大Pandas生态系统#
越来越多的人在Pandas的基础上构建包,以满足数据准备、分析和可视化方面的特定需求。这是令人鼓舞的,因为这意味着Pandas不仅帮助用户处理他们的数据任务,还为开发人员提供了一个更好的起点,以构建功能强大、更有针对性的数据工具。创建补充大Pandas功能的库也使大Pandas的发育仍然专注于它的原始需求。
这是一个无穷无尽的项目清单,这些项目建立在Pandas的基础上,以便在PyData空间提供工具。有关依赖Pandas的项目列表,请参阅 Github network dependents for pandas 或 search pypi for pandas 。
我们希望让用户更容易找到这些项目,如果你知道其他重要的项目,你觉得应该在这个名单上,请让我们知道。
数据清理和验证#
Pyjanitor#
Pyjanitor使用方法链接为清理数据提供了一个干净的API。
Pandera#
Pandera提供了一个灵活且富有表现力的API,用于对数据帧执行数据验证,以使数据处理管道更具可读性和健壮性。数据帧包含Pandera在运行时显式验证的信息。这在生产关键型数据管道或可重现的研究环境中很有用。
pandas-path#
从Python3.4开始, pathlib 已包含在Python标准库中。Path对象提供了与文件系统交互的简单且令人愉快的方式。Pandas-Path包通过自定义访问器为Pandas启用Path API .path 。从一系列完整的文件路径中仅获取文件名非常简单 my_files.path.name 。还可以使用其他方便的操作,如联接路径、替换文件扩展名和检查文件是否存在。
统计学与机器学习#
pandas-tfrecords#
轻松地将Pandas数据帧保存到TensorFlow文件记录格式,并将文件记录读取到Pandas文件。
Statsmodels#
StatsModels是著名的 Python “统计和计量经济学类库”,它与Pandas有着长期的特殊关系。StatsModels提供了强大的统计、计量经济学、分析和建模功能,这超出了Pandas的范围。StatsModels利用Pandas对象作为底层数据容器进行计算。
sklearn-pandas#
在您的应用程序中使用Pandas数据帧 scikit-learn ML流水线。
Featuretools#
FeatureTools是建立在Pandas之上的自动化特征工程的Python库。它擅长将时态和关系数据集转换为用于机器学习的特征矩阵,使用可重复使用的特征工程“基元”。用户可以在Python中贡献自己的原语,并与社区的其他成员共享。
Compose#
Compose是一种机器学习工具,用于标记数据和预测工程。它允许您通过将预测问题参数化并将时间驱动的关系数据转换为具有可用于监督学习的截止时间的目标值来构建标记过程。
STUMPY#
StumPy是用于现代时间序列分析的功能强大且可伸缩的Python库。在其核心,stumpy高效地计算一种称为 matrix profile ,它可用于各种时间序列数据挖掘任务。
