msg |
响应 |
http.stat_code |
http_stat_code |
响应 |
http.response_line |
HTTP_RESPONSE_LINE(*) |
响应 |
http.header |
http_header |
两个 |
http.header.raw |
http_raw_header |
两个 |
http.cookie |
http_cookie |
两个 |
http.response_body |
http_server_body |
响应 |
http.server |
不适用 |
响应 |
http.location |
不适用 |
响应 |
file.data |
文件数据(*) |
响应 |
http.content_type |
HTTP_CONTENT_TYPE(*) |
两个 |
http.content_len |
HTTP_CONTENT_LEN(*) |
两个 |
http.start |
HTTP_START(*) |
两个 |
http.protocol |
HTTP_PROTOCOL(*) |
两个 |
http.header_names |
HTTP_HEADER_NAMES(*) |
两个 |
*)粘性缓冲区
6.13.1. HTTP入门¶
了解HTTP请求和响应的结构很重要。HTTP请求和响应的简单示例如下:
HTTP请求
GET /index.html HTTP/1.0\r\n
GET是请求 方法 。方法的示例有:GET、POST、PUT、HEAD等。 /index.html HTTP版本是 HTTP/1.0 。多年来已经使用了几个HTTP版本;在0.9、1.0和1.1版本中,1.0和1.1是目前最常用的版本。
包含关键字的示例请求:
HTTP |
关键字 |
GET/index.html HTTP/1.1\r\n |
http.request_line |
主机:www.oisf.net\r\n |
http.header |
Cookie: <cookie data> |
http.cookie |
具有更细粒度关键字的示例请求:
HTTP |
关键字 |
GET /index.html HTTP/1.1\r\n |
http.method http.uri http.protocol |
主机: www.oisf.net \r\n 用户-代理: Mozilla/5.0 \r\n |
http.host |
http.user_agent |
|
Cookie: <cookie data> |
http.cookie |
HTTP响应
HTTP/1.0 200 OK\r\n
<html>
<title> some page </title>
</HTML>
在本例中,HTTP/1.0是HTTP版本,200是响应状态代码,OK是响应状态消息。
尽管cookies是在HTTP头中发送的,但是您不能将它们与 http.header 关键字。cookie与自己的关键字匹配,即 http.cookie .
表的每个部分都属于所谓的 缓冲区 .HTTP方法属于方法缓冲区、HTTP头属于头缓冲区等。缓冲区是Suricata在内存中提取以供检查的请求或响应的特定部分。
前面描述的所有关键字都可以与签名中的缓冲区结合使用。关键词 distance 和 within 是相对修饰符,因此它们只能在同一个缓冲区中使用。不能将内容匹配与带有相对修饰符的不同缓冲区相关联。
6.13.2. http.method¶
与 http.method 内容修饰符,可以专门匹配,并且只能在HTTP方法缓冲区上匹配。关键字可以与前面提到的所有内容修饰符组合使用,例如: depth , distance , offset , nocase 和 within .
方法示例如下: GET , POST , PUT , HEAD , DELETE , TRACE , OPTIONS , CONNECT 和 PATCH .
HTTP请求中的方法示例:

方法目的示例:



6.13.3. http.uri以及http.uri.raw¶
与 http.uri 以及 http.uri.raw 内容修饰符,可以专门匹配,并且只能在请求URI缓冲区上匹配。关键字可以与前面提到的所有内容修饰符(如 depth , distance , offset , nocase 和 within .
uri在Suricata中有两种表现形式:uri.raw文件以及规范化的uri。例如,空格可以用十六进制符号%20表示。在一个空间中转换这个符号,意味着将它规范化。但是可以在uri中匹配特定的字符%20。这意味着匹配uri.raw文件. 这个uri.raw文件规范化的uri是独立的缓冲区。所以,那个uri.raw文件检查uri.raw文件缓冲区不能检查规范化缓冲区。
注解
uri.raw中从来没有任何空格。使用此请求行 GET /uid=0(root) gid=0(root) HTTP/1.1 ,即 http.uri.raw 将匹配 /uid=0(root) 和 http.protocol 将匹配 gid=0(root) HTTP/1.1 参考资料: https://redmine.openinfosecfoundation.org/issues/2881
HTTP请求中的URI示例:

