11.1. 架构¶
GeoMesa Spark提供了在分布式大规模数据处理引擎上运行地理空间分析作业的功能 Apache Spark 。它为Spark提供了接收和分析存储在GeoMesa数据存储中的地理空间数据的接口。
GeoMesa在几个不同的级别上提供Spark集成。处于最低级别的是 geomesa-spark-jts 模块(请参见 火花JTS ),它包含用户定义的空间类型和函数。该模块可以很容易地包含在想要在Spark中使用几何图形的其他项目中,因为它只依赖于JTS库。
接下来, geomesa-spark-core 模块(请参见 火花芯 )是Spark的扩展,它需要 GeoTools Query 对象作为输入并生成具有弹性的分布式数据集 (RDD S),其中包含SimpleFeature的序列化版本。有多个针对不同类型功能存储的后端可用,包括用于Acumulo、HBase、文件系统、可读文件的后端 GeoMesa转换器 库和任何通用GeoTool DataStore S。
这个 geomesa-spark-sql 模块(请参见 SparkSQL )构建在核心模块之上,以便在 RDD S和 DataFrame S。GeoMesa SparkSQL向下推送来自SQL查询的过滤逻辑并将其转换为GeoTool Query 对象,然后将这些对象传递给 GeoMesaSpark 由GeoMesa Spark Core提供的对象。
最后,提供了用于与Spark PythonAPI集成的绑定。看见 GeoMesa火花源 了解更多细节。
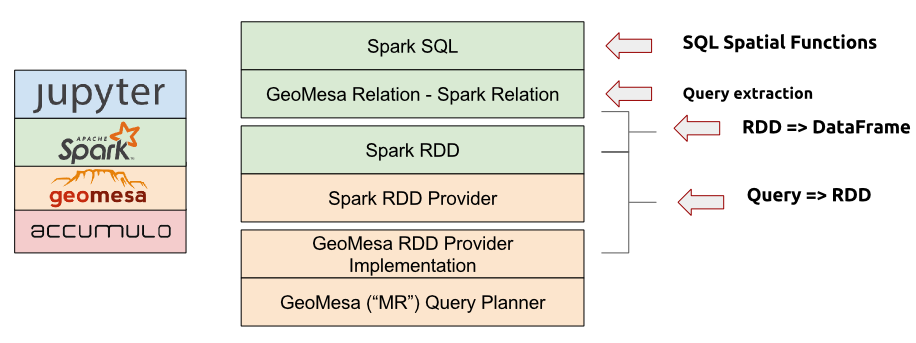
由分布式数据存储组成的堆栈,如Acumulo、GeoMesa、GeoMesa Spark库、Spark和 Jupyter 交互式笔记本应用程序(见上)提供了一个完整的大规模地理空间数据分析平台。
看见 地球台地星火:基本分析 获取有关使用GeoMesa Spark分析数据的教程。