6.4. Lesson: 空间统计
备注
林菲尼蒂和S·莫塔拉(开普敦半岛技术大学)开发的课程
空间统计允许您分析和了解给定矢量数据集中发生的情况。QGIS包括许多有用的统计分析工具。
The goal for this lesson: 要了解如何使用QGIS的空间统计工具 Processing Toolbox 。
6.4.1.  Follow Along: Create a Test Dataset
Follow Along: Create a Test Dataset
我们将创建一组随机的点,以获得要使用的数据集。
为此,您需要一个多边形数据集来定义要在其中创建点的区域。
我们将使用街道覆盖的区域。
开始一个新项目
添加您的
roads数据集,以及srtm_41_19(高程数据)位于exercise_data/raster/SRTM/。备注
您可能会发现,SRTM DEM图层具有与Roads图层不同的CRS。QGIS将在单个CRS中重新投影这两个层。对于下面的练习,这种差异并不重要,但可以随意重新投影(如本模块前面所示)。
打开 Processing 工具箱
使用 此工具用于生成包含所有道路的区域,方法是选择
Convex Hull作为 Geometry Type :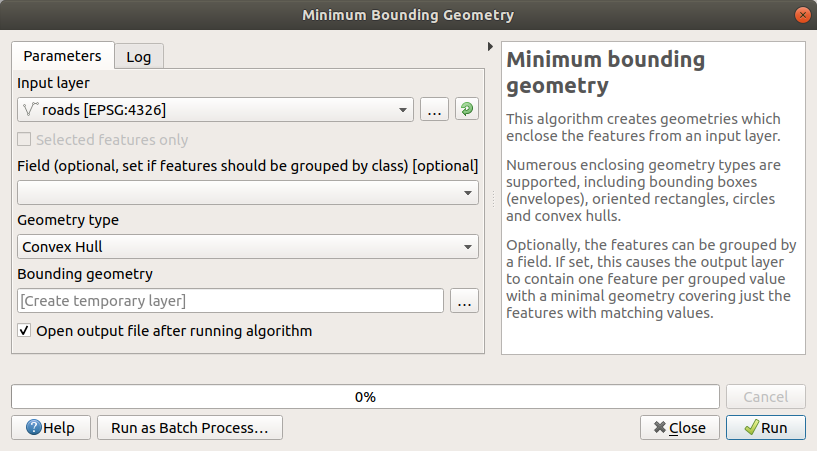
如您所知,如果您不指定输出, Processing 创建临时层。您可以立即保存这些层,也可以在以后保存这些层。
创建随机点
使用该工具在该区域创建100个随机点 ,最小距离为
0.0: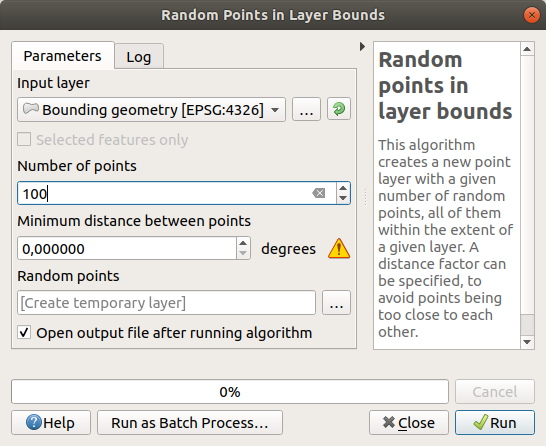
备注
黄色警告符号告诉您该参数与距离有关。这个 Bounding geometry 图层位于地理坐标系中,算法只是提醒您这一点。在本例中,我们将不使用此参数,因此您可以忽略它。
