进程/线程调度¶
内核模式与用户模式¶
内核模式
可以使用CPU的全部指令集。包括:
启用/禁用中断
设置特殊寄存器(页表指针、中断表指针等)
可以修改内存中的任何位置和修改页表
用户模式
不能使用特权指令。
只能修改分配给进程的内存。
中断¶
中断是需要CPU立即注意的事件。
处理中断的程序
将包括程序计数器在内的所有寄存器保存到内存(通常是堆栈,但不总是)
CPU在中断向量表上查找中断处理程序并调用中断处理程序
一旦中断处理程序完成,它将恢复所有寄存器并返回到程序计数器。它可以选择性地重试导致中断的指令(在页面错误的情况下)。
程序继续执行,而不知道发生了什么
该算法对于硬件中断和软件中断都是相同的。
硬件中断-PC体系结构¶
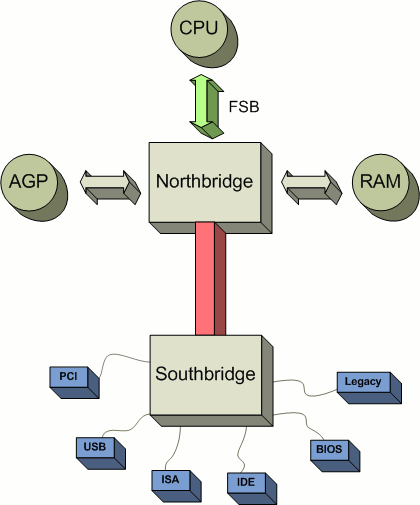
硬件中断-来源¶
南桥(又名慢东西)中断
早期的8088/8086 PC有一种名为Intel 8253的芯片。
SMP主板包括APIC或高级可编程中断控制器,以帮助在多处理器方案中路由中断
这些芯片控制来自磁盘的中断,并且
Northbridge(又名FAST)中断
MMU页面错误(不存在、无效或权限不足)
ALU-被零除异常
时钟滴答作响
软件中断¶
在内核和用户空间分离的操作系统中,使用软件中断来实现系统调用。
X86程序集中的Hello World:
section .text
global _start
_start:
mov edx, len ; message length
mov ecx, msg ; message to write
mov ebx, 1 ; 1 = stdout, the file descriptor
mov eax, 4 ; 4 = system call number (sys_write)
int 0x80 ; software interrupt to call the kernel
section .data
msg db 'Hello World!',0xa
len equ $ - msg
软件中断比通过类似于调用或JMP的指令进行直接函数调用的成本要高得多。
就我们在系统可靠性和安全性方面所节省的成本而言,这一成本是值得的
进程调度器的目标¶
进程调度策略的属性是以下属性的组合:
公平:确保每个进程都能得到公平的CPU份额。
效率:使CPU尽可能繁忙
响应时间:最大限度地缩短交互用户的响应时间。
扭亏为盈:最大限度地减少批量用户必须等待输出的时间
吞吐量:最大限度地提高每小时处理的作业数量
没有在这些属性中的每一个都是最佳的调度器实现。总会有一种取舍。这些属性中的许多可能是相互矛盾的。
调度策略的类型¶
先发制人
轮询
优先级调度
最短作业优先
关键路径
实时
最早截止日期
固定优先级
协作/事件驱动
运行至完成/非抢占
大多数现代操作系统使用轮询、抢占式调度以及对优先级的支持。
操作系统支持¶
非多任务处理
CP/M
MS-DOS
协作多任务
Windows 1.x-3.x
Mac OS 5-9
NetWare
抢占式多任务处理
MINIX
Windows 95-ME、NT4-7
Linux、BSD
OS/2
Mac OSX
VMS
Unix
要调度的进程类型¶
交互过程
他们的大部分时间都在 not ready 州政府。
等待I/O操作完成或等待用户交互
CPU密集型进程
他们的大部分时间都处于“就绪”状态。
在很大程度上受CPU限制。
抢占式调度关键字¶
Time Quantum -程序在调度决策之前运行的分配时间片。通常小于或等于时钟滴答。
