地球台地星火:基本分析¶
本教程将向您展示如何:
将GeoMesa用于 Apache Spark 。
为GeoMesa编写自定义Scala代码以生成直方图和空间密度 GDELT 事件数据。
背景¶
Apache Spark 是一个“用于大规模数据处理的快速通用引擎”。Spark提供了一种称为弹性分布式数据集(RDD)的抽象,它有助于表达转换、筛选器和聚合,并跨分布式资源集高效地执行计算。Spark管理已转换数据块的沿袭,以便在节点出现故障时,Spark可以仅重新启动缺少的块的计算。
GeoMesa支持对存储在GeoMesa中的数据执行Spark作业。您可以使用标准CQL查询并通过传递标准CQL函数来转换数据来初始化Spark RDD。本着必须使用的字数计数映射-归约示例的精神,我们演示了两个关于字数统计的地理空间旋转。首先,按时间分辨率统计特征,计算空间数据的时间序列;其次,按网格单元聚合,快速生成密度图。ApacheSpark使我们能够轻松而简洁地表达这些转换。
先决条件¶
警告
您需要访问Hadoop 2.8 or later 使用纱线和Acumulo进行安装 2.0 or 2.1 数据库。
您需要使用GeoMesa获取GDELT数据。相关说明请参阅 MAP-减少GDELT的摄取 。
您还需要:
a Spark 3.3 distribution
具有适当权限查询您的数据的Acumulo用户
Apache Maven 3.6 or later, and
一个 git 客户端
下面的教程示例假定已经安装并配置了Spark,并且正在运行一个包含Hadoop和Yarn的集群。我们将使用 spark-submit 在集群上运行我们的作业。
设置教程代码¶
克隆geomesa-tutorials项目,并进入 geomesa-examples-spark 目录:
$git克隆https://github.com/geomesa/geomesa-tutorials.git$cd geomesa-教程/geomesa-示例-Spark
备注
本教程中的代码是用 Scala 。
按一年中的日期统计事件¶
你需要服下一些 GDELT 使用GeoMesa将数据导入Acumulo,如中所述 MAP-减少GDELT的摄取 或 全球事件、语言和语调数据库(GDELT) 。
这个 com.example.geomesa.spark.CountByDay 中的类 src/main/scala 目录是一个自包含的例子,可以提交给Spark作为分析的例子。中描述了所使用的库 GeoMesa星火 GeoMesa手册的一章。我们将在下面描述此示例代码。
示例代码¶
首先,我们设置连接参数--您需要修改这些设置以匹配您的集群的配置:
val params = Map(
"accumulo.instance.name" -> "instance",
"accumulo.zookeepers" -> "zoo1,zoo2,zoo3",
"accumulo.user" -> "user",
"accumulo.password" -> "*****",
"accumulo.catalog" -> "geomesa.catalog",
"geomesa.security.auths" -> "USER,ADMIN")
我们还定义了一个ECQL过滤器,用于从GeoMesa Acumulo数据存储中选择GDELT数据的子集。的价值 during 还应进行编辑,以匹配您已摄取的GDELT数据范围。
// Define a GeoTools Filter here
val typeName = "gdelt"
val geom = "geom"
val date = "dtg"
val bbox = "-80, 35, -79, 36"
val during = "2014-01-01T00:00:00.000Z/2014-01-31T12:00:00.000Z"
val filter = s"bbox($geom, $bbox) AND $date during $during"
在 main() 方法,我们为该类创建一个 AccumuloDataStore :
// Get a handle to the data store
val ds = DataStoreFinder.getDataStore(params).asInstanceOf[AccumuloDataStore]
并创建GeoTool Filter 来自ECQL:
// Construct a CQL query to filter by bounding box
val q = new Query(typeName, ECQL.toFilter(filter))
我们设立了Spark:
// Configure Spark
val conf = new SparkConf().setAppName("testSpark")
val sc = SparkContext.getOrCreate(conf)
这个 GeoMesaSpark 对象提供的 geomesa-spark-core 模块使用SPI查找 SpatialRDDProvider 界面。在本例中,这将是 AccumuloSpatialRDDProvider 从 geomesa-accumulo-spark 模块,它将使用提供的参数连接到Acumulo。(有关此界面的详细信息,请参阅 火花芯 在GeoMesa手册中。)
// Get the appropriate spatial RDD provider
val spatialRDDProvider = GeoMesaSpark(params)
接下来,初始化一个 RDD[SimpleFeature] 使用此提供程序:
// Get an RDD[SimpleFeature] from the spatial RDD provider
val queryRDD = spatialRDDProvider.rdd(new Configuration, sc, params, q)
最后,我们构建了我们的计算,它由提取 SQLDATE 从每一个 SimpleFeature 并将其截断到当天的分辨率。
val dayAndFeature = queryRDD.mapPartitions { iter =>
val df = new SimpleDateFormat("yyyyMMdd")
val ff = CommonFactoryFinder.getFilterFactory2
val exp = ff.property("SQLDATE")
iter.map { f => (df.format(exp.evaluate(f).asInstanceOf[java.util.Date]), f) }
}
然后,我们按天分组,并对每组中的事件数量进行计数。
val countByDay = dayAndFeature.map( x => (x._1, 1)).reduceByKey(_ + _)
countByDay.collect().foreach(println)
运行教程代码¶
如果您尚未这样做,请修改 CountByDay.scala 类,以便参数映射指向您的云实例,并确保 filter 覆盖您的GDELT数据的有效范围。
构建(或重建)JAR。这个示例JAR带有阴影,将包含在Spark中运行适当分析所需的所有JAR。
$ mvn clean install
我们可以使用以下命令将作业提交到Yarn集群 spark-submit :
$ /path/to/spark/bin/spark-submit --master yarn \
--class com.example.geomesa.spark.CountByDay \
target/geomesa-examples-spark-$VERSION.jar
备注
请注意 $VERSION 是geomesa-tutorials版本,而不是GeoMesa版本。
或者,您也可以在本地运行Spark作业,方法是设置 --master 'local[*] 。您应该会看到很多Spark日志记录,然后是计数:
(20140117,57)
(20140120,38)
(20140113,407)
...
