GeoMesa Spark:空间连接和聚合¶
本教程将向您展示如何:
将GeoMesa用于 Apache Spark 在斯卡拉。
通过我们的地理空间用户定义函数创建和使用DataFrame。
根据阈值距离计算聚合统计数据。
创建新的简单要素类型来表示此聚合。
将结果写回数据存储。
背景¶
NYCTaxi 是伊利诺伊大学发布的出租车活动数据,从信息自由法的要求到纽约市出租车和豪华轿车委员会。
GeoNames 是一个包含1000多万个地名和900多万个独特特征的地理数据库。
假设我们想要回答这样的问题:“出租车接送是集中在特定的兴趣点附近吗?”,“人们更有可能要求接送还是在兴趣点下车?”为了找出答案,我们需要将这两个数据集结合在一起,并汇总结果的统计数据。
由于GeoNames是一个点的数据集,而nyctaxi只提供行程的上下车点,因此行程不太可能准确地在标记的兴趣点开始或结束。因此,我们不能天真地根据点相等的位置连接数据集。取而代之的是,我们需要将这些点连接在彼此之间可以容忍的距离内。这在下文中称为D-in联接。
先决条件¶
对于本教程,我们将假设您已经将两个数据集摄取到您选择的数据存储中。在没有创建必要的表的情况下遵循本教程将导致错误。
GeoNames数据集的转换器, GeoNames ,和nyctaxi数据集, 纽约市出租车 ,均随GeoMesa提供。要获得进一步的指导,您可以按照摄取教程之一进行操作 MAP-减少GDELT的摄取 。在GeoMesa中获取数据后,您可以继续本教程的其余部分。
正在初始化Spark¶
要开始使用Spark,我们需要初始化Spark会话,要将GeoMesa的地理空间用户定义类型(UDT)和用户定义函数(UDF)应用到Spark中的数据,我们需要初始化SparkSQL扩展。该功能要求在运行Spark作业时在类路径上具有适当的GeoMesa Spark运行时JAR。GeoMesa为Acumulo、HBase和文件系统数据存储提供了Spark运行时JAR。例如,以下代码将启动一个交互式Spark REPL,其中包含在Acumulo数据存储上使用GeoMesa运行Spark所需的所有依赖项。替换 ${VERSION} 使用适当的Scala Plus GeoMesa版本(例如 2.12-4.0.2 ):
$ bin/spark-shell --jars geomesa-accumulo-spark-runtime-accumulo2_${VERSION}.jar
备注
看见 空间RDD提供程序 有关选择正确的GeoMesa Spark运行时JAR的详细信息。
要配置Spark会话以便我们可以序列化简单特征并使用几何UDT和UDF,我们必须按如下方式更改Spark会话。
import org.apache.spark.sql.SparkSession
import org.locationtech.geomesa.spark.GeoMesaSparkKryoRegistrator
import org.locationtech.geomesa.spark.jts._
val spark: SparkSession = SparkSession.builder()
.appName("testSpark")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.kryo.registrator", classOf[GeoMesaSparkKryoRegistrator].getName)