Clock -调度算法的两个触发器之一。在大多数CPU上,时钟的运行频率为50-100赫兹。每个时钟节拍都会发出一个硬件中断,允许操作系统运行调度程序
Context Switch -通过软件或硬件中断,进程从用户模式切换到内核模式或从内核模式切换到用户模式的过程
进程状态¶
正在运行-当前在一个或多个CPU上执行
Ready-已准备好执行,但尚未运行
未准备好-未准备好运行,当前正在等待事件
已终止-进程已退出并正在清理
选择量子¶
要考虑的变量
上下文切换/调度器开销
量子长度
进程数
总开销:如果开销为5ms,最大量程为20ms,则开销为20%。如果量程为50ms,则开销仅为10%
平均响应时间:如果开销为5ms,量程为20ms,且存在5个活动进程,则运行间隔时间为:(开销+量程)*(可运行进程-1)=100ms。如果量程减少到10ms,那么两次运行之间的时间将是:60ms
因此,选择较小的量子将使系统反应更灵敏,而较长的量子将使系统更有效
上下文切换¶
上下文切换是程序保存其状态以切换到操作系统的过程
上下文切换是由软件和硬件中断引起的
上下文切换--它的工作原理¶
将当前运行进程的CPU寄存器保存到进程表中。
将进程状态更改为
准备好的
如果上下文切换是由硬件中断引起的
如果上下文切换是由软件中断引起的,并且内核可以立即返回(非阻塞调用)
未准备好
如果上下文切换是由软件中断引起的,并且内核无法立即返回(阻塞调用)
调用调度程序以查找“就绪”进程,并将其状态更改为“正在运行”
恢复新进程的寄存器并切换回用户模式。
抢占程度¶
不同的操作系统具有不同程度的抢占。
在更简单的操作系统中,用户模式任务可以被抢占,但内核模式任务不能。
允许内核模式任务被抢占的系统将响应更快
具有抢占式内核的系统:
Linux自2.6(2003)以来
自NT4以来的Windows NT(1996)
Solaris 2.0(我想是1991年)
AIX
一些BSD系统(NetBSD从v5开始,其他系统不确定)
可以考虑进行调度的两个单元是线程和进程
一些操作系统只在进程级别上调度,不单独考虑线程(MINIX会这样做)
其他操作系统按线程级别进行调度(Linux、Windows、OSX)
轮询进程调度¶
循环调度是最简单的调度策略,但不是最高效的
操作系统维护两个列表:
可运行列表
不可运行列表
操作系统只是简单地运行可运行列表,以便一次一个地执行每个进程。(对于N个CPU,一次N个)
多个队列的调度¶
可运行的线程根据以下条件被分成队列:
量子长度
进程/线程优先级
然后对每个队列进行循环调度
算法(伪):
thread schedule(thread interruptedThread) {
let highest = 0, lowest = 9;
Queue runQueue(10);
interruptedThread.state = runnable or blocked
queue(interruptedThread.priority).enqueue(interruptedThread)
for(int i = highest; i <= lowest; i++) {
if(queue(i) has any runnable threads) {
thread t = queue.dequeue();
t.state = running;
return t;
}
}
}
这种调度算法有哪些问题?
如果优先级较高的线程始终可运行,会发生什么情况?
我们如何给予没有使用其全部量程(I/O限制)的进程更高的优先级?
