机器学习地图的可靠性
访问量: 294 次浏览
机器学习技术不仅在正常生活中变得越来越普遍,
在研究中也越来越普遍。在生态学方面,
研究人员越来越多地努力利用数据的力量来预测和估计随着气候
变化和许多其他人为因素影响我们的星球,环境将如何变化。
虽然这通常是积极的,但危险在于这种机器驱动的地图可能
并不总是能讲述准确的故事。创建有效的机器学习地图需要
仔细的尽职调查并密切关注科学过程。
使用机器学习绘制生态数据的挑战
空间衍生地图的局限性是显而易见的,特别是随着越来越多的
研究试图创建全球尺度的地图,以帮助做出决策和了解星球。
例如,最近关注全球树木恢复潜力、
全球土壤线虫丰度或全球土壤图的工作就是一些例子。
特别是对于在某些区域具有高数据聚类但在其他区域稀疏的数据集,
已经遇到了问题。研究人员尝试使用空间交叉验证技术来验证结果,
但是当输入训练和验证数据的聚类大多局限于有限区域时,
这证明是困难的甚至是徒劳的。
虽然空间派生的机器学习地图(例如使用流行的随机森林技术的地图)
可能会显示看似合理的结果,但使用显示估计的机器学习输出和
输入数据集之间距离的地图可以揭示给定全球尺度的重大问题地图是派生出来的。
机器学习中的区域地理偏差
研究人员,特别是西方国家的研究人员,
经常将他们的数据输入和实地研究集中在北美和欧洲,
这给接受依赖于其他输入区域的全球衍生地图的准确性造成了困难,
即使这样的地图是理想的决策和信息的观点。
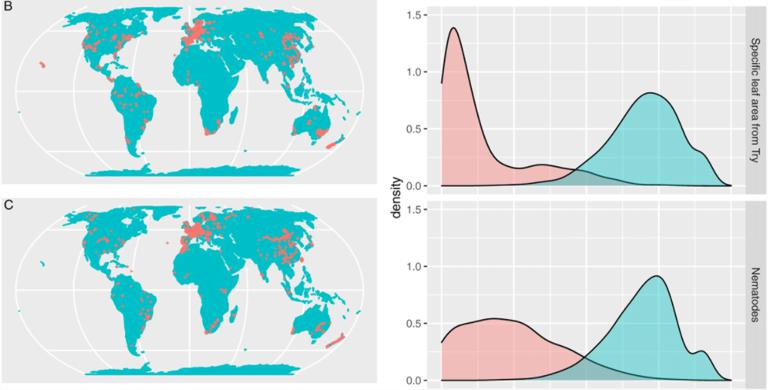
Meyer & Pebesma,2022 年:“三个不同的公开可用数据集的最近邻距离的空间分布和分布(右;粉红色的样本到样本距离,蓝色的预测位置到样本距离):(B)特定叶来自 Try 数据库的区域 24 用于 Moreno-Martinez 等人的全局映射。(2018)25 和 (C) Van den Hoogen 等人编制的线虫数据集。(2019 年)。”
正如最近的一篇文章所指出的,
解决数据过度聚类问题的一种方法可能是创建地图,
从字面上删除或指示预测值与现场收集的数据显着不同的区域,
或者只是删除信息过于稀疏而无法创建可靠的结果为机器派生的
地图获取输入数据的地图。问题在于,
如果地图没有从其预测输出中删除给定的数据稀疏区域,
则可能会误解准确的生态故事,
这可能对我们做出重要的全球规模决策产生负面影响。
机器学习开发生态地图的局限性
其他文章也暗示了使用某些机器学习技术来获取地图的危险。
例如,在一篇使用不同机器学习技术(包括多项逻辑回归、
支持向量机、随机森林和梯度提升树)评估全球湖冰的文章中,
研究人员证明这些方法都可用于生成准确率超过 94% 的地图。
然而,除了随机森林之外,
所有这些技术都容易在超参数上使用交叉验证 k 折技术对其可预测性过于敏感。
映射中的机器学习和数据差距
研究人员还证明,可以通过使用生成对抗网络 (GAN)
提高数据质量和可预测性来改善数据差距。
虽然GAN 以其在创建图像(有时甚至是假图像)方面的适用性而闻名,
但 GAN 也可用于派生数据,
使用两个竞争网络将派生数据集与经验数据集进行比较,
用于机器学习地图的训练。
当派生数据与经验数据一样时,
GAN 模型可用于创建质量与经验数据相似的派生数据。
例如,研究人员表明,GAN 衍生的数据可以改善滑坡敏感性图。
虽然 GAN 在填补数据空白方面确实显示出其科学适用性的潜力,
但仍需要足够的输入数据来创建准确的派生数据。
生态测绘中的机器学习有局限性
虽然来自机器学习的地图越来越多地成为研究人员使用这些地图的结果,
以便让我们更多地了解各种环境现象在全球和区域范围内可能发生的情况,
但危险在于我们用于创建此类地图的输入数据并不总是足够了,
特别是对于远离北美和欧洲的地区。
有一些潜在的解决方法,例如使用 GAN 来帮助解决数据缺陷,
但是在任何给定区域中过度聚类信息可能会使用于估计更多
数据稀疏区域的输出产生偏差。
为观众和其他研究人员提供明确警告的输出应该是在任何使用
机器学习衍生的空间图的研究中给出的输出的一部分。
简单地给出带有结果的地图可能会导致欺骗性的输出,
除非我们开始将不确定性作为输出的一部分。
本文链接 :机器学习地图的可靠性