numpy.random.RandomState.laplace¶
方法
-
RandomState.laplace(loc=0.0, scale=1.0, size=None)¶ 从拉普拉斯或双指数分布中提取具有指定位置(或平均值)和刻度(衰减)的样本。
拉普拉斯分布类似于高斯/正态分布,但在峰值处更明显,尾部更粗。它表示两个独立的、相同分布的指数随机变量之间的差异。
参数: - loc : 浮点数或类似浮点数的数组,可选
位置, \mu ,分布峰。默认值为0。
- 规模 : 浮点数或类似浮点数的数组,可选
\lambda 指数衰减。默认值为1。
- size : int或int的元组,可选
输出形状。如果给定的形状是,例如,
(m, n, k)然后m * n * k取样。如果尺寸是None(默认),如果loc和scale都是标量。否则,np.broadcast(loc, scale).size取样。
返回: - out : ndarray或scalar
从参数化拉普拉斯分布中提取样本。
笔记
它有概率密度函数
f(x;mu,lambda)=frac 1 2lambda expleft(-frac x-mu lambda right)。
1774年拉普拉斯第一定律指出,误差的频率可以表示为误差绝对大小的指数函数,从而得出拉普拉斯分布。对于经济学和卫生科学中的许多问题,这种分布似乎比标准高斯分布更好地模拟数据。
工具书类
[1] Abramowitz,M.和Stegun,I.A.(编辑)。《数学函数与公式、图表和数学表手册》,第9版,纽约:多佛,1972年。 [2] Kotz、Samuel等。”拉普拉斯分布和推广“,Birkhauser,2001. [3] 拉普拉斯分布〉,摘自《数学世界——沃尔夫拉姆网络资源》。http://mathworld.wolfram.com/laplacedistribution.html [4] 维基百科,“拉普拉斯分布”,https://en.wikipedia.org/wiki/laplace_distribution 实例
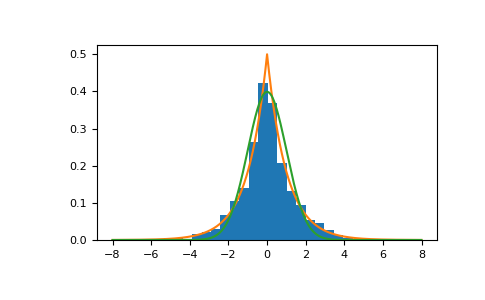
从分发中提取样本
>>> loc, scale = 0., 1. >>> s = np.random.laplace(loc, scale, 1000)
显示样本的直方图,以及概率密度函数:
>>> import matplotlib.pyplot as plt >>> count, bins, ignored = plt.hist(s, 30, density=True) >>> x = np.arange(-8., 8., .01) >>> pdf = np.exp(-abs(x-loc)/scale)/(2.*scale) >>> plt.plot(x, pdf)
绘制高斯图进行比较:
>>> g = (1/(scale * np.sqrt(2 * np.pi)) * ... np.exp(-(x - loc)**2 / (2 * scale**2))) >>> plt.plot(x,g)