6.7. 有效载荷关键字¶
有效负载关键字检查包或流的有效负载的内容。
6.7.1. 内容¶
内容关键字在签名中非常重要。在引号之间,你可以写上你希望签名匹配的内容。最简单的内容格式是:
content: "............";
可以在签名中使用多个内容。
内容按字节匹配。一个字节有256个不同的值(0-255)。您可以匹配所有字符;从A到Z,大写和小写,以及所有特殊符号。但并非所有字节都是可打印字符。对于这些字节,使用十六进制符号。许多编程语言使用0x00作为表示法,其中0x表示它涉及二进制值,但是规则语言使用 |00| 作为记号。这种符号也可以用于可打印字符。
例子::
|61| is a
|61 61| is aa
|41| is A
|21| is !
|0D| is carriage return
|0A| is line feed
内容中有一些字符不能使用,因为它们在签名中已经很重要。为了匹配这些字符,您应该使用十六进制符号。这些是:
" |22|
; |3B|
: |3A|
| |7C|
用大写字符编写十六进制符号是一种惯例。
比如写 http:// 在签名的内容中,您应该这样写: content: "http|3A|//"; 如果在签名中使用十六进制符号,请确保始终将其放在管道之间。否则,符号将被视为内容的一部分。
几个例子:
content:"a|0D|bc";
content:"|61 0D 62 63|";
content:"a|0D|b|63|";
可以让签名检查整个负载是否与内容匹配,或者让它检查负载的特定部分。我们稍后再谈。如果不向签名添加任何特殊的内容,它将尝试在有效负载的所有字节中找到匹配项。
丢弃tcp$home-net-any->$external-net-any(msg:“et-trojan-likely-bot-nick-in-irc(usa+..)”;流:已建立,到“服务器”;流位:isset,是“协议”irc; content:"NICK "; PCRE:“/nick. USA. [0-9] 3,/i”;参考:url,doc.emergingthreats.net/2008124;classtype:特洛伊木马活动;sid:2008124;rev:2;)
默认情况下,模式匹配区分大小写。内容必须准确,否则将不匹配。

传说:
可以使用!内容也有例外。
例如::
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"Outdated Firefox on
Windows"; content:"User-Agent|3A| Mozilla/5.0 |28|Windows|3B| ";
content:"Firefox/3."; distance:0; content:!"Firefox/3.6.13";
distance:-10; sid:9000000; rev:1;)
你看 content:!"Firefox/3.6.13"; .这意味着如果使用的火狐版本不是3.6.13,将生成警报。
注解
必须在内容内转义以下字符: ; \ "
6.7.2. 无酶¶
如果不想区分大小写字符,可以使用nocase。关键字nocase是内容修饰符。
此关键字的格式为:
nocase;
必须将其放在要修改的内容之后,例如:
content: "abc"; nocase;
示例nocase:

不影响签名中的其他内容。
6.7.3. 深度¶
深度关键字是绝对内容修饰符。它在内容之后。深度内容修饰符带有一个强制的数字值,例如:
depth:12;
深度后的数字指定从有效负载开始检查的字节数。
例子:

6.7.4. 开始时间¶
这个 startswith 关键字类似于 depth .它不需要参数,必须遵循 content 关键字。它修改了 content 在缓冲区开始处完全匹配。
例子::
content:"GET|20|"; startswith;
startswith 是以下内容的简短符号:
content:"GET|20|"; depth:4; offset:0;
startswith 不能与混合 depth , offset , within 或 distance 同样的模式。
6.7.5. 结束语¶
这个 endswith 关键字类似于 isdataat:!1,relative; .它不需要参数,必须遵循 content 关键字。它修改了 content 在缓冲区的末尾完全匹配。
例子::
content:".php"; endswith;
endswith 是以下内容的简短符号:
content:".php"; isdatat:!1,relative;
endswith 不能与混合 offset , within 或 distance 同样的模式。
6.7.6. 抵消¶
offset关键字指定从哪个字节检查有效负载以查找匹配。例如,偏移量:3;检查第四个字节并进一步检查。