改进算法(伪):
thread schedule(thread interruptedThread) {
let highest = 0, lowest = 9;
Queue runQueue(10);
if(interruptedThread.quantumUsed « Quantum) {
interruptedThread.priority = max(interruptedThread.priority+1, highest);
}
interruptedThread.state = runnable or blocked
queue(interruptedThread.priority).enqueue(interruptedThread)
for(int i = highest; i «= lowest; i++) {
if(queue(i) has any runnable threads) {
thread t = queue.dequeue();
t.state = running;
t.priority -= 1;
if(t.priority != t.basePriority && t.priority »= lowest) {
t.priority = t.basePriority;
}
return t;
}
}
}
这个调度程序更好的原因是它完成了两件事:
它提高了未完全使用其分配的线程数量(通常为I/O限制)的线程的优先级
如果线程正在运行,则其优先级会暂时降低。线程的优先级越高,它在到达最低队列之前运行的机会就越多。此外,这还可以确保在某个时刻运行所有就绪的进程。
这种类型的调度有许多变化,它们试图微调线程优先级的增加或减少的速率。最典型的增强是根据优先级更改的次数增加或减少优先级更改量。
实时调度程序¶
这在实时操作系统中最常见,在实时操作系统中,进程最重要的方面不是它的优先级,而是完成一个工作单元的最后期限。
实时进程的属性:
到达时间(某些绝对时间)
截止日期(相对于到达时间的一段时间)
执行要求
计算时间
完成系统调用的时间
实时调度器的目标是确保尽可能多的进程在截止日期之前得到它们的全部执行需求。
这并不总是可能的(两个进程以100ms的要求同时到达,两者的最后期限都相隔120ms)。
在实时调度器中,在截止日期之前完成所有任务是最重要的目标。下一个重要目标是实现高CPU利用率。
条款:
利用率-执行时间除以进程到达率(进入可运行状态)的总和
可调度--如果系统利用率低于100%,则一组进程是可调度的
示例:
PA需要2个时间单位,到达时间t=0,5,10,15,...
PB需要1个时间单位,到达时间t=2,4,6,8,10,...
利用率为:2/5+1/2=90%。因此,该系统是可调度的。
如果Pc被相加,需要3个时间单位,并且到达t=0,5,10,15,...则利用率为2/5+3/5+1/2=150%,并且系统不可调度。(至少有些流程会错过最后期限)

真实世界RTS问题示例¶
实例问题:防抱死制动系统。
问题描述:
每个车轮都有一个传感器,每隔15毫秒报告一次车轮速度
一个额外的传感器每15毫秒报告一次车辆速度。记录值需要1毫秒。
车轮角速度为(车轮速度)/(车轮半径)
车角速度为(车速)/(车轮半径)
车轮滑移率为1-(车轮角速度)/(车辆角速度)
当滑移量为1时,轮子被锁定。理想滑移率为0.2。
工程师报告说,滑移可能以每50毫秒0.1的速度变化
调整所有轮胎的防抱死刹车需要6毫秒。
这个系统的调度要求是什么?
流程是什么?
流程的到达率和截止日期是多少?
我们需要更快的传感器吗?
我们能否通过以下方式节省资金:
获得速度较慢的CPU?
感应器变慢了吗?
得到一个反应较慢的ABS系统?
现实世界中RTS问题的实例解¶
传感器 [A-D] :周期=15毫秒,要求=1毫秒
传感器 [V] :周期=15毫秒,要求=1毫秒
在15ms*2+5ms=35ms的周期内,每个轮胎可以采集和记录2个样本(第一个记录周期与第二个读数重叠,因此我们不计算)
如果发现问题,我们可以安排一个过程来调整防抱死刹车,这将需要6毫秒。35ms+6ms=41ms。这比50ms的滑移变化速度更快。
这是可调度的吗?1/15+1/15+1/15+1/15+1/15+6/35=50.47%。是!