.master("local[*]")
.getOrCreate()
.withJTS
请注意 withJTS ,它注册了GeoMesa的UDT和UDF,以及两个 config 这些选项告诉Spark使用GeoMesa的定制Kryo序列化程序和注册器来处理简单功能的序列化。这些配置选项也可以在 conf/spark-defaults.conf 配置文件。
创建DataFrame¶
创建并配置Spark会话后,我们可以继续将数据从数据存储加载到Spark DataFrame。
首先,我们将设置用于连接到数据存储的参数。例如,如果我们的数据位于两个Acumulo目录中,我们将设置以下参数映射:
val taxiParams = Map(
"accumulo.instance.name" -> "instance",
"accumulo.zookeepers" -> "zoo1:2181,zoo2:2181,zoo3:2181",
"accumulo.user" -> "user",
"accumulo.password" -> "password",
"accumulo.catalog" -> "nyctaxi")
val geonamesParams = Map(
"accumulo.instance.name" -> "instance",
"accumulo.zookeepers" -> "zoo1:2181,zoo2:2181,zoo3:2181",
"accumulo.user" -> "user",
"accumulo.password" -> "password",
"accumulo.catalog" -> "geonames")
备注
以上参数假定Acumulo为后备数据存储,但本教程的其余部分与使用哪个数据存储无关。只需适当地调整上述参数即可使用其他受支持的数据存储。
然后我们就可以利用斯帕克的 DataFrameReader 还有我们的 SpatialRDDProvider 要创建 DataFrame
val taxiDF = spark.read.format("geomesa")
.options(taxiParams)
.option("geomesa.feature", "nyctaxi-single")
.load()
val geonamesDF = spark.read.format("geomesa")
.options(geonamesParams)
.option("geomesa.feature", "geonames")
.load()
因为我们知道我们的出租车数据仅限于纽约州,所以我们可以过滤我们的地理名称数据。
import spark.implicits._
import org.apache.spark.sql.functions._
val geonamesNY = geonamesDF.where($"admin1Code" === lit("NY"))
D-在连接内¶
现在我们准备好连接这两个数据集。这就是我们将使用两个地理空间UDF的地方。 st_contains 接受两个几何图形作为输入,并输出第二个几何图形是否位于第一个几何图形内。 st_bufferPoint 将一个点和一个以米为单位的距离作为输入,并输出一个半径等于提供的距离的圆围绕该点。有关GeoMesa提供的更多文档和UDF的完整列表,请参阅 SparkSQL函数 。
使用这两个UDF,我们可以构建以下联接查询。
