拟合曲线¶
用于拟合曲线的例程是 scipy.optimize 模块,并调用 scipy.optimize.curve_fit() 。因此,首先必须导入所述模块。
>>> import scipy.optimize
要适合您的数据的函数必须使用 x 值作为第一个参数,所有参数作为后续参数。
>>> def parabola(x, a, b, c):
... return a*x**2 + b*x + c
...
出于测试目的,使用具有已知参数的所述函数来生成数据。
>>> params = [-0.1, 0.5, 1.2]
>>> x = np.linspace(-5, 5, 31)
>>> y = parabola(x, params[0], params[1], params[2])
>>> plt.plot(x, y, label='analytical')
[<matplotlib.lines.Line2D object at ...>]
>>> plt.legend(loc='lower right')
<matplotlib.legend.Legend object at ...>
>>> plt.show()
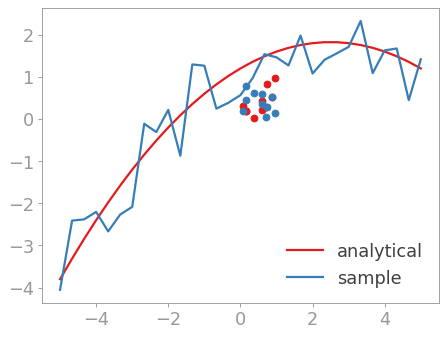
然后引入一些小偏差,因为拟合函数本身产生的数据有点乏味。
>>> r = np.random.RandomState(42)
>>> y_with_errors = y + r.uniform(-1, 1, y.size)
>>> plt.plot(x, y_with_errors, label='sample')
[<matplotlib.lines.Line2D object at ...>]
>>> plt.legend(loc='lower right')
<matplotlib.legend.Legend object at ...>
>>> plt.show()
现在可以调用拟合例程了。
>>> fit_params, pcov = scipy.optimize.curve_fit(parabola, x, y_with_errors)
它返回两个结果,即由拟合产生的参数和协方差矩阵,该协方差矩阵可用于计算拟合的某种形式的质量尺度。可以将拟合的实际数据与实际参数进行比较:
>>> for param, fit_param in zip(params, fit_params):
... print(param, fit_param)
...
-0.1 -0.0906682795944
0.5 0.472361903203
1.2 1.00514576223
>>> y_fit = parabola(x, *fit_params)
>>> plt.plot(x, y_fit, label='fit')
[<matplotlib.lines.Line2D object at ...>]
>>> plt.legend(loc='lower right')
<matplotlib.legend.Legend object at ...>
>>> plt.show()
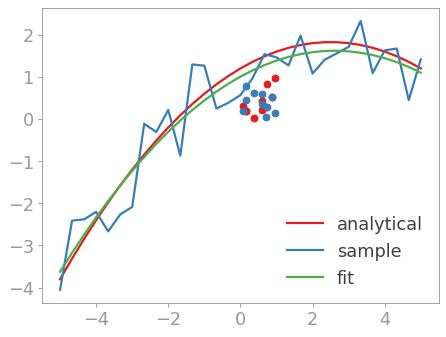
如您所见,第三个参数的拟合较差 c 。查看协方差矩阵也可以看出这一点:
>>> print(pcov)
[[ 1.64209005e-04 1.75357845e-12 -1.45963560e-03]
[ 1.75357845e-12 1.16405938e-03 -1.73642112e-11]
[ -1.45963560e-03 -1.73642112e-11 2.33217333e-02]]
但是,为了获得更有意义的适配质量等级,文档建议使用以下方法:
>>> print(np.sqrt(np.diag(pcov)))
[ 0.01281441 0.03411831 0.15271455]
所以最适合 a 是很好的,而质量 c 是所有参数中最差的。
注解
此例程的工作方式是迭代地更改参数,并检查拟合是变好了还是变差了。为了帮助例程找到最佳匹配,因此给它一个良好的起点是一个好主意。这可以使用 p0 论证 curve_fit() 。在某些情况下,这甚至是必要的。