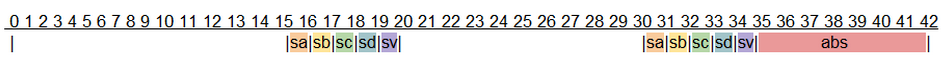
看起来我们也有
在截止日期前8毫秒的额外时间
每42毫秒有25毫秒的空闲CPU时间
因此,我们可以通过使用速度较慢的CPU、ABS和/或传感器来节省资金。
实时调度器实现的类型¶
最早的截止日期优先
处理流程运行时间和到达率的估计。
当系统利用率超过100%时,哪些进程错过最后期限是不可预测的
固定优先级
每当任务处于就绪状态时,给予最高优先级的任务CPU。
如果利用率超过100%,则较低优先级的任务将无法在最后期限内完成。这更容易预测,因此更容易受到青睐。
实施起来更简单
高级调度程序实施中的其他问题¶
在更高级的操作系统中,除了考虑优先级之外,还需要在调度程序中考虑其他问题
CPU/核心亲和性
进程的工作集中有多少页是驻留的
NUMA
如果先前在给定内核上调度了进程:
它的一些页面很有可能仍在L1/L2/L3缓存中。
在该CPU上再次调度总比不调度要好。
但是,如果在一个CPU上组合了太多进程,则需要迁移它们。
NUMA=非统一内存访问
这在具有独立物理CPU的计算机中很常见
每个CPU都有一条连接到一组CPU的内存总线。
这意味着,对于给定的CPU,一些内存速度较快,而一些内存速度较慢。
当选择在其上执行的CPU时,在哪里分配页面很重要。
此外,当操作系统分配页面时,考虑到以前使用过哪个NUMA区域以及它的拥挤/繁忙程度也很重要。
Linux中的进程优先级和调度¶
Linux调度程序有几个可用的策略:
正常政策:
SCHED_OTHER-轮询分时策略SCHED_BATCH-批量策略SCHED_IDLE-用于运行优先级很低的后台作业
实时策略:
SCHED_FIFO--先进先出政策SCHED_RR-轮询
调度策略受以下因素控制:
int sched_setscheduler(pid_t pid, int policy, sched_param *param);这个
sched_param结构,除其他事项外,还采用优先级值此优先级值仅由实时调度程序使用
正常的政策利用 nice 值
Linux实时调度器¶
在Linux中,实时进程始终优先于非实时进程。
SCHED_FIFO每个优先级有一个FIFO队列
当调用sched_setScheduler时,该进程进入队列的前面。
如果进程被抢占,它将保留其在队列中的位置。
如果调用了SCHED_YIELD,则进程移到队列的后面。
一旦运行,该进程将继续运行,直到:
优先级更高的进程变得可运行
该进程发出I/O请求
该进程调用sched_Year()
SCHED_FIFO通过RLIMIT_RTTIME限制防止进程锁定系统。这是一个进程在发出系统调用之前可能占用的CPU时间限制。在达到此软限制后,进程会多次发出信号,直到达到硬限制。如果达到硬限制,该进程将被终止。
SCHED_RR:完全相同于
SCHED_FIFO,但以下情况除外:每个过程都有一个有限的量。
如果进程被抢占,它将移到队列的后面
Linux抢占式调度器¶
SCHED_OTHER:这是Linux中的默认调度策略。
用途 nice 优先排序的值。
SCHED_BATCH:相同于
SCHED_OTHER,除了..。通知调度程序该进程既不是交互式进程,也不是I/O密集型进程
SCHED_IDLE:相同于
SCHED_OTHER,除了..。此类中的所有进程的优先级始终低于所有其他进程。这意味着,如果有任何其他进程可运行,则这些进程不会运行。
nice 值被完全忽略
物美价廉¶
所有Unix调度程序的共同之处是使用 nice 价值观。
NICE值是进程的优先级。
最高优先级为-20
最低优先级为19
典型的默认优先级为0。
当进程调用fork()时,新进程继承父进程的NICE值。
非根进程可以增加NICE值
只有根进程才能降低NICE值
NICE值的影响因调度程序实现的不同而不同,并且不是调度决策中考虑的唯一因素