如果需要,将生成的随机点移动到图例的顶部,以便更好地查看它们:
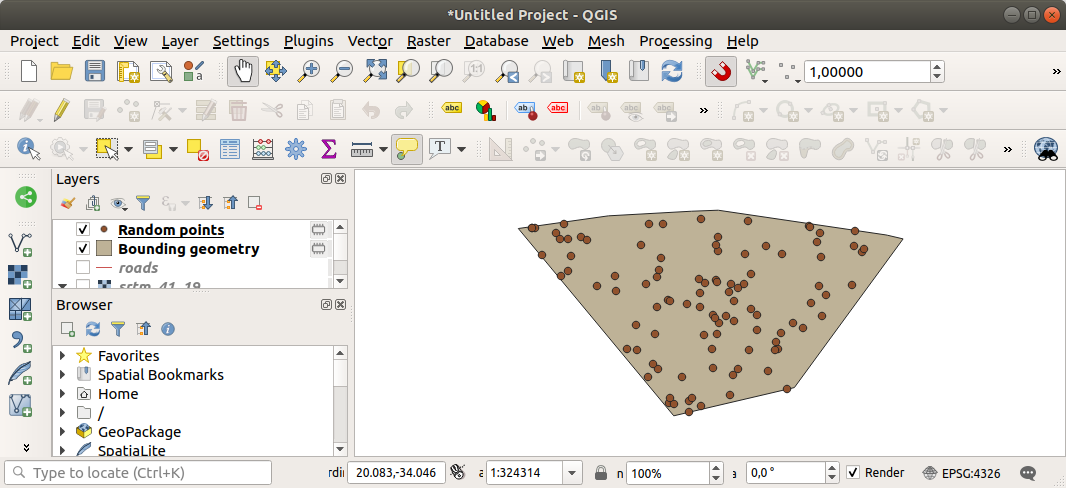
采样数据
要从栅格创建样本数据集,您需要使用 算法。此工具在点的位置对栅格进行采样,并根据栅格中的波段数将栅格值添加到新字段(S)中。
打开 Sample raster values 算法对话框
选择
Random_points作为包含采样点的层,并将SRTM栅格作为从中获取值的波段。新字段的默认名称为rvalue_N,在哪里N是栅格波段的编号。如果需要,您可以更改前缀的名称。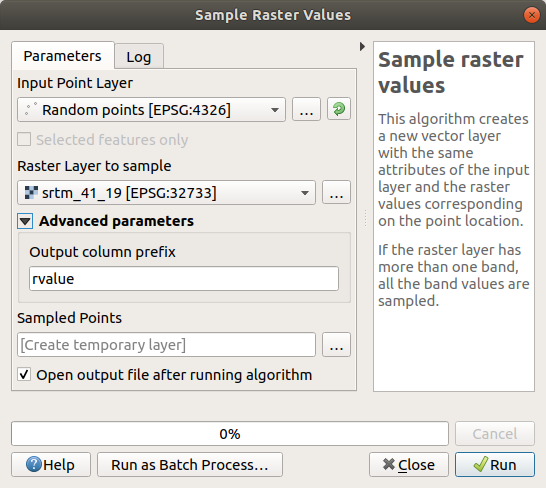
新闻发布会 Run
现在,您可以在的属性表中检查栅格文件中的采样数据 Sampled Points 一层。它们将出现在一个新的字段中,名称为您选择的名称。
可能的样本层如下所示:
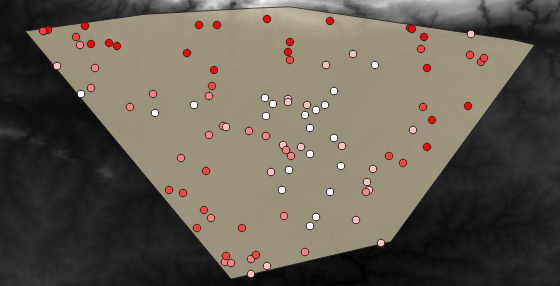
采样点使用 rvalue_1 使红点位于较高海拔的田野。
您将在其余的统计练习中使用该示例层。
6.4.2. Follow Along: Basic Statistics
现在获取该层的基本统计信息。
按下
 Show statistical summary 图标中的 Attributes Toolbar 。将弹出一个新的面板。
Show statistical summary 图标中的 Attributes Toolbar 。将弹出一个新的面板。在出现的对话框中,指定
Sampled PointsLayer作为源。选择 rvalue_1 字段组合框中的字段。这是您将为其计算统计数据的字段。
