11.8. 使用Jupyter笔记本部署GeoMesa Spark¶
Jupyter Notebook 是一个基于Web的应用程序,用于创建包含可运行代码、可视化效果和文本的交互式文档。通过 Apache Toree 内核,Jupyter可以用于在Scala中准备时空分析并将其提交到 Spark 。下面的指南介绍了如何使用Spark配置Jupyter 3.3 和GeoMesa。
备注
GeoMesa对PySpark的支持通过使用Jupyter的内置Python内核的Spark PythonAPI提供对GeoMesa Acumulo数据存储的访问。看见 GeoMesa火花源 。
11.8.1. 先决条件¶
Spark 3.3 应该安装,并且环境变量 SPARK_HOME 应该设置。
Python 应安装2.7或3.x,并且建议将Jupyter和Toree安装在Python内部 virtualenv 或在一个 conda 环境。
11.8.2. 安装Jupyter¶
木星可以通过以下方式安装 pip (适用于Python2.7)或 pip3 (对于Python3.x):
$ pip install --upgrade jupyter
或
$ pip3 install --upgrade jupyter
11.8.3. 安装Toree内核¶
$ pip install --upgrade toree
或
$ pip3 install --upgrade toree
11.8.4. 配置Toree和GeoMesa¶
如果您在以下位置安装了GeoMesa Acumulo发行版 GEOMESA_ACCUMULO_HOME 如中所述 设置Acumulo命令行工具 ,您可以运行以下示例脚本来配置带有GeoMesa的Toree:
备注
确保您使用的Scala版本与您的Spark版本的Scala版本匹配。
$ export TAG="4.0.2"
$ export VERSION="2.12-${TAG}" # note: 2.12 is the Scala build version
#!/bin/sh
# bundled GeoMesa Accumulo Spark and Spark SQL runtime JAR
# (contains geomesa-accumulo-spark, geomesa-spark-core, geomesa-spark-sql, and dependencies)
jars="file://$GEOMESA_ACCUMULO_HOME/dist/spark/geomesa-accumulo-spark-runtime-accumulo2_$VERSION.jar"
# uncomment to use the converter RDD provider
#jars="$jars,file://$GEOMESA_ACCUMULO_HOME/lib/geomesa-spark-converter_$VERSION.jar"
# uncomment to work with shapefiles (requires $GEOMESA_ACCUMULO_HOME/bin/install-shapefile-dependencies.sh)
#jars="$jars,file://$GEOMESA_ACCUMULO_HOME/lib/jai_codec-1.1.3.jar"
#jars="$jars,file://$GEOMESA_ACCUMULO_HOME/lib/jai_core-1.1.3.jar"
#jars="$jars,file;//$GEOMESA_ACCUMULO_HOME/lib/jai_imageio-1.1.jar"
jupyter toree install \
--replace \
--user \
--kernel_name "GeoMesa Spark $VERSION" \
--spark_home=${SPARK_HOME} \
--spark_opts="--master yarn --jars $jars"
备注
指定的罐子将位于各自的 target 如果您从源代码构建GeoMesa,则为源代码分发的每个模块的目录。
备注
你可能想要改变一下 --spark_opts 来指定执行器的数量和配置;否则, $SPARK_HOME/conf/spark-defaults.conf 或 $SPARK_OPTS 将会被使用。
您还可以考虑添加 geomesa-tools_${VERSION}-data.jar 为公开可用的数据源包括预打包的转换器(如中所述 预打包的转换器定义 ), geomesa-spark-jupyter-leaflet_${VERSION}.jar 以包括用于 Leaflet 空间可视化库(请参见 可视化宣传单 ,下文)和/或 geomesa-spark-jupyter-vegas_${VERSION}.jar 要使用 Vegas 数据绘图库(请参见 拉斯维加斯的阴谋 ,下文)。