Windows环境下的进程调度¶
Windows有6个进程类,每个类中有7个优先级
班级:
空闲
低于正常
正常
高于正常
高
实时
低于-高:
在类内,处理相对于优先级的分时
除非较高级别不可运行(或有其他空闲的CPU),否则不会运行较低级别
IDLE-仅在没有其他进程可运行时运行
实时-始终在可运行时运行,在进程进行系统调用或进入休眠之前不会中断。
进程调度程序在以下方面考虑了NUMA:
XP专业版,Windows Vista,7
服务器2003/2008/2008R2
通过使用处理器组,在Server 2008R2中支持在具有64个以上CPU的系统上进行更高级的堆管理和调度
多媒体班级计划程序服务:
创建具有操作系统必须满足的最低CPU要求的进程类。
通常用于确保音频、视频等。在存在较高系统负载的情况下具有响应能力。
用户模式调度程序¶
用户模式调度程序分为两类:
每个进程:每个1个进程有N个用户线程(总共有N个线程)
每个线程:每个内核线程有N个用户线程(N*K个线程)
选项:
窗口:
UMS调度程序组件-64位服务器2k8、Win 7
纤维
Linux/Minix
GNU PTH
海关:
使用setJump、LongjMP函数保存/切换堆栈
用户模式线程:为什么?¶
在不支持内核线程的系统上非常有用:
Minix、Windows 3.x、Mac OS 5-9
在线程数量巨大或不稳定的系统上非常有用:
具有24-32个活动线程且不经常创建和销毁线程的8-CPU系统运行得非常好。
具有2000个线程的8 CPU系统将逐渐停止。
一个8-CPU系统有10个线程,然后是120个线程,然后是5个线程,这将浪费大量时间来创建和销毁线程。
与内核线程相比,创建和销毁用户模式线程的成本相对较低。
像Erlang或其他创建大量并行组件的系统能够抽象无限数量的线程,而不需要实际提取那么多线程,这对系统有很大好处。
用户模式线程:有何不可?¶
用户模式线程的并行度低于内核模式线程。如果一个内核线程上有10个用户线程,那么您仍然只能在一个CPU上执行
用户模式线程不会受益于操作系统调度程序的优势:
关于CPU消耗的知识
关于内存利用率的知识
关于页表和NUMA配置的知识
如果一个用户模式线程锁定,它将锁定其整个内核线程。该内核线程上的其他用户模式线程无法继续。
如果一个用户模式线程进行系统调用,则用户模式线程库或应用程序必须使用异步I/O函数调用(更复杂)来维护其他用户模式线程的响应性。否则,整个内核线程将被阻塞。
对于处理数字的应用程序来说,用户模式线程的性能不如类似数量的内核线程(除非每个CPU的数量是»4)
这是因为内核线程比用户模式线程具有更长的量程。用户模式线程划分一个内核模式线程的量程。
对于交互式、基于I/O或混合的应用程序,这个问题并不那么重要。
GNU-PTH-用户模式线程¶
GNU PTH与普通POSIX线程库的映射非常接近。
GNU PTH的用法可能最好用一个例子来说明。
有趣的调用是(PTH_ACCEPT、PTH_WRITE和PTH_SLEEP)。
因为这个程序是受I/O限制的,所以我们需要使用异步I/O调用来确保所有线程都响应。
这是通过PTH_*调用(如PTH_WRITE、PTH_ACCEPT)实现的。
这些调用是正常系统调用的异步包装。
PThreads-内核线程¶
大多数符合POSIX标准的系统都实现了一个p线程库。
在Minix中,PThree库利用了位于PTH之上的一层。
在Linux中,PThread使用CLONE()系统调用创建轻量级进程(也称为内核线程)。
示例
此示例改编自 LLNL POSIX Threads Programming tutorial 。您可以在我们的 systems-code-examples 中的存储库 llnl_pthreads_examples 文件夹,这些文件已更新为干净地编译并具有正确的构建文件。