关键字offset和depth可以组合在一起使用。
例如::
content:"def"; offset:3; depth:3;
如果在签名中使用这个,它将检查从第三个字节到第六个字节的有效负载。

6.7.7. 距离¶
关键字“距离”是相对内容修改器。这意味着它表示这个内容关键字和它前面的内容之间的关系。距离在前一场比赛后有其影响。关键字Distance附带一个强制数字值。您给出的距离值确定有效负载中的字节,从该字节将检查是否与上一个匹配匹配。距离仅决定Suricata将从何处开始寻找模式。所以,距离:5;意味着模式可以在上一个匹配之后的任何地方+5字节。为了限制最后一场比赛结束后需要看多远,请使用“内”。
距离示例:

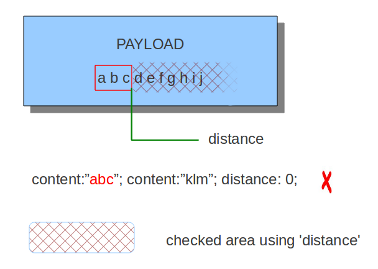

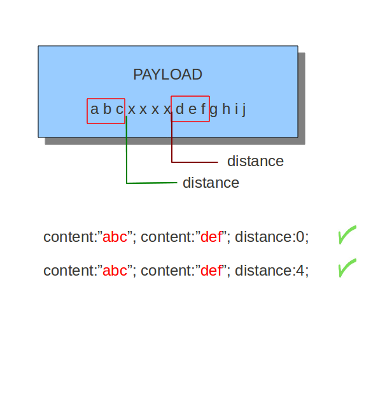
距离也可以是负数。它可以用于检查部分内容相同的匹配项(参见示例),甚至可以检查之前的内容是否完全匹配。但这并不是经常使用的。使用其他关键字也可以获得相同的结果。

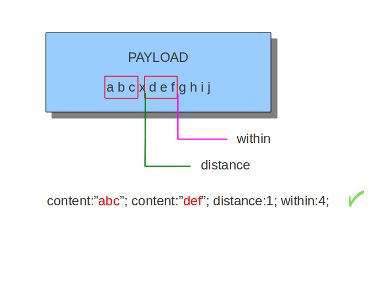
6.7.8. 在内部¶
中的关键字与前面的匹配项相关。中的关键字带有强制数字值。使用within确保只有当内容与设置字节数内的有效负载匹配时才有匹配。内不能为0(零)
例子:

内匹配示例:

第二个内容必须在第一个内容的“3”之内。
如前所述,距离和范围可以很好地结合在一个签名中。如果您希望Suricata检查有效负载的特定部分是否匹配,请在中使用。

6.7.9. 原始字节数¶
rawbytes关键字没有任何影响,但包含在其中是为了与使用它的签名兼容,例如与Snort一起使用的签名。
6.7.10. ISdataat公司¶
is data at关键字的目的是查看负载的特定部分是否仍有数据。关键字以一个数字(位置)开头,然后是可选的,后跟以逗号分隔的“relative”和选项rawbytes。您可以使用“relative”这个词来知道负载中相对于最后一个匹配的特定部分是否还有数据。
因此,您可以使用这两个示例:
isdataat:512;
isdataat:50, relative;
第一个示例说明了搜索有效负载字节512的签名。第二个示例说明了在最后一次匹配之后搜索字节50的签名。
你也可以用负号(!)在ISdataat之前。