val joinedDF = geonamesNY
.select(st_bufferPoint($"geom", lit(50)).as("buffer"), $"name", $"geonameId")
.join(taxiDF, st_contains($"buffer", $"pickup_point"))
上面的查询将每个GeoName点的几何图形转换为半径为50米的圆,并将结果与该圆内任何位置的出租车记录连接在一起。
聚合¶
现在我们有了一个DataFrame,其中纽约的每个兴趣点都与出租车记录相结合,其中大约从那个位置发出了一辆皮卡。为了将其转化为关于该地区出租车习惯的有意义的统计数据,我们可以做一个 GROUP BY 操作并使用SparkSQL的一些聚合函数。
val aggregateDF = joinedDF.groupBy($"geonameId")
.agg(first("name").as("name"),
countDistinct($"trip_id")).as(s"numPickups"),
first("buffer").as("buffer"))
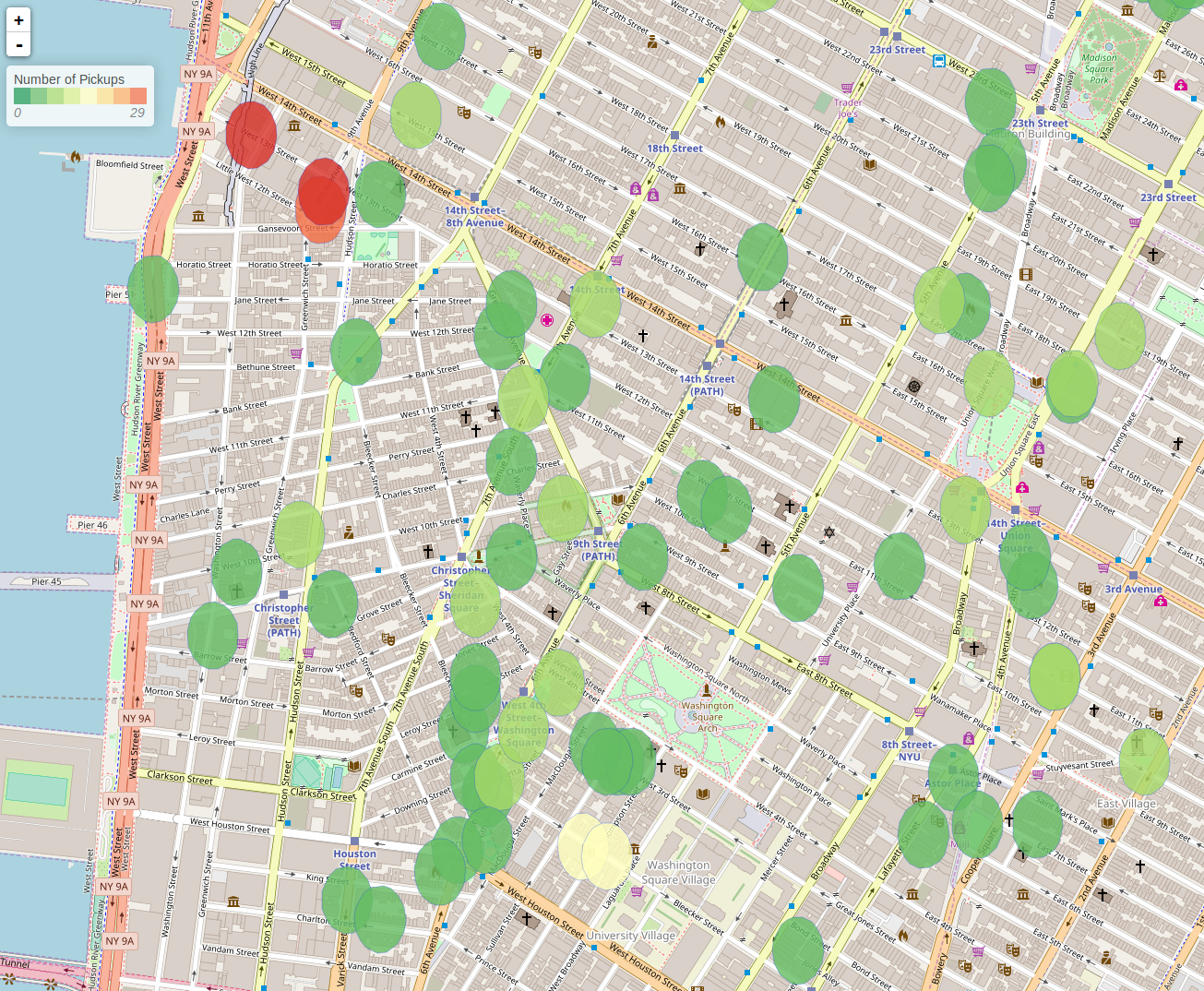
上面的查询根据兴趣点对数据进行分组,并计算不同拾取的数量。结果可以用来生成基于皮卡密度的兴趣点热图,但要快速查看哪些兴趣点最远离出租车,我们可以对结果进行排序并查看前十名。
val top10 = aggregateDF.orderBy($"numPickups".desc).take(10)
top10.foreach { row => println(row.getAs[String]("name") + row.getAs[Int]("numPickups")) }
这告诉我们,Gansevoort酒店有最多的出租车接送。
回写¶
如果我们想要在Spark会话之后持久保存此聚合结果,则需要将其写回底层数据存储。这是完成这两个步骤。
首先,我们创建一个与聚合结果一致的SimpleFeatureType:
import org.locationtech.geomesa.utils.geotools.SchemaBuilder
val aggregateSft = SchemaBuilder.builder()
.addString("name")
.addInt("numPickups")
.addPolygon("buffer")
.build("aggregate")
接下来,我们可以在数据存储中创建模式,然后安全地写入数据。
import org.geotools.data.DataStoreFinder
DataStoreFinder.getDataStore(taxiParams).createSchema(aggregateSft)
aggregateDF.write.format("geomesa").options(taxiParams).option("geomesa.feature", "aggregate").save()
如果您遵循上述所有步骤,最终结果将是一个数据集,其中包含纽约所有兴趣点的出租车接送密度,并可选择写回数据存储。如果您想进一步将此结果与出租车落客点的分布进行比较,则可以很容易地将上述代码修改为使用落客点。
可以按照中的示例采取进一步的步骤来可视化此结果 GeoMesa Spark:广播加入和聚合 。这将导致如下所示: