6. 解释映射文件语法¶
有关lark的详细介绍,mappyfile使用的通用解析库请参见 Lark reference page .
完整的mapfile语法文件显示在本页末尾。可以看到最新版本在 here on GitHub .
6.1. 一个简单的例子¶
理解解析器和语法如何工作的最简单方法是通过一个简短的例子。我们将使用下面的mapfile片段来解析并转换为ast(抽象语法树)。
MAP
NAME 'Test'
END
这将生成以下树(单击可查看完整版本)。

树存储为python对象,如下所示:
Tree(start, [Tree(composite, [Tree(composite_type, [Token(__MAP39, 'MAP')]),
Tree(composite_body, [Tree(attr, [Token(UNQUOTED_STRING, 'NAME'),
Tree(string, [Token(SINGLE_QUOTED_STRING, "'Test'")])])])])])
其格式如下:
start
composite
composite_type MAP
composite_body
attr
NAME
string 'Test'
语法文件包