numpy.random.RandomState.lognormal¶
方法
-
RandomState.lognormal(mean=0.0, sigma=1.0, size=None)¶ 从对数正态分布中提取样本。
从对数正态分布中提取具有指定平均值、标准偏差和阵列形状的样本。请注意,平均值和标准偏差不是分布本身的值,而是由其得出的基本正态分布的值。
参数: - mean : 浮点数或类似浮点数的数组,可选
潜在正态分布的平均值。默认值为0。
- 西格玛 : 浮点数或类似浮点数的数组,可选
下伏正态分布的标准差。应大于零。默认值为1。
- size : int或int的元组,可选
输出形状。如果给定的形状是,例如,
(m, n, k)然后m * n * k取样。如果尺寸是None(默认),如果mean和sigma都是标量。否则,np.broadcast(mean, sigma).size取样。
返回: - out : ndarray或scalar
从参数化对数正态分布中提取样本。
参见
scipy.stats.lognorm- 概率密度函数、分布、累积密度函数等。
笔记
变量 x 具有对数正态分布,如果 log(x) 是正态分布的。对数正态分布的概率密度函数为:
p(x)=frac 1 sigma x sqrt 2 pi e ^(-frac(ln(x)-mu)^2 2 sigma^2)
在哪里? \mu 是均值和 \sigma 是变量的正态分布对数的标准偏差。如果随机变量是 产品 如果变量是 sum 大量独立的、相同分布的变量。
工具书类
[1] Limpert,E.、Stahel,W.A.和Abbt,M.,“记录整个科学的正态分布:关键和线索”,生物科学,第51卷,第5期,2001年5月。https://stat.ethz.ch/~stahel/lognormal/bioscience.pdf网站 [2] Reiss,R.D.和Thomas,M.,“极端值的统计分析”,巴塞尔:Birkhauser Verlag,2001年,第31-32页。 实例
从分发中抽取样本:
>>> mu, sigma = 3., 1. # mean and standard deviation >>> s = np.random.lognormal(mu, sigma, 1000)
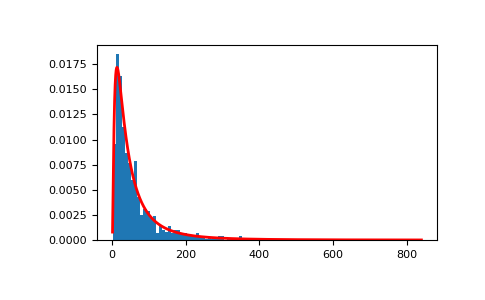
显示样本的直方图,以及概率密度函数:
>>> import matplotlib.pyplot as plt >>> count, bins, ignored = plt.hist(s, 100, density=True, align='mid')
>>> x = np.linspace(min(bins), max(bins), 10000) >>> pdf = (np.exp(-(np.log(x) - mu)**2 / (2 * sigma**2)) ... / (x * sigma * np.sqrt(2 * np.pi)))
>>> plt.plot(x, pdf, linewidth=2, color='r') >>> plt.axis('tight') >>> plt.show()
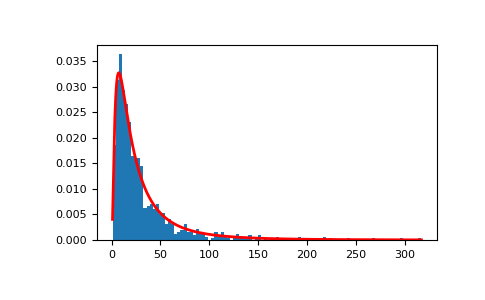
证明了用对数正态概率密度函数从均匀分布中提取随机样本的乘积可以很好地拟合。
>>> # Generate a thousand samples: each is the product of 100 random >>> # values, drawn from a normal distribution. >>> b = [] >>> for i in range(1000): ... a = 10. + np.random.random(100) ... b.append(np.product(a))
>>> b = np.array(b) / np.min(b) # scale values to be positive >>> count, bins, ignored = plt.hist(b, 100, density=True, align='mid') >>> sigma = np.std(np.log(b)) >>> mu = np.mean(np.log(b))
>>> x = np.linspace(min(bins), max(bins), 10000) >>> pdf = (np.exp(-(np.log(x) - mu)**2 / (2 * sigma**2)) ... / (x * sigma * np.sqrt(2 * np.pi)))
>>> plt.plot(x, pdf, color='r', linewidth=2) >>> plt.show()