可视化#
Pandas has its own Styler class for table visualization <user_guide/style.ipynb> _和While pandas also has built-in support for data visualization through charts with matplotlib ,还有许多其他与PANAS兼容的库。
Altair#
Altair是一个用于Python的声明性统计可视化程序库。有了牛郎星,你可以花更多的时间来理解你的数据及其意义。Altair的API简单、友好且一致,并且构建在强大的Vega-Lite JSON规范之上。这种优雅的简单性用最少的代码产生了美丽而有效的可视化效果。牛郎星与PandasDataFrames合作。
Bokeh#
Bokeh是一个Python交互式可视化库,用于原生使用最新Web技术的大型数据集。它的目标是以Protovis/D3的风格提供优雅、简洁的新型图形构建,同时向瘦客户端提供针对大数据的高性能交互。
Pandas-Bokeh 为Bokeh提供高级API,可通过以下方式加载为本地Pandas绘图后端
pd.set_option("plotting.backend", "pandas_bokeh")
它非常类似于matplotlib绘图后端,但提供了基于Web的交互式图表和地图。
Seaborn#
Seborn是一个Python可视化库,基于 matplotlib 。它提供了一个面向数据集的高级界面,用于创建有吸引力的统计图形。Seborn中的绘图功能理解Pandas对象,并在内部利用Pandas分组操作来支持复杂可视化的简洁规范。Seborn还超越了matplotlib和Pandas,可以在绘制、汇总观察数据和可视化统计模型的适合度的同时执行统计估计,以强调数据集中的模式。
plotnine#
哈德利·韦翰的 ggplot2 是R语言的一个基础性探索性可视化包。基于 "The Grammar of Graphics" 它提供了一种强大的、说明性的和极其通用的方法来生成任何类型数据的定制绘图。对其他语言的各种实现都是可用的。对于Python用户来说,一个很好的实现是 has2k1/plotnine 。
IPython vega#
IPython Vega 杠杆作用 Vega 在Jupyter Notebook中创建情节。
Plotly#
Plotly’s Python API 支持交互式图形和网络共享。地图、2D、3D和实时流图使用WebGL和 D3.js 。该类库支持直接从PandasDataFrame进行打印和基于云的协作。用户 matplotlib, ggplot for Python, and Seaborn 可以将图形转换为基于Web的交互式绘图。可以在中绘制图形 IPython Notebooks 、用R或MATLAB编辑、在图形用户界面中修改或嵌入到应用程序和仪表板中。Ploly是免费的,可以无限分享,并拥有 offline ,或 on-premise 私人使用的帐号。
Lux#