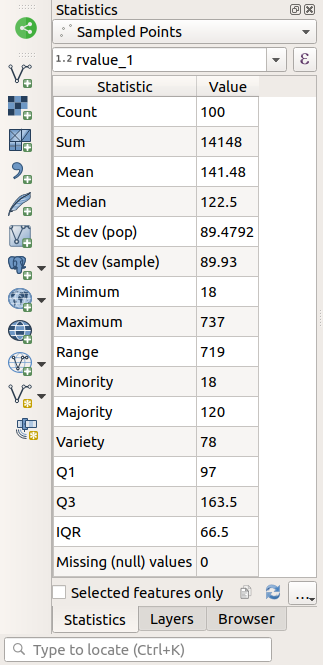
这个 Statistics Panel将使用计算出的统计数据自动更新:
备注
您可以通过单击
 Copy Statistics To Clipboard 按钮并将结果粘贴到电子表格中。
Copy Statistics To Clipboard 按钮并将结果粘贴到电子表格中。关闭 Statistics 完成后的面板
有许多不同的统计数据可用:
- 数数
采样数/值。
- 求和
这些值加在一起。
- 平均
平均值(Average)就是数值除以数值的总和。
- 中位数
如果将所有值按从小到大的顺序排列,则中间值(如果N为偶数,则为两个中间值的平均值)为这些值的中位数。
- ST Dev(POP)
标准差。表示这些值围绕平均值聚集的程度。标准差越小,值越接近平均值。
- 最低要求
最小值。
- 极大值
最大值。
- 射程
最小值和最大值之间的差值。
- Q1
数据的第一个四分位数。
- Q3
数据的第三个四分之一。
- 缺少(空)值
缺少的值数。
6.4.3. Follow Along: Compute statistics on distances between points
创建新的临时点图层。
进入编辑模式,数字化其他点中的三个点。
或者,使用与前面相同的随机点生成方法,但仅指定 three 积分。
将新图层另存为 distance_points 以您喜欢的格式。
要生成关于两个层中的点之间距离的统计信息,请执行以下操作:
打开 工具。
选择
distance_points层作为输入层,而Sampled Points层作为目标层。如下所示进行设置:
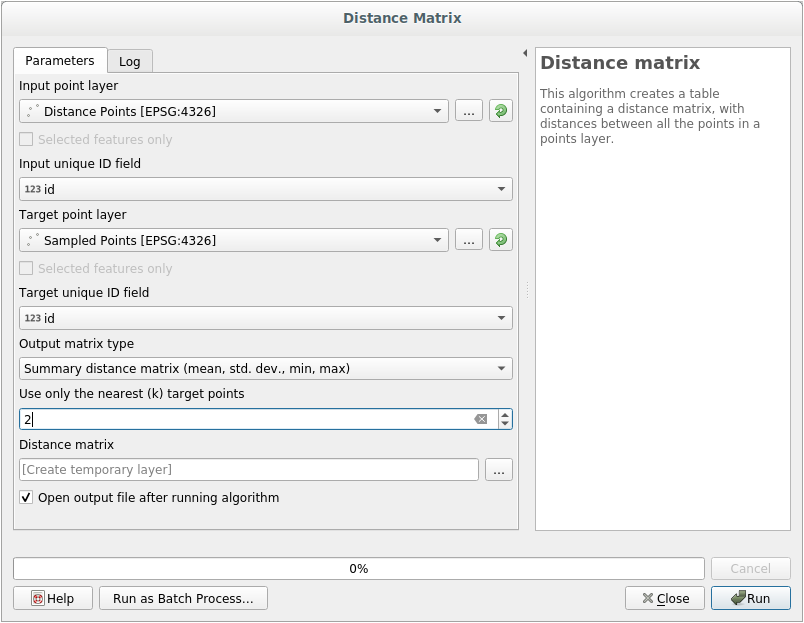
如果需要,可以将输出层另存为文件,或仅运行算法并在以后保存临时输出层。