目的示例 http.uri :

6.13.4. 尿酸含量¶
这个 uricontent 关键字的效果与 http.uri 内容修饰符。 uricontent 是一种不推荐(尽管仍然支持)的方法,只能在请求URI缓冲区上进行特定匹配。
实例 uricontent :
通知tcp$home_net any->$external_net$http_ports(msg:“et-trojan-possible vundo-trojan-variant-reporting-to-controller”;流:established,to_-server;内容:“post”;深度:5; uricontent:"/frame.html?"; urilen:>80;classtype:trojan活动;reference:url,doc.emergingthreats.net/2009173;reference:url,www.emergingthreats.net/cgi-bin/cvsweb.cgi/sigs/virus/trojan-vundo;sid:2009173;rev:2;)
两者之间的区别 http.uri 和 uricontent 是语法:


在编写新规则时,建议 http.uri 使用内容粘性缓冲区而不是不推荐使用的缓冲区 uricontent 关键字。
6.13.5. 乌里伦¶
这个 urilen 关键字用于匹配请求URI的长度。可以使用 < 和 > 运算符,分别表示 小于 和 大于 .
格式 urilen 是::
urilen:3;
其他可能性包括:
urilen:1;
urilen:>1;
urilen:<10;
urilen:10<>20; (bigger than 10, smaller than 20)
例子:

实例 urilen 在签名中:
警告tcp$home_net any->$external_net$http_ports(msg:“et-trojan-possible vundo-trojan-variant-reporting-to-controller”;流:established,to_-server;内容:“post”;深度:5;uricontent:“/frame.html?”(二) urilen: > 80; 类类型:特洛伊木马活动;参考:url,doc.emergingthreats.net/2009173;参考:url,www.emergingthreats.net/cgi-bin/cvsweb.cgi/sigs/virus/trojan-vundo;sid:2009173;版本:2;)
您还可以附加 norm 或 raw 定义要使用的缓冲区类型(规范化缓冲区或原始缓冲区)。
6.13.6. http.protocol¶
这个 http.protocol 检查HTTP请求或响应行中的协议字段。如果请求行是'get/http/1.0rn',则此缓冲区将包含'http/1.0'。
例子::
alert http any any -> any any (flow:to_server; http.protocol; content:"HTTP/1.0"; sid:1;)
http.protocol 替换以前的关键字名称: `http_protocol .可以继续+使用以前的名称,但建议将规则转换为使用+新名称。
例子::
alert http any any -> any any (flow:to_server; http.protocol; content:"HTTP/1.0"; sid:1;)
6.13.7. http.request_line¶
这个 http.request_line 强制检查整个HTTP请求行。
例子::
alert http any any -> any any (http.request_line; content:"GET / HTTP/1.0"; sid:1;)
6.13.8. http.header以及http.header.raw¶
与 http.header 内容修饰符,可以专门匹配,并且只能在HTTP头缓冲区上匹配。这将在一个缓冲区中包含所有提取的头,除了文档中指出的那些不能被这个缓冲区匹配并且有自己的内容修饰符(例如 http.cookie )。修饰符可以与前面提到的所有内容修饰符组合使用,例如 depth , distance , offset , nocase 和 within .
Note :标头缓冲区为 规格化 。所有尾随空格和制表符都将被删除。请参阅:https://lists.openinfosecfoundation.org/pipermail/oisf-users/2011-October/000935.html.如果同一标头名称有多个值,则在每个值之间用逗号和空格(“,”)连接。请参阅RFC 2616 4.2消息报头。要避免这种情况,请使用
http.header.raw关键字。
HTTP请求中的头示例:

目的示例 http.header :