Lux 是一个Python库,它通过自动化可视化数据探索过程来方便快捷地对数据进行实验。要使用Lux,只需在Pandas旁边添加额外的进口:
import lux
import pandas as pd
df = pd.read_csv("data.csv")
df # discover interesting insights!
通过打印数据帧,Lux自动 recommends a set of visualizations 这突出了数据框架中有趣的趋势和模式。用户可以利用任何现有的Pandas命令,而无需修改他们的代码,同时能够可视化他们的Pandas数据结构(例如,DataFrame、Series、Index)。Lux还提供了一个 powerful, intuitive language 允许用户创建 Altair , matplotlib ,或 Vega-Lite 可视化,而不必在代码级别进行思考。
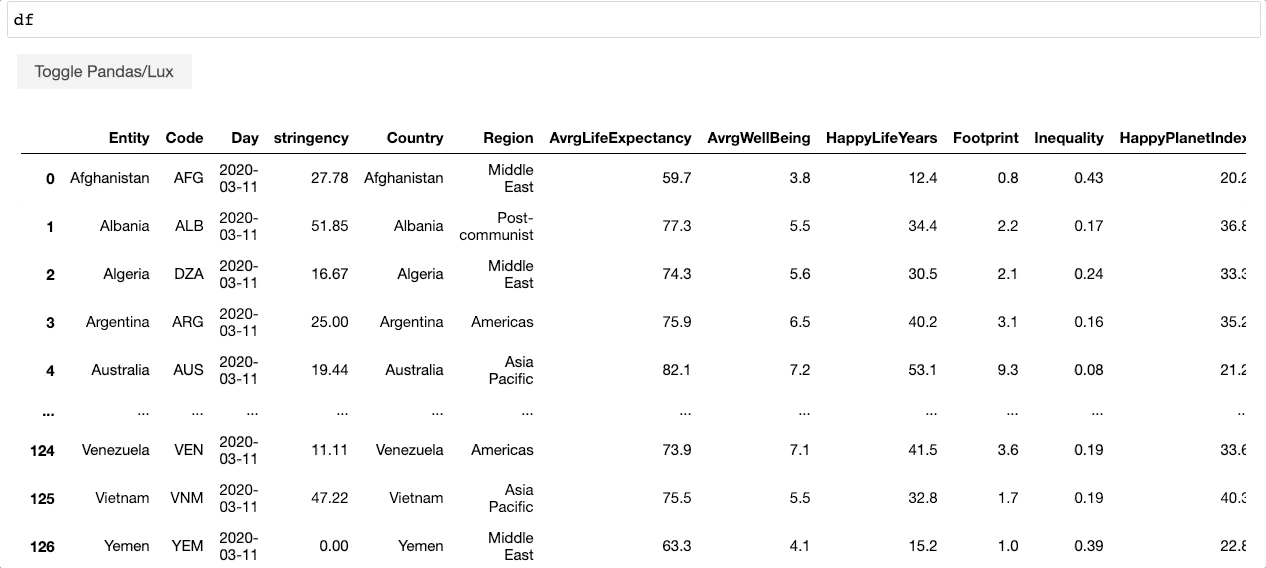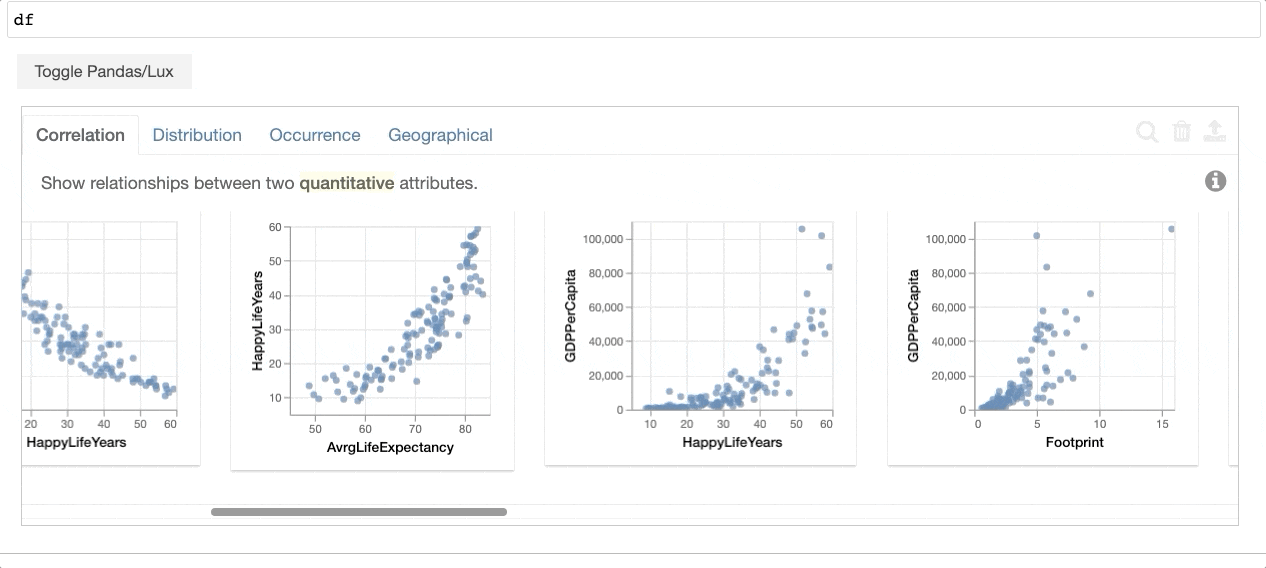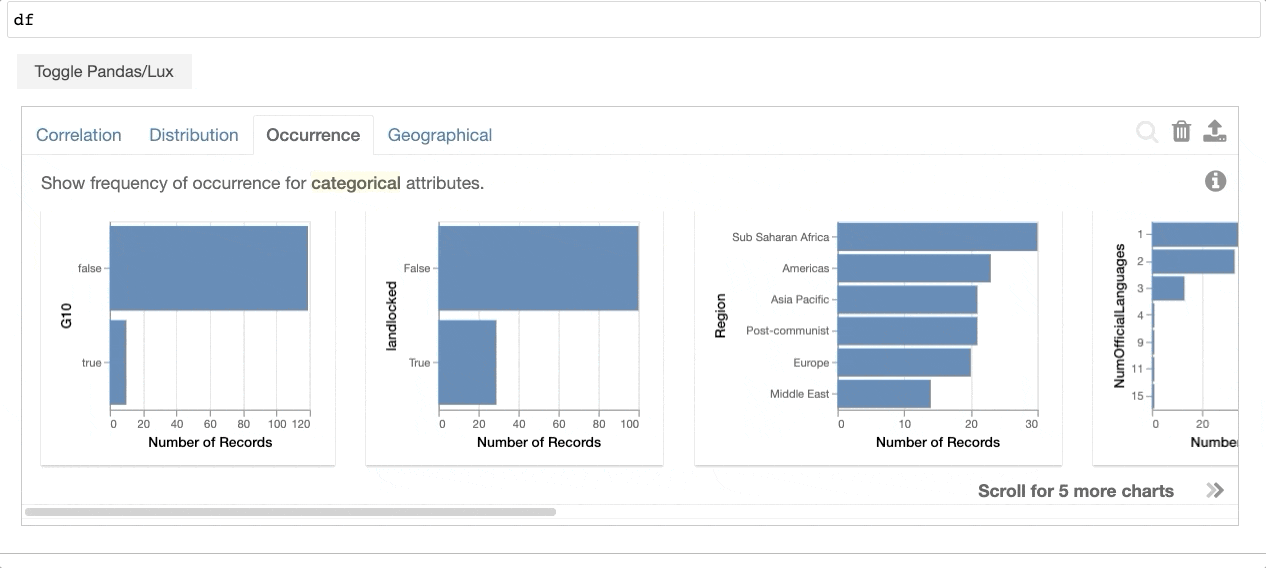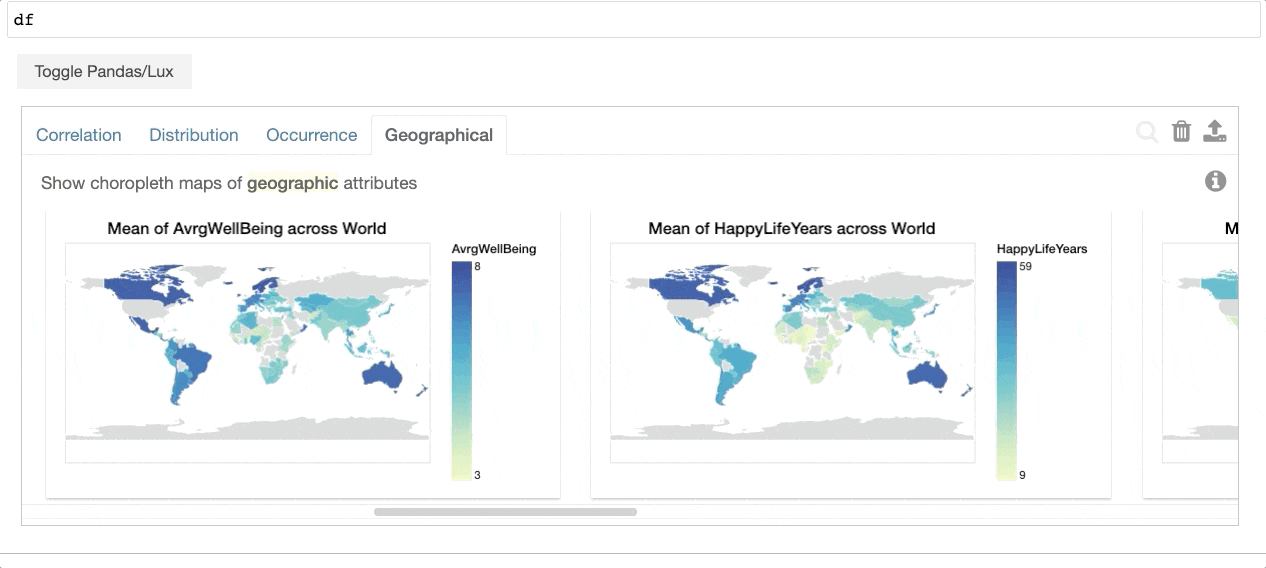{kind=link}
Qtpandas#
从主要的Pandas类库剥离出来的 qtpandas 库支持在PyQt4和PySide应用程序中实现DataFrame可视化和操作。
D-Tale#
D-Tale是一个用于可视化Pandas数据结构的轻量级Web客户端。它提供了一个丰富的电子表格样式的网格,充当了许多PANAS功能(查询、排序、描述、比较...)的包装器。因此,用户可以快速操作他们的数据。还有一个使用Ploly Dash的交互式图表构建器,允许用户构建良好的可移植可视化效果。可以使用以下命令调用D-Tale
import dtale
dtale.show(df)
D-Tale与Jupyter笔记本、Python终端、Kaggle和Google Colab无缝集成。下面是一些演示 grid 。
hvplot#
HvPlot是一种用于构建在 HoloViews 。它可以加载为本地Pandas绘制后端,通过
pd.set_option("plotting.backend", "hvplot")
IDE#
IPython#
IPython是一个交互式命令外壳和分布式计算环境。IPython制表符补全功能可与Pandas方法和DataFrame列等属性一起使用。
Jupyter Notebook / Jupyter Lab#
Jupyter Notebook是一个用于创建Jupyter笔记本的Web应用程序。Jupyter笔记本是一种JSON文档,其中包含输入/输出单元格的有序列表,其中可以包含代码、文本、数学、曲线图和富媒体。Jupyter笔记本电脑可以通过网络界面中的下载方式转换为多种开放式标准输出格式(HTML、HTML演示文稿幻灯片、LaTeX、PDF、ReStructiredText、Markdown、Python),并且 jupyter convert 在一个贝壳里。