单击 Run 以生成距离矩阵层。
打开生成的层的属性表:值是指 distance_points 中的要素及其最近的两点 Sampled Points 层:
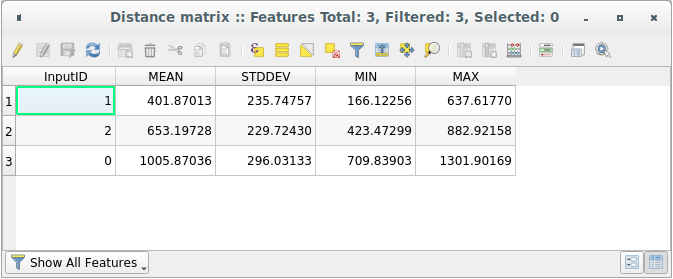
有了这些参数, Distance Matrix 工具计算输入图层中每个点相对于目标图层中最近点的距离统计信息。输出层的字段包含到输入层中各点最近邻点的距离的平均值、标准差、最小值和最大值。
6.4.4. Follow Along: Nearest Neighbor Analysis (within layer)
要对点图层执行最近邻分析,请执行以下操作:
选 。
在出现的对话框中,选择 Random points 层,然后单击 Run 。
结果将显示在处理过程中 Result Viewer 面板。
单击蓝色链接以打开
html包含结果的页面: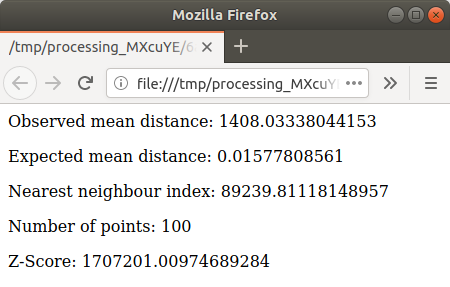
6.4.5. Follow Along: Mean Coordinates
要获取数据集的平均坐标,请执行以下操作:
开始
在出现的对话框中,指定 Random points AS Input layer ,并保留可选选项不变。
单击 Run 。
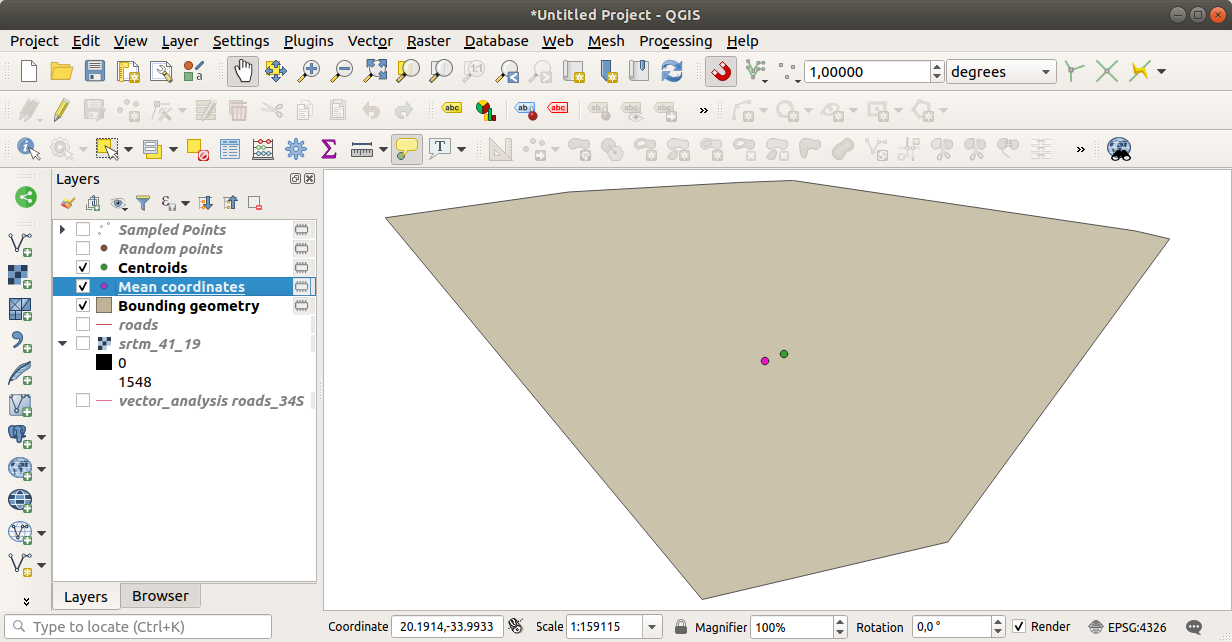
让我们将其与用于创建随机样本的多边形的中心坐标进行比较。
开始
在出现的对话框中,选择
Bounding geometry作为输入层。
如您所见,平均坐标(粉红色的点)和研究区域的中心(绿色)不一定重合。
质心是层的重心(正方形的重心是正方形的中心),而平均坐标表示所有节点坐标的平均值。