11.8.5. 奔跑的木星¶
对于公共笔记本电脑,您应该 configure Jupyter 使用密码并绑定到公共IP地址(默认情况下,Jupyter将只接受来自 localhost )。要使用GeoMesa Spark内核运行Jupyter,请执行以下操作:
$ jupyter notebook
备注
长时间的流程可能应该托管在 screen , systemd ,或 supervisord 。
您的笔记本服务器应该启动并可在http://localhost:8888/(或您将服务器绑定到的地址和端口)访问,这可能需要一个访问令牌,该令牌将显示在服务器输出中。
备注
所有Spark代码将作为运行Jupyter服务器的用户帐户提交。您可能希望查看 JupyterLab 用于多用户Jupyter服务器。
11.8.6. 可视化宣传单¶
以下示例笔记本显示了如何使用LEAFLE进行数据可视化:
classpath.addRepository("https://repo1.maven.org/maven2")
classpath.addRepository("https://repo.osgeo.org/repository/release")
classpath.addRepository("file:///home/username/.m2/repository")
classpath.add("org.locationtech.geomesa" % "geomesa-accumulo-datastore_2.12" % "4.0.0")
classpath.add("org.locationtech.geomesa" % "geomesa-spark-jupyter-leaflet_2.12" % "4.0.0")
classpath.add("org.locationtech.jts" % "jts-core" % "1.19.0")
classpath.add("org.apache.accumulo" % "accumulo-core" % "2.0.1")
import org.locationtech.geomesa.accumulo.data.AccumuloDataStoreParams._
import org.locationtech.geomesa.jupyter._
import org.locationtech.geomesa.utils.geotools.Conversions._
import scala.collection.JavaConverters._
implicit val displayer: String => Unit = display.html(_)
val params = Map(
ZookeepersParam.key -> "ZOOKEEPERS",
InstanceNameParam.key -> "INSTANCE",
UserParam.key -> "USER_NAME",
PasswordParam.key -> "USER_PASS",
CatalogParam.key -> "CATALOG")
val ds = org.geotools.data.DataStoreFinder.getDataStore(params.asJava)
val ff = org.geotools.factory.CommonFactoryFinder.getFilterFactory2
val fs = ds.getFeatureSource("twitter")
val filt = ff.and(
ff.between(ff.property("dtg"), ff.literal("2016-01-01"), ff.literal("2016-05-01")),
ff.bbox("geom", -80, 37, -75, 40, "EPSG:4326"))
val features = fs.getFeatures(filt).features.asScala.take(10).toList
displayer(L.render(Seq(WMSLayer(name="ne_10m_roads",namespace="NAMESPACE"),
Circle(-78.0,38.0,1000, StyleOptions(color="yellow",fillColor="#63A",fillOpacity=0.5)),
Circle(-78.0,45.0,100000,StyleOptions(color="#0A5" ,fillColor="#63A",fillOpacity=0.5)),
SimpleFeatureLayer(features)
)))
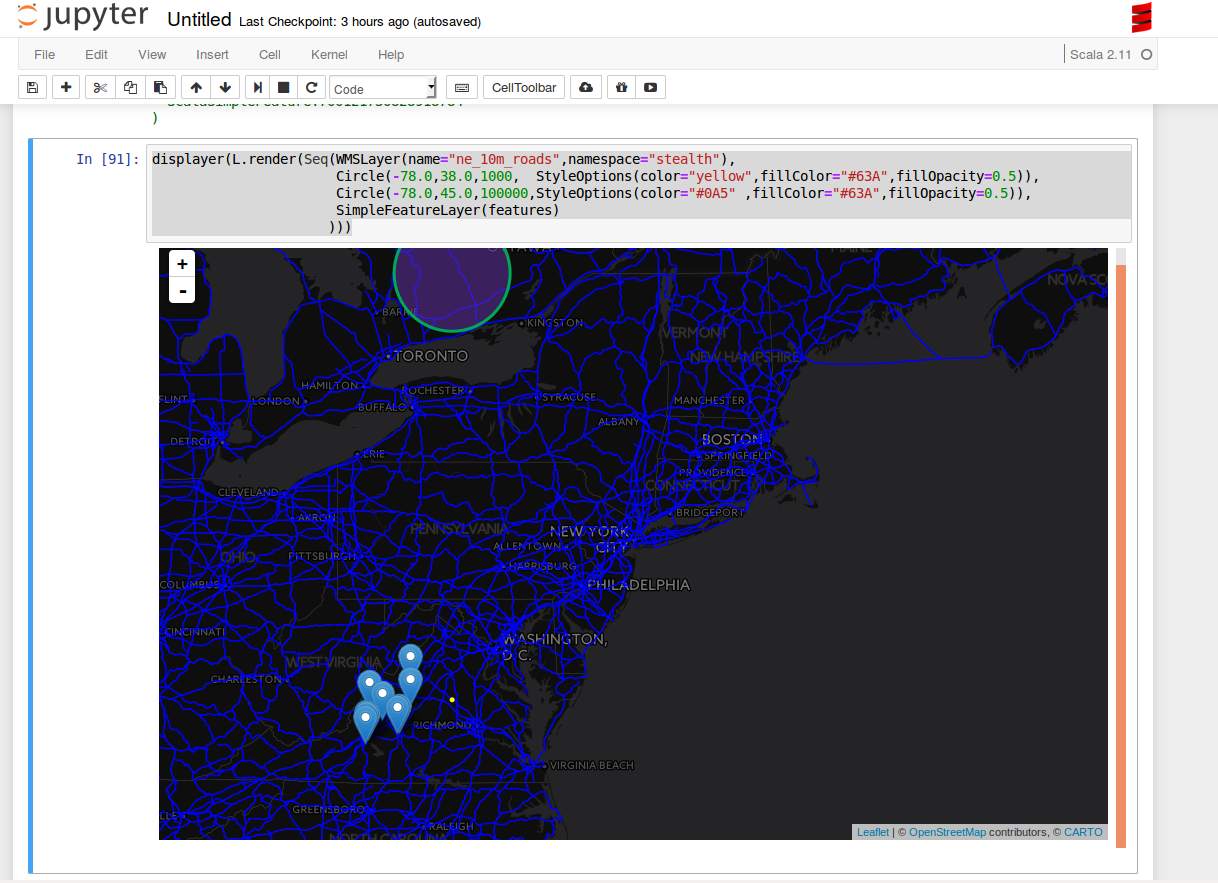