Pandas DataFrames实现 _repr_html_ 和 _repr_latex Jupyter Notebook用来显示(缩写)HTML或LaTeX表格的方法。LaTeX输出已正确转义。(注意:HTML表格可能与非HTMLJupyter输出格式兼容,也可能不兼容。)
看见 Options and Settings 和 Available Options 对于大Pandas来说 display. 设置。
Quantopian/qgrid#
Qgrid是用SlickGrid构建的“用于在IPython Notebook中对DataFrame进行排序和过滤的交互式网格”。
Spyder#
Spyder是一款基于PyQt的跨平台集成开发环境,它将软件开发工具的编辑、分析、调试和剖析功能与科学环境(如MatLab或RStudio)的数据探索、交互执行、深度检查和丰富的可视化功能结合在一起。
它的 Variable Explorer 允许用户查看、操作和编辑Pandas Index , Series ,以及 DataFrame 像“电子表格”一样的对象,包括复制和修改值、排序、显示“热图”、转换数据类型等。Pandas对象还可以重命名、复制、添加新列、复制/粘贴到剪贴板(作为TSV)以及保存到文件或从文件加载。Spyder还可以通过复杂的导入向导将数据从各种纯文本和二进制文件或剪贴板导入到新的PandasDataFrame中。
大多数Pandas类、方法和数据属性都可以在Spyder中自动完成 Editor 和 IPython Console ,和Spyder的 Help pane 可以使用Sphinx自动和按需以富文本形式检索和呈现Pandas对象上的Numpydoc文档。
API#
pandas-datareader#
pandas-datareader 是用于Pandas的远程数据访问库(PYPI: pandas-datareader). It is based on functionality that was located in pandas.io.data and pandas.io.wb but was split off in v0.19. See more in the pandas-datareader docs:
以下数据馈送可用:
谷歌财经
Tiingo
晨星
IEX
罗宾汉
谜团
问答
FRED
法玛/法语
世界银行
OECD
欧盟统计局
TSP基金数据
纳斯达克交易商符号定义
Stooq指数数据
MOEX数据
Quandl/Python#
Quandl API for Python包装了Quandl rest API,以返回带有时间序列索引的PandasDataFrame。
Pydatastream#
PyDatastream是到 Refinitiv Datastream (DWS) REST API返回带有财务数据的索引PandasDataFrame。此程序包需要此接口的有效凭据(非免费)。