6.7.11. 贝斯¶
使用bsize关键字,可以匹配缓冲区的长度。这增加了内容匹配的精确性,以前可以用isdataat完成。
格式::
bsize:<number>;
规则中的bsize示例:
alert dns any any->any(消息:“test bsize rule”;dns.查询;内容:”谷歌"; B尺寸:10;sid:123;版次:1;)
6.7.12. 尺寸¶
使用dsize关键字,您可以匹配数据包有效负载的大小。例如,您可以使用关键字查找等于某个n的异常有效负载大小,即‘dsize:n’不等于‘dsize:!n’小于‘dsize:<n’或大于‘dsize:>n’这在检测缓冲区溢出时可能很方便。
格式::
dsize:[<>!]number; || dsize:min<>max;
规则中的dsize示例:
ALERT UDP$EXTERNAL_NET ANY->$HOME_NET 65535(消息:“GPL删除利用局域网管理套件警报服务缓冲区溢出”; dsize:>268; 参考文献:Bugtraq,23483;参考文献:CVE2007-1674年;classtype:ATTENTED-ADMIN;SID:100000928;rev:1;)alert TCP$EXTERNAL_NET ANY->$HOME_NET8081(消息:“Example Negation”; dsize:!10; SID:123;版本:1;)
6.7.13. byte_test¶
这个 byte_test 关键字提取 <num of bytes> 并执行所选的操作 <operator> 相对于 <test value> 在一个特定的 <offset> . 这个 <bitmask value> 应用于提取的字节(在应用运算符之前),最后的结果将右移一位 0 在 <bitmask value> .
格式::
byte_test:<num of bytes>, [!]<operator>, <test value>, <offset> [,relative] \
[,<endian>][, string, <num type>][, dce][, bitmask <bitmask value>];
<num of bytes> |
从要转换的数据包中选择的字节数 |
<operator> |
|
<值> |
用于测试转换值的值 [接受十六进制或十进制] |
<偏移量> |
有效负载的字节数 |
[相对的] |
相对于上一个内容匹配的偏移量 |
[字节存储次序] |
正在读取的数字类型:-大(最低地址的最高有效字节)-小(最高地址的最高有效字节) |
[一串] <num> |
|
[dce] |
允许DCE模块确定字节顺序 |
[位掩码] |
对转换的字节应用和运算符 |
例子::
alert tcp any any -> any any \
(msg:"Byte_Test Example - Num = Value"; \
content:"|00 01 00 02|"; byte_test:2,=,0x01;)
alert tcp any any -> any any \
(msg:"Byte_Test Example - Num = Value relative to content"; \
content:"|00 01 00 02|"; byte_test:2,=,0x03,relative;)
alert tcp any any -> any any \
(msg:"Byte_Test Example - Num != Value"; content:"|00 01 00 02|"; \
byte_test:2,!=,0x06;)
alert tcp any any -> any any \
(msg:"Byte_Test Example - Detect Large Values"; content:"|00 01 00 02|"; \
byte_test:2,>,1000,relative;)
alert tcp any any -> any any \
(msg:"Byte_Test Example - Lowest bit is set"; \
content:"|00 01 00 02|"; byte_test:2,&,0x01,relative;)
alert tcp any any -> any any (msg:"Byte_Test Example - Compare to String"; \
content:"foobar"; byte_test:4,=,1337,1,relative,string,dec;)
6.7.14. byte_math¶
这个 byte_math keyword添加对具有现有变量或指定值的提取值执行数学运算的功能。
什么时候? relative 是包含的,必须有一个 content 或 pcre 匹配。
结果可以存储在结果变量中,并由规则后面的其他规则选项引用。
关键字 |
修饰语 |
|---|---|
内容 |
偏移,深度,距离,范围 |
byte_test |
偏移,值 |
byte_jump |
抵消 |
ISdataat公司 |
抵消 |
格式::
byte_math:bytes <num of bytes>, offset <offset>, oper <operator>, rvalue <rvalue>, \
result <result_var> [, relative] [, endian <endian>] [, string <number-type>] \
[, dce] [, bitmask <value>];
<num of bytes> |
从数据包中选择的字节数 |
<偏移量> |
有效负载的字节数 |
运算符<运算符> |
要执行的数学运算:+,-, * , /, <<, >> |
r值<r值> |
用于执行数学运算的值 |
结果<结果变量> |
计算值的存储位置 |
[相对的] |
相对于上一个内容匹配的偏移量 |
[endian <type>] |
|
[string <num_type>] |
|
[dce] |
允许DCE模块确定字节顺序 |
[位掩码] <值> |
AND运算符将应用于提取的值,结果将右移位数等于掩码中尾随零的数量 |
例子::
alert tcp any any -> any any \
(msg:"Testing bytemath_body"; \
content:"|00 04 93 F3|"; \
content:"|00 00 00 07|"; distance:4; within:4; \
byte_math:bytes 4, offset 0, oper +, rvalue \
248, result var, relative;)
alert udp any any -> any any \
(byte_extract: 1, 0, extracted_val, relative; \
byte_math: bytes 1, offset 1, oper +, rvalue extracted_val, result var; \
