自然语言工具包¶
NLTK是一个领先的平台,用于构建用于处理人类语言数据的Python程序。它为 over 50 corpora and lexical resources 例如WordNet,以及一套用于分类、标记化技术、词干、标记、解析和语义推理的文本处理库,工业级NLP库的包装器,以及 discussion forum .
由于有一个介绍编程基础知识的实践指南以及计算语言学的主题,加上全面的API文档,NLTK适合语言学家、工程师、学生、教育工作者、研究人员和行业用户。NLTK可用于Windows、Mac OS X和Linux。最重要的是,NLTK是一个免费的、开源的、社区驱动的项目。
NLTK被称为“使用Python进行计算语言学教学和工作的极好工具”,以及“使用自然语言的令人惊叹的库”。
Natural Language Processing with Python 提供了语言处理编程的实用介绍。它由NLTK的创建者编写,指导读者完成编写python程序、使用语料库、对文本进行分类、分析语言结构等的基础知识。这本书的在线版本已经针对python 3和nltk 3进行了更新。(原始的python 2版本仍然可以在 http://nltk.org/book_1ed )
使用NLTK可以做一些简单的事情¶
标记和标记一些文本:
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]
标识命名实体:
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
显示分析树:
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()
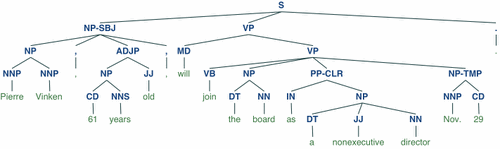
铌。如果您发布使用NLTK的作品,请引用以下NLTK书籍:
Bird、Steven、Edward Loper和Ewan Klein(2009年), 用python进行自然语言处理 . O'Reilly媒体公司