6.4.6. Follow Along: Image Histograms
数据集的直方图显示其值的分布。在QGIS中演示这一点的最简单方法是通过图像直方图,可在 Layer Properties 任何图像层(栅格数据集)的对话框。
在您的 Layers 面板中,右击
srtm_41_19图层选择
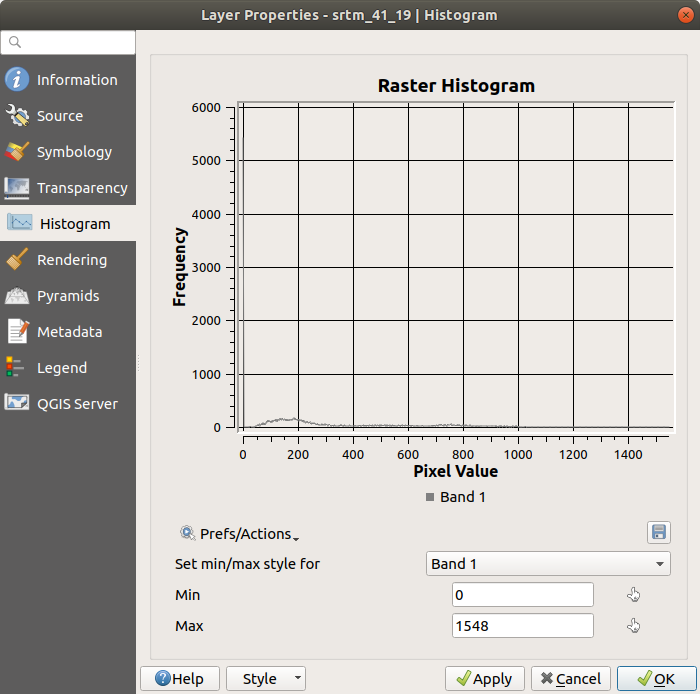
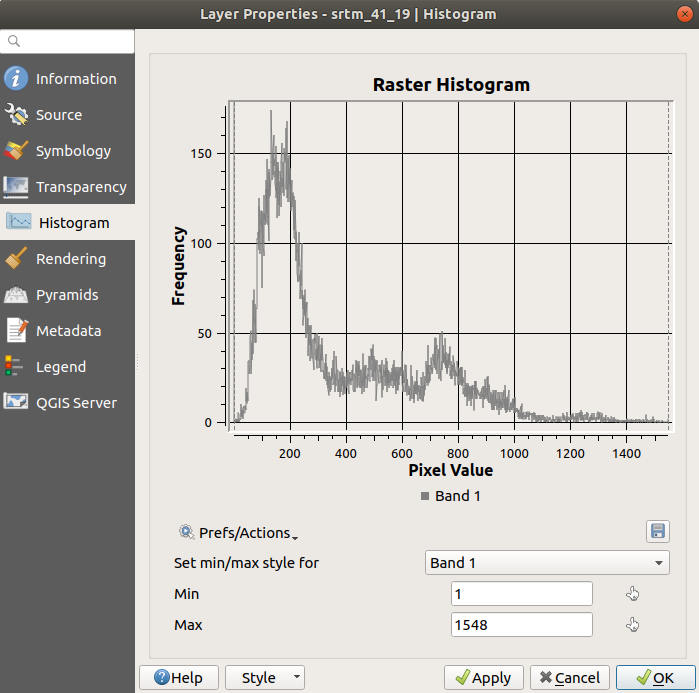
选择 Histogram 标签。您可能需要单击 Compute Histogram 按钮以生成图形。您将看到一个图表,其中显示了栅格值的频率分布。
可以将该图形导出为具有
 Save plot 按钮
Save plot 按钮中可以查看有关该层的更多详细信息 Information 制表符(平均值和最大值是估计值,可能不准确)。
平均值为 332.8 (估计为324.3),最大值为 1699 (估计为1548人)!您可以放大直方图。因为有很多有价值的像素 0 ,直方图看起来是垂直压缩的。通过放大覆盖除峰值以外的所有内容 0 ,您将看到更多详细信息:
备注
如果平均值和最大值与上面不同,则可能是由于最小/最大值计算所致。打开 Symbology 选项卡并展开 Min / Max Value Settings 菜单。选  :guiabel:最小/最大`并点击 :guilabel:`Apply 。
:guiabel:最小/最大`并点击 :guilabel:`Apply 。
请记住,直方图向您显示值的分布,并不是所有的值在图表上都一定可见。
6.4.7. Follow Along: Spatial Interpolation
假设您有一个样本点集合,您想从这些样本点中推断数据。例如,您可能可以访问 Sampled points 我们之前创建的数据集,并希望对地形有一些了解。