byte_test: 2, =, var, 13; \
msg:"Byte extract and byte math with byte test verification";)
6.7.15. byte_jump¶
这个 byte_jump 关键字允许选择 <num of bytes> 从一个 <offset> 并将检测指针移动到该位置。然后,内容匹配将基于新位置。
格式::
byte_jump:<num of bytes>, <offset> [, relative][, multiplier <mult_value>] \
[, <endian>][, string, <num_type>][, align][, from_beginning][, from_end] \
[, post_offset <value>][, dce][, bitmask <value>];
<num of bytes> |
从要转换的数据包中选择的字节数 |
<偏移量> |
有效负载的字节数 |
[相对的] |
相对于上一个内容匹配的偏移量 |
[乘数] <值> |
将转换后的字节乘以<value> |
[字节存储次序] |
|
[一串] <num_type> |
|
[排列] |
将数字舍入到下一个32位边界 |
[from_beginning] |
从包的开头向前跳,而不是在设置检测指针的位置 |
[from_end] |
跳转将从有效载荷的末尾开始,而不是在设置检测点的位置开始。 |
[post_offset] <值> |
执行跳转操作后,它将跳转由<value> |
[dce] |
允许DCE模块确定字节顺序 |
[位掩码] <值> |
And运算符将由<value>和转换的字节应用,然后执行跳转操作。 |
例子::
alert tcp any any -> any any \
(msg:"Byte_Jump Example"; \
content:"Alice"; byte_jump:2,0; content:"Bob";)
alert tcp any any -> any any \
(msg:"Byte_Jump Multiple Jumps"; \
byte_jump:2,0; byte_jump:2,0,relative; content:"foobar"; distance:0; within:6;)
alert tcp any any -> any any \
(msg:"Byte_Jump From the End -8 Bytes"; \
byte_jump:0,0, from_end, post_offset -8; \
content:"|6c 33 33 74|"; distance:0 within:4;)
6.7.16. byte_extract¶
这个 byte_extract 关键字提取 <num of bytes> 在一个特定的 <offset> 把它储存在 <var_name> .价值 <var_name> 可以在任何以数字为选项的修饰符中使用, byte_test 它可以用作一个值。
格式::
byte_extract:<num of bytes>, <offset>, <var_name>, [,relative] [,multiplier <mult-value>] \
[,<endian>] [, dce] [, string [, <num_type>] [, align <align-value];
<num of bytes> |
从要提取的数据包中选择的字节数 |
<偏移量> |
有效负载的字节数 |
<var_name> |
要在其中存储值的变量的名称 |
[相对的] |
相对于上一个内容匹配的偏移量 |
乘数<值> |
在存储之前,将提取的字节乘以<mult value> |
[字节存储次序] |
正在读取的数字类型:-大(最低地址的最高有效字节)-小(最高地址的最高有效字节) |
[一串] <num> |
|
[dce] |
允许DCE模块确定字节顺序 |
对齐<align value> |
将提取的值取整到下一个<align value>字节边界后乘法(如果有);<align value>可以是2或4 |
关键字 |
修饰语 |
|---|---|
内容 |
偏移,深度,距离,范围 |
byte_test |
偏移,值 |
byte_math |
R值 |
byte_jump |
抵消 |
ISdataat公司 |
抵消 |
例子::
alert tcp any any -> any any \
(msg:"Byte_Extract Example Using distance"; \
content:"Alice"; byte_extract:2,0,size; content:"Bob"; distance:size; within:3; sid:1;)
alert tcp any any -> any any \
(msg:"Byte_Extract Example Using within"; \
flow:established,to_server; content:"|00 FF|"; \
byte_extract:1,0,len,relative; content:"|5c 00|"; distance:2; within:len; sid:2;)
alert tcp any any -> any any \
(msg:"Byte_Extract Example Comparing Bytes"; \
flow:established,to_server; content:"|00 FF|"; \
byte_extract:2,0,cmp_ver,relative; content:"FooBar"; distance:0; byte_test:2,=,cmp_ver,0; sid:3;)
6.7.17. RPC¶
rpc关键字可用于在sunrpc调用中匹配rpc过程号和rpc版本。
您可以使用通配符修改关键字,用*定义的通配符可以匹配所有版本号和/或过程号。
rpc(远程过程调用)是允许计算机程序在另一台计算机(或地址空间)上执行过程的应用程序。用于进程间通信。参见http://en.wikipedia.org/wiki/inter-process_communication
格式::
rpc:<application number>, [<version number>|*], [<procedure number>|*]>;
规则中的rpc关键字示例:
警告udp$external_net any->$home_net 111(msg:“rpc portmap request yppasswdd”; rpc:100009,*,*; 参考:Bugtraq,2763;ClassType:rpc portmap decode;sid:1296;Rev:4;)
6.7.18. 代替¶
替换内容修饰符只能在IPS中使用。它调整网络流量。它将以下内容(“abc”)更改为另一个(“def”),请参见示例:

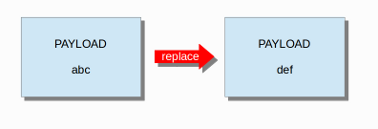
替换修饰符必须包含与其替换的内容相同的字符。它只能与单个数据包一起使用。它不适用于 标准化缓冲区 类似于HTTP URI或重组流中的内容匹配。
校验和将由suricata重新计算,并在使用replace关键字后进行更改。
6.7.19. PCRE(与Perl兼容的正则表达式)¶
关键字pcre与正则表达式上的特定项匹配。有关正则表达式的更多信息,请访问http://en.wikipedia.org/wiki/regular_expression。
然而,PCRE的复杂性带来了很高的价格:它对性能有负面影响。因此,为了减少对PCRE的经常检查,PCRE主要与“内容”结合使用。在这种情况下,必须先匹配内容,然后才能检查PCRE。
PCRE格式:
pcre:"/<regex>/opts";
PCRE示例。在本例中,如果有效负载包含以下六个数字,则会出现匹配:
pcre:"/[0-9]{6}/";
签名中的PCRE示例:
丢弃tcp$home_net any->$external_net any(msg:“et-trojan-likely-bot-nick in irc(usa+..)”;流:已建立,到服务器;流位:isset,is_-proto_-irc;内容:“nick”; pcre:"/NICK .*USA.*[0-9]{{3,}}/i"; 参考:url,doc.emergingthreats.net/2008124;分类类型:特洛伊木马活动;sid:2008124;版本:2;)
PCRE的一些特性可以修改:
默认情况下,PCRE区分大小写。
这个。(DOT)是regex的一部分。除了换行符外,每个字节都匹配。
默认情况下,有效载荷将作为一条线进行检查。
这些质量可以用以下字符修改:
i pcre is case insensitive
s pcre does check newline characters
m can make one line (of the payload) count as two lines
这些选项是与Perl兼容的修饰符。要使用这些修饰符,应该在regex后面将它们添加到pcre。这样地::
pcre: "/<regex>/i";
PCRE兼容修改器
有一些PCRE兼容的修改器可以改变PCRE的质量。这些是:
A:模式必须在缓冲区的开头匹配。(在PCRE中,^类似于a。)E:忽略缓冲区/负载末尾的换行符。G:转化贪婪。
注解
必须在内容内转义以下字符: ; \ "
6.7.19.1. 苏里塔修饰符¶
Suricata有自己的特定PCRE修改器。这些是:
R:相对于上一个模式匹配匹配。与距离相似:0;U:使PCRE与规范化的URI匹配。它在uri_缓冲区上匹配,就像uri content和content与http_uri组合一样。u可以与/r组合。请注意,r与上一个匹配项相关,因此这两个匹配项都必须在http uri缓冲区中。了解更多信息 HTTP URI Normalization .




I:使PCRE与HTTP原始URI匹配。它与http_raw_uri在同一个缓冲区上匹配。我可以与/r结合使用。请注意,r与前一个匹配项相关,因此这两个匹配项都必须在HTTP原始URI缓冲区中。了解更多信息 HTTP URI Normalization .P:使PCRE在HTTP-请求主体上匹配。因此,它与HTTP客户机主体在同一个缓冲区上匹配。p可以与/r组合。请注意,r与前一个匹配项相关,因此这两个匹配项都必须在HTTP请求正文中。Q:使PCRE与HTTP-响应主体匹配。因此,它与HTTP服务器主体在同一个缓冲区上匹配。q可以与/r组合。请注意,r与前一个匹配项相关,因此这两个匹配项都必须位于HTTP响应正文中。H:使PCRE在HTTP头上匹配。h可以与/r组合。请注意,r与上一个匹配项相关,因此这两个匹配项都必须位于HTTP头体中。D:使PCRE与未规范化的头匹配。因此,它与http_raw_头在同一个缓冲区上匹配。d可以与/r组合。请注意,r与上一个匹配项相关,因此这两个匹配项都必须位于HTTP原始头中。M:使PCRE与请求方法匹配。因此,它与http_方法在同一个缓冲区上匹配。m可以与/r组合。请注意,r与前一个匹配项相关,因此两个匹配项都必须在HTTP方法缓冲区中。C:使PCRE与HTTP cookie匹配。因此,它与http_cookie在同一个缓冲区上匹配。C可以与/R组合。请注意,R与上一个匹配项相关,因此这两个匹配项都必须在HTTP cookie缓冲区中。S:使PCRE与HTTP stat代码匹配。因此,它与http_stat_代码在同一个缓冲区上匹配。s可以与/r组合。请注意,r与前一个匹配项相关,因此这两个匹配项都必须在http stat代码缓冲区中。Y:使pcre与http stat msg匹配。因此,它与http_stat_msg在同一个缓冲区上匹配。y可以与/r组合。请注意,r与上一个匹配项相关,因此两个匹配项都必须在http stat msg缓冲区中。B:您可以在签名中遇到B,但这只是为了兼容性。因此,Suricata不使用B,但支持它,因此不会导致错误。O:覆盖配置的PCRE匹配限制。V:使PCRE与HTTP用户代理匹配。因此,它与HTTP用户代理在同一个缓冲区上匹配。v可以与/r组合。请注意,r与前一个匹配项相关,因此这两个匹配项都必须在HTTP用户代理缓冲区中。W:使PCRE在HTTP主机上匹配。因此,它与http_主机在同一个缓冲区上匹配。w可以与/r组合。请注意,r与前一个匹配项相关,因此两个匹配项都必须在HTTP主机缓冲区中。
6.8. 从PCRE1到PCRE2的更改¶
从PCRE1升级到PCRE2会更改某些PCRE表达式的行为。
\I是PCRE1中的有效pcre,带有无用的转义,因此等效于I,但在PCRE2中不再是这样。除了我之外,还有其他角色表现出这种模式[\d-a]是PCRE1中的有效PCRE,可以是数字、破折号或字符a,但现在必须使用PCRE2将破折号转义为[\d\-a]以获得相同的行为pcre2_substring_copy_bynumber现在返回错误PCRE2_ERROR_UNSET而不是pcre_copy_substring不返回错误并提供空字符串。如果某些用例的行为不再是预期的行为,请让我们知道。