pandaSDMX#
PandaSDMX是一个用于检索和获取统计数据和元数据的库 SDMX 2.1,这是一种被统计局、中央银行和国际组织等机构广泛使用的ISO标准。PandaSDMX可以将数据集和相关的结构元数据(包括数据流、代码列表和数据结构定义)公开为Pandas Series或多索引DataFrame。
fredapi#
Fredapi是到 Federal Reserve Economic Data (FRED) 由圣路易斯联邦储备银行提供。它与FRED数据库和包含时间点数据(即历史数据修订)的Alfred数据库一起使用。Fredapi为Fred HTTP API提供了一个使用Python语言的包装器,还提供了几种方便的方法来解析和分析来自Alfred的时间点数据。Fredapi利用Pandas并以Series或DataFrame形式返回数据。本模块需要一个FRED API密钥,您可以在FRED网站上免费获得。
dataframe_sql#
dataframe_sql 是一个Python包,可以将SQL语法直接转换为对PandasDataFrame的操作。当从数据库迁移到使用PANAS时,或者对于更习惯于使用SQL寻找与PANDA交互的方法的用户来说,这很有用。
特定于域#
Geopandas#
Geopandas将Pandas数据对象扩展为包括支持几何运算的地理信息。如果你的工作需要地图和地理坐标,而且你喜欢Pandas,你应该仔细看看地质Pandas。
staircase#
STRELCASE是一个数据分析包,建立在Pandas和NumPy的基础上,用于建模和处理数学阶跃函数。它为实数、日期时间和时间增量域上定义的阶跃函数提供了丰富的算术运算、关系运算、逻辑运算、统计运算和聚合。
xarray#
XARRAY通过提供核心Pandas数据结构的N维变体,将Pandas的标签数据能力带到了物理科学中。它的目标是提供一个类似Pandas的、与Pandas兼容的工具包,用于多维阵列的分析,而不是Pandas擅长的表格数据。
IO#
BCPandas#
BCPandas提供从Pandas到Microsoft SQL Server的高性能写入,远远超过本机的性能 df.to_sql 方法。在内部,它使用微软的BCP实用程序,但复杂性完全从最终用户那里抽象出来。经过严格测试,它完全取代了 df.to_sql 。
Deltalake#
Deltalake Python包允许您访问存储在 Delta Lake 无需使用Spark或JVM即可使用原生的Python语言。它提供了 delta_table.to_pyarrow_table().to_pandas() 方法将任何Delta表转换为Pandas数据帧。
核外#
Blaze#
Blaze提供了一个标准API,用于对各种内存和磁盘后端进行计算:NumPy、Pandas、SQLAlChemy、MongoDB、PyTables、PySpark。
Cylon#
Cylon是一个快速、可伸缩的分布式内存并行运行时,具有类似于Python DataFrame API的功能。“核心赛昂”是用C++实现的,使用了ApacheArrow格式来表示内存中的数据。Cron DataFrame API实现了PANDA的大多数核心运算符,如合并、过滤、连接、合并、分组、DROP_DUPLICATES等。这些运算符旨在跨数千个内核工作以扩展应用程序。它可以通过读取Pandas数据或将数据转换为Pandas数据来与PandasDataFrame互操作,这样用户就可以有选择地缩放他们的PandasDataFrame应用程序的一部分。
from pycylon import read_csv, DataFrame, CylonEnv
from pycylon.net import MPIConfig
# Initialize Cylon distributed environment
config: MPIConfig = MPIConfig()
env: CylonEnv = CylonEnv(config=config, distributed=True)
df1: DataFrame = read_csv('/tmp/csv1.csv')
df2: DataFrame = read_csv('/tmp/csv2.csv')
# Using 1000s of cores across the cluster to compute the join
df3: Table = df1.join(other=df2, on=[0], algorithm="hash", env=env)
print(df3)
Dask#
DASK是一个灵活的分析并行计算库。达斯克提供了一种熟悉的 DataFrame 用于核外、并行和分布式计算的接口。
Dask-ML#
DASK-ML支持并行和分布式机器学习,它与现有的机器学习库(如Scikit-Learn、XGBoost和TensorFlow)一起使用。
Ibis#
IBIS提供了一种编写分析代码的标准方法,可以在多个引擎上运行。它有助于弥合本地Python环境(如Pandas)与远程存储和执行系统(如Hadoop组件(如HDFS、Impala、Have、Spark)和SQL数据库(Postgres等)之间的差距。
Koalas#
考拉在阿帕奇Spark上提供了大家熟悉的PandasDataFrame界面。它使用户能够利用一台机器或一群机器上的多核来加速或扩展他们的DataFrame代码。
Modin#
这个 modin.pandas DataFrame是Pandas的并行和分布式临时替代品。这意味着您可以在现有的Pandas代码中使用Modin,也可以在现有的Pandas API中编写新代码。Modin可以利用您的整个计算机或集群来加快和扩展您的Pandas工作负载,包括传统上耗时的任务,如摄取数据 (read_csv , read_excel , read_parquet 等)。
# import pandas as pd
import modin.pandas as pd
df = pd.read_csv("big.csv") # use all your cores!
Odo#
ODO为在不同格式之间移动数据提供了统一的API。它用的是Pandas自己的 read_csv 用于CSV IO,并利用许多现有的包(如PyTables、h5py和pymongo)在非PANDA格式之间移动数据。它的基于图形的方法也可由终端用户扩展,用于定制格式,这些格式对于ODO的核心来说可能太具体了。
Pandarallel#
Pandararis提供了一种简单的方法,只需更改一行代码就可以在所有其他CPU上并行处理您的Pandas操作。如果也显示进度条。
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
# df.apply(func)
df.parallel_apply(func)
Vaex#
越来越多的人在Pandas的基础上构建包,以满足数据准备、分析和可视化方面的特定需求。VAEX是一个用于Out-of-Core DataFrame(类似于PANDA)的Python库,用于可视化和探索大型表格数据集。它可以在N维格网上计算平均值、总和、计数、标准差等统计数据,最高可达10亿(109 )每秒的对象/行数。可视化是使用直方图、密度图和三维体绘制完成的,允许交互探索大数据。VAEX使用内存映射、零内存复制策略和延迟计算来实现最佳性能(不浪费内存)。
vaex.from_pandas
vaex.to_pandas_df
扩展模块数据类型#
Pandas提供了一个接口来定义 extension types 来扩展NumPy的类型系统。以下库实现了该接口,以提供NumPy或Pandas中找不到的类型,它们与Pandas的数据容器一起工作得很好。
Cyberpandas#
CyberPandas提供了用于存储IP地址数组的扩展类型。这些数组可以存储在Pandas的Series和DataFrame中。
Pandas-Genomics#
Pandas-基因组学提供用于处理基因组学数据的扩展类型、扩展数组和扩展访问器
Pint-Pandas#
Pint-Pandas 提供用于存储带单位的数值数组的扩展类型。这些数组可以存储在Pandas的Series和DataFrame中。因此,使用pint的扩展数组的Series和DataFrame列之间的操作是单位感知的。
Text Extensions for Pandas#
Text Extensions for Pandas 提供扩展类型以涵盖用于表示自然语言数据的常见数据结构,以及将流行的自然语言处理库的输出转换为Pandas DataFrame的库集成。
访问者#
提供的项目目录 extension accessors 。这是为了让用户发现新的访问者,以及让库作者协调命名空间。
类库 |
访问者 |
班级 |
描述 |
|---|---|---|---|
|
|
提供使用IP地址的常见操作。 |
|
|
|
提供来自 Altair 类库。 |
|
|
|
为基因组数据的质量控制和分析提供常见操作。 |
|
|
|
提供 pathlib.Path 系列的功能。 |
|
|
|
为数字系列和数据帧提供单位支持。 |
|
|
|
为增强的数据切片提供生成器。 |
|
|
|
提供验证、差异和验收经理。 |
|
|
|
提供Series和DataFrames的物理、逻辑和语义数据类型信息。 |
|
|
|
提供查询、聚合和绘制步骤函数的方法 |
开发工具#
pandas-stubs#
虽然Pandas存储库是部分类型化的,但包本身并不公开此信息以供外部使用。安装Pandas-Stub以启用Pandas API的基本类型复盖。
通过阅读了解更多信息 GH14468 , GH26766 , GH28142 。
请参阅上的安装和使用说明 github page 。