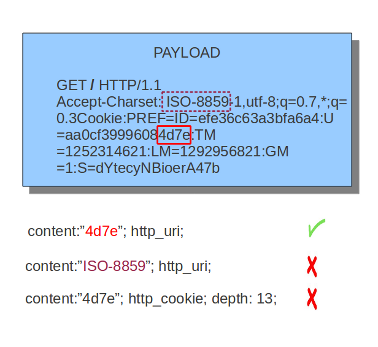
6.13.9. http.cookie¶
与 http.cookie 内容修饰符,可以专门匹配,并且只能在cookie缓冲区上匹配。关键字可以与前面提到的所有内容修饰符(如 depth , distance , offset , nocase 和 within .
注意,cookie是在HTTP头中传递的,但是被提取到一个专用的缓冲区,并使用它们自己的特定内容修饰符进行匹配。
HTTP请求中的cookie示例:

目的示例 http.cookie :
6.13.10. http.user_agent¶
这个 http.user_agent 内容修饰符是HTTP请求头的一部分。它可以在用户代理头的值上进行特定匹配。它是规范化的,因为它不包括“用户代理: "_ 标题名称和分隔符,也不包含尾部回车和换行(CRLF)。关键字可以与前面提到的所有内容修饰符(如 depth , distance , offset , nocase 和 within . 请注意 pcre 关键字还可以在使用 /V 修饰语。
规范化:前导空格 不是 缓冲区的一部分。因此“用户代理”:将导致一个空的 http.user_agent 缓冲区。
HTTP请求中的用户代理头示例:

目的示例 http.user_agent :

6.13.10.1. 笔记¶
这个
http.user_agent缓冲区将不包括头名称、冒号或前导空白。即不包括“用户代理”。这个
http.user_agent缓冲区结尾不包含CRLF(0x0D 0x0A)。如果要匹配缓冲区的结尾,请使用相对isdataat或者PCRE(尽管PCRE的性能会更差)。如果一个请求包含多个“用户代理”头,这些值将在
http.user_agent缓冲区,按从上到下的顺序排列,每个缓冲区之间有逗号和空格(“,”)。请求示例:
GET /test.html HTTP/1.1 User-Agent: SuriTester/0.8 User-Agent: GGGG
http.user_agent缓冲区内容:SuriTester/0.8, GGGG
相应的PCRE修改器:
V使用
http.user_agent缓冲区在性能方面比使用http.header缓冲区(大约10%更好)。https://blog.inliniac.net/2012/07/09/suricata-http_user_agent-vs-http_header/
6.13.11. http.accept¶
要在HTTP接受头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (http.accept; content:"image/gif"; sid:1;)
6.13.12. http.accept_enc¶
在HTTP接受编码头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (http.accept_enc; content:"gzip"; sid:1;)
6.13.13. http.accept_lang¶
在HTTP接受语言头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (http.accept_lang; content:"en-us"; sid:1;)
6.13.14. http.connection¶
要在HTTP连接头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (http.connection; content:"keep-alive"; sid:1;)
6.13.15. http.content_type¶
要在HTTP内容类型头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
使用流:到服务器或流:到客户端强制检查请求或响应。
实例:
alert http any any -> any any (flow:to_server; \
http.content_type; content:"x-www-form-urlencoded"; sid:1;)
alert http any any -> any any (flow:to_client; \
http.content_type; content:"text/javascript"; sid:2;)
6.13.16. http.content_len¶
在HTTP内容长度头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
使用流:到服务器或流:到客户端强制检查请求或响应。
实例:
alert http any any -> any any (flow:to_server; \
http.content_len; content:"666"; sid:1;)
alert http any any -> any any (flow:to_client; \
http.content_len; content:"555"; sid:2;)
要对内容长度进行数字检查, byte_test 可以使用。
例如,如果c-l等于或大于8079,则匹配:
alert http any any -> any any (flow:to_client; \
http.content_len; byte_test:0,>=,8079,0,string,dec; sid:3;)
6.13.17. http.referer¶
要在HTTP引用头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (http.referer; content:".php"; sid:1;)
6.13.18. http.start¶
检查HTTP请求或响应的开始。这将包含请求/响应行和请求/响应头。使用流:到服务器或流:到客户端强制检查请求或响应。
例子::
alert http any any -> any any (http.start; content:"HTTP/1.1|0d 0a|User-Agent"; sid:1;)
缓冲区包含规范化的头,并由一个额外的\r\n终止,以指示头的结尾。
6.13.19. http.header_names¶
检查只包含HTTP头名称的缓冲区。用于确保头不存在或测试头的特定顺序。
缓冲区以\r\n开头,以额外的\r\n结尾。
示例缓冲区:
\\r\\nHost\\r\\n\\r\\n
示例规则:
alert http any any -> any any (http.header_names; content:"|0d 0a|Host|0d 0a|"; sid:1;)
示例以确保 only 主机存在::
alert http any any -> any any (http.header_names; \
content:"|0d 0a|Host|0d 0a 0d 0a|"; sid:1;)
示例以确保 User-Agent 直接在后面 Host ::
alert http any any -> any any (http.header_names; \
content:"|0d 0a|Host|0d 0a|User-Agent|0d 0a|"; sid:1;)
示例以确保 User-Agent 在之后 Host ,但不一定在以下时间之后:
alert http any any -> any any (http.header_names; \
content:"|0d 0a|Host|0d 0a|"; content:"|0a 0d|User-Agent|0d 0a|"; \
distance:-2; sid:1;)
6.13.20. http.request_body¶
与 http.request_body 内容修饰符,可以专门匹配,并且只能在HTTP请求主体上匹配。关键字可以与前面提到的所有内容修饰符(如 distance , offset , nocase , within 等。
实例 http.request_body 在HTTP请求中:

目的示例 http.client_body :

注意:在 libhtp configuration section 通过 request-body-limit 设置。
http.request_body 替换以前的关键字名称: `http_client_body .可以继续+使用以前的名称,但建议将规则转换为使用+新名称。
6.13.21. http.stat_code¶
与 http.stat_code 内容修饰符,可以专门匹配,并且只能在HTTP状态代码缓冲区上匹配。关键字可以与前面提到的所有内容修饰符(如 distance , offset , nocase , within 等。
实例 http.stat_code 在HTTP响应中:

目的示例 http.stat_code :

6.13.22. http.stat_msg¶
与 http.stat_msg 内容修饰符,可以专门匹配,并且只能在HTTP状态消息缓冲区上匹配。关键字可以与前面提到的所有内容修饰符(如 depth , distance , offset , nocase 和 within .
实例 http.stat_msg 在HTTP响应中:

目的示例 http.stat_msg :

6.13.23. http.response_line¶
这个 http.response_line 强制检查整个HTTP响应行。
例子::
alert http any any -> any any (http.response_line; content:"HTTP/1.0 200 OK"; sid:1;)
6.13.24. http.response_body¶
与 http.response_body 内容修饰符,可以在HTTP响应主体上进行特定匹配。关键字可以与前面提到的所有内容修饰符(如 distance , offset , nocase , within 等。
注意:在您的 libhtp configuration section 通过 response-body-limit 设置。
6.13.24.1. 笔记¶
使用
http.response_body类似于之后的内容匹配file_data但它不会永久(除非重置)将检测指针设置到服务器响应主体的开头。也就是说,它不是一个粘性的缓冲液。http.response_body将在gzip解码数据上匹配,就像file_data做。自从
http.response_body与服务器响应匹配,它不能与to_server或from_client流量指令。相应的PCRE修改器:
Q进一步说明
file_data下面部分。
http.response_body 替换以前的关键字名称: `http_server_body .可以继续+使用以前的名称,但建议将规则转换为使用+新名称。
6.13.25. http.server¶
要在HTTP服务器头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (flow:to_client; \
http.server; content:"Microsoft-IIS/6.0"; sid:1;)
6.13.26. http.location¶
要在HTTP位置头上匹配的粘性缓冲区。仅包含标题值。头之后的\r\n不是缓冲区的一部分。
例子::
alert http any any -> any any (flow:to_client; \
http.location; content:"http://www.google.com"; sid:1;)
6.13.27. http.host以及http.host.raw¶
与 http.host 内容修饰符,可以专门匹配,并且只能匹配规范化的主机名。这个 http.host.raw 检查原始主机名。
关键字可以与大多数内容修饰符(如 distance , offset , within 等。
这个 nocase 不再允许使用关键字。请记住,您需要指定一个小写模式。
6.13.27.1. 笔记¶