要开始,请启动 中的工具 Processing Toolbox 。
为 Point layer 选择
Sampled points集 Weighting power 至
5.0在……里面 Advanced parameters ,设置 Z value from field 至
rvalue_1最后点击 Run 并等待处理结束
关闭该对话框
下面是原始数据集(左)与从样本点构建的数据集(右)的比较。由于采样点位置的随机性,您的图像可能会有所不同。
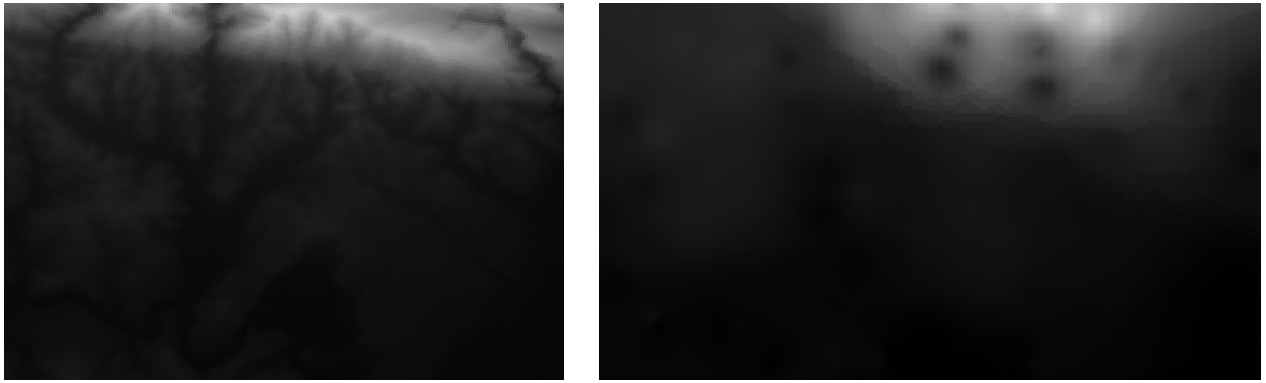
如你所见,100个样本点并不足以获得地形的详细印象。它给出了一个非常笼统的概念,但它也可能具有误导性。
6.4.8.  Try Yourself Different interpolation methods
Try Yourself Different interpolation methods
使用上面所示的过程创建一组10,000个随机点
备注
如果点数真的很大,处理时间可能会很长。
使用这些点对原始DEM进行采样
使用 Grid (IDW with nearest neighbor searching) 此数据集上的工具。
集 Power 和 Smoothing 至
5.0和2.0,分别为。
结果(取决于随机点的位置)大致如下所示:

由于采样点的密度较大,这可以更好地表示地形。记住,更大的样本会产生更好的结果。
6.4.9. In Conclusion
QGIS有许多用于分析数据集的空间统计属性的工具。
6.4.10. What's Next?
既然我们已经介绍了矢量分析,为什么不看看栅格可以做些什么呢?这就是我们在下一个模块中要做的!