11.8.6.1. 将图层添加到地图并显示在笔记本中¶
以下片段是在Jupyter笔记本的传单中呈现数据帧的示例:
implicit val displayer: String => Unit = { s => kernel.display.content("text/html", s) }
val function = """
function(feature) {
switch (feature.properties.plane_type) {
case "A388": return {color: "#1c2957"}
default: return {color: "#cdb87d"}
}
}
"""
val sftLayer = time { L.DataFrameLayerNonPoint(flights_over_state, "__fid__", L.StyleOptionFunction(function)) }
val apLayer = time { L.DataFrameLayerPoint(flyovers, "origin", L.StyleOptions(color="#1c2957", fillColor="#cdb87d"), 2.5) }
val stLayer = time { L.DataFrameLayerNonPoint(queryOnStates, "ST", L.StyleOptions(color="#1c2957", fillColor="#cdb87d", fillOpacity= 0.45)) }
displayer(L.render(Seq[L.GeoRenderable](sftLayer,stLayer,apLayer),zoom = 1, path = "path/to/files"))
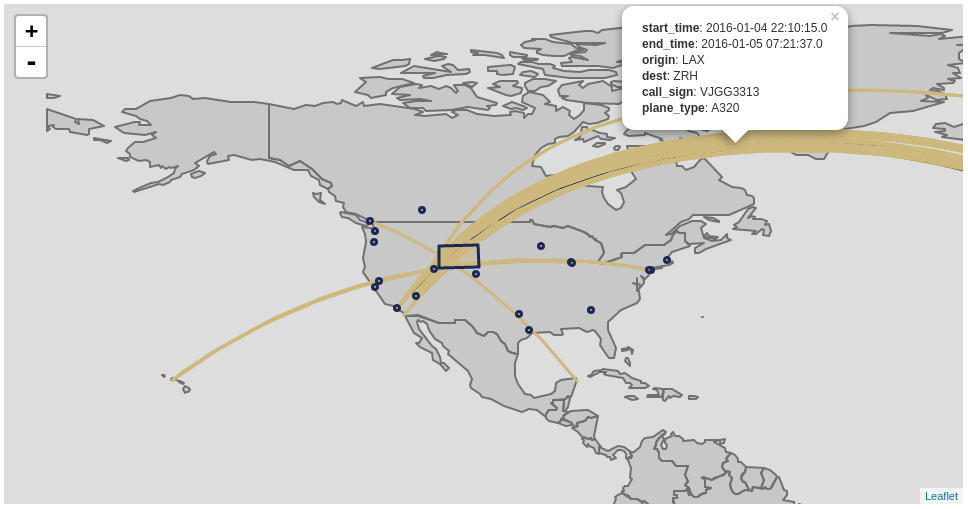
11.8.6.2. StyleOptionFunction¶
这个Case类允许您指定一个执行样式的Java脚本函数。您将传递的匿名函数将一个功能作为参数,并返回一个Java脚本样式的对象。下面提供了一个基于特定特性值的样式设置示例:
function(feature) {
switch(feature.properties.someProp) {
case "someValue": return { color: "#ff0000" }
default : return { color: "#0000ff" }
}
}
下表提供了您可能感兴趣的选项:
选择权 |
类型 |
描述 |
|---|---|---|
颜色 |
细绳 |
笔触颜色 |
重量 |
数 |
笔划宽度(像素) |
不透明度 |
数 |
笔划不透明度 |
填充颜色 |
细绳 |
填充颜色 |
填充不透明度 |
数 |
填充不透明度 |
注意:选项以逗号分隔(即 { color: "#ff0000", fillColor: "#0000ff" } )
11.8.7. 拉斯维加斯的阴谋¶
这个 Vegas 库可与木星中的GeoMesa、Spark和Toree一起使用,以绘制定量数据。这个 geomesa-spark-jupyter-vegas 模块构建了一个阴影JAR,其中包含在Jupyter+Toree中运行维加斯所需的所有依赖项。此模块必须从源代码构建,使用 vegas 个人资料:
$ mvn clean install -Pvegas -pl geomesa-spark/geomesa-spark-jupyter-vegas
这将建立 geomesa-spark-jupyter-vegas_${VERSION}.jar 在 target 目录,并且应该添加到 jupyter toree install 中介绍的命令 配置Toree和GeoMesa :
jars="$jars,file:///path/to/geomesa-spark-jupyter-vegas_${VERSION}.jar"
# then continue with "jupyter toree install" as before
要在Jupyter中使用拉斯维加斯,请加载适当的库和一个显示器:
import vegas._
import vegas.render.HTMLRenderer._
import vegas.sparkExt._
implicit val displayer: String => Unit = { s => kernel.display.content("text/html", s) }
然后使用 withDataFrame 方法绘制数据。 DataFrame :
Vegas("Simple bar chart").
withDataFrame(df).
encodeX("a", Ordinal).
encodeY("b", Quantitative).
mark(Bar).
show(displayer)