空间事件密度的并行计算¶
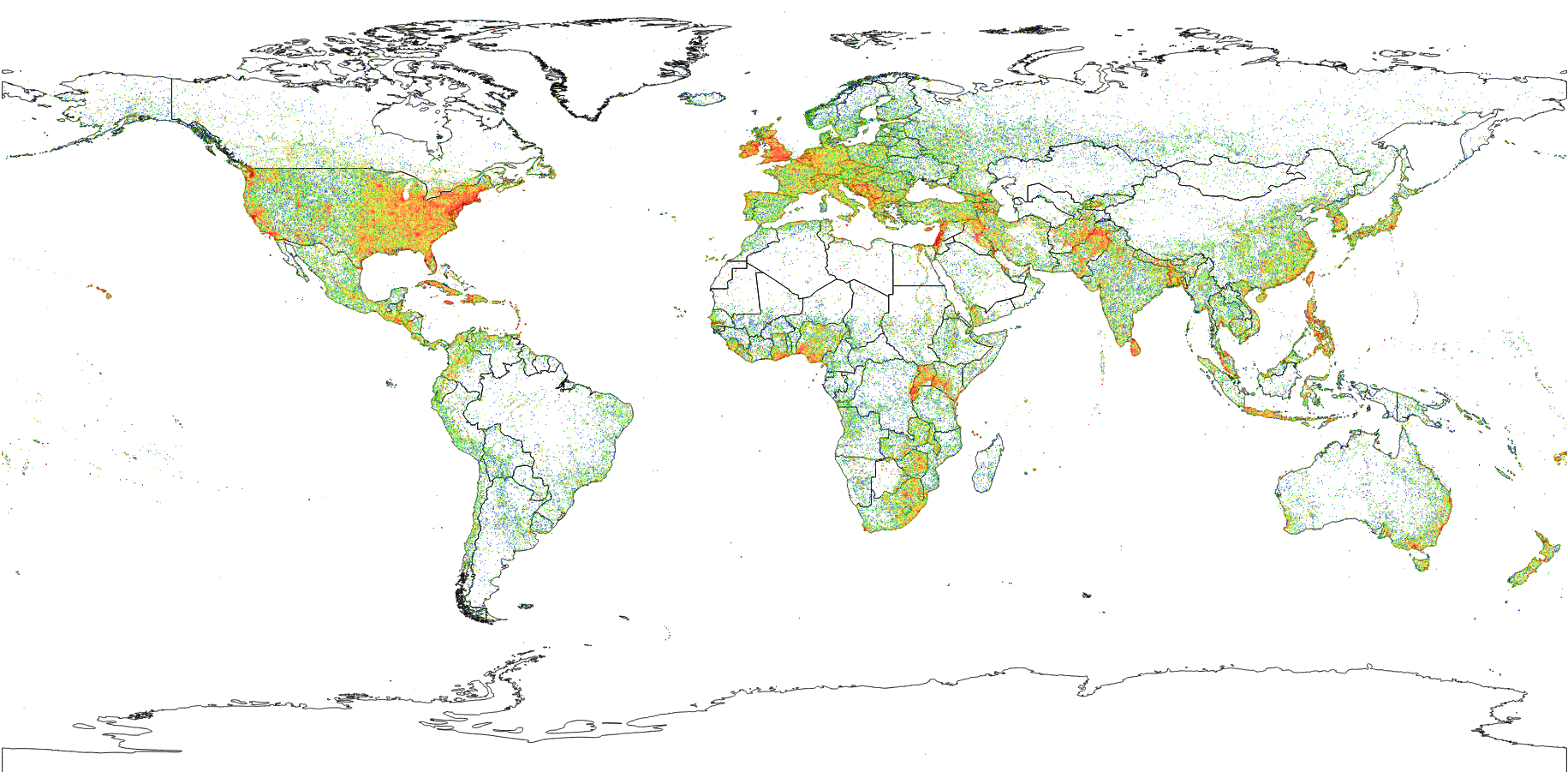
在第二个演示中,我们通过离散化空间域并计算要素在每个网格单元中的出现次数来计算要素的密度。我们用 GeoHashes 作为我们对世界的离散化,以便我们可以通过设置GeoHash中的位数来配置我们的密度的分辨率。
这段代码不存在于GeoMesa中;它留给读者作为练习。
首先,从类似的 RDD[SimpleFeature] 和以前一样,但展开边界框。
val f = ff.bbox("geom", -180, -90, 180, 90, "EPSG:4326")
val q = new Query("gdelt", f)
val queryRDD = spatialRDDProvider.rdd(new Configuration, sc, params, q, None)
项目(在关系意义上) SimpleFeature 设置为2元组 (GeoHash, 1) 。
val discretized = queryRDD.map { f =>
(geomesa.utils.geohash.GeoHash(f.getDefaultGeometry.asInstanceOf[Point], 25), 1)
}
然后,按格网单元分组并计算每个单元的要素数量。
val density = discretized.reduceByKey(_ + _)
density.collect.foreach(println)
生成的密度图如下所示。