http.host不包含与主机关联的端口(即。美国广播公司:1234). 端口与主机上的端口或取反以匹配主机http.host.raw.这个
http.host和http.host.raw缓冲区由URI(如果请求中存在完整的URI,如代理请求)或HTTP主机头填充。如果两者都存在,则使用URI。这个
http.host和http.host.raw如果从主机头填充,缓冲区将不包括头名称、冒号或前导空格。也就是说,它们不包括“主机:”。这个
http.host和http.host.raw缓冲区结尾不包括CRLF(0x0D 0x0A)。如果要匹配缓冲区的结尾,请使用相对的“isdataat”或PCRE(尽管PCRE的性能会更差)。这个
http.host缓冲区被规范化为全部小写。内容与
http.host应用于必须全部小写或具有nocase标志集。http.host.raw匹配未规范化的缓冲区,因此匹配将区分大小写(除非nocase设置)。如果一个请求包含多个“主机”头,这些值将在
http.host和http.host.raw缓冲区,按从上到下的顺序排列,每个缓冲区之间有逗号和空格(“,”)。请求示例:
GET /test.html HTTP/1.1 Host: ABC.com Accept: */* Host: efg.net
http.host缓冲区内容:abc.com, efg.net
http.host.raw缓冲区内容:ABC.com, efg.net
相应的PCRE修改器 (
http_host):W相应的PCRE修改器 (
http_raw_host):Z
6.13.28. file_data¶
用 file_data ,检查HTTP响应主体,就像 http.response_body . 这个 file_data 关键字是一个粘性缓冲区。
例子::
alert http any any -> any any (file_data; content:"abc"; content:"xyz";)

这个 file_data 关键字影响以下所有内容匹配,直到 pkt_data 遇到关键字或关键字到达规则结尾。这使得它成为将许多内容匹配应用到HTTP响应主体的一个有用的快捷方式,从而无需单独修改每个内容匹配。
由于HTTP响应的主体可能非常大,因此将以较小的块对其进行检查。
在您的 libhtp configuration section 通过 response-body-limit 设置。
如果HTTP主体是用“deflate”或“lzma”压缩的闪存文件,则可以对其进行解压缩,并且 file_data 可以匹配解压缩数据。必须在下启用闪存解压缩 libhtp 配置:
# Decompress SWF files.
# 2 types: 'deflate', 'lzma', 'both' will decompress deflate and lzma
# compress-depth:
# Specifies the maximum amount of data to decompress,
# set 0 for unlimited.
# decompress-depth:
# Specifies the maximum amount of decompressed data to obtain,
# set 0 for unlimited.
swf-decompression:
enabled: yes
type: both
compress-depth: 0
decompress-depth: 0
6.13.28.1. 笔记¶
如果HTTP主体正在使用gzip或deflate,
file_data将匹配已解压缩的数据。否定匹配受分块检查的影响。例如,“内容:!”<html“;”无法在第一个块上匹配,但可能在第二个块上匹配。要避免这种情况,请使用深度设置。深度设置会考虑到车身尺寸。假设
response-body-minimal-inspect-size大于1K,'内容:!'<html;depth:1024;'只能在第一个检查的块中缺少模式“<html”时匹配。file_data也可以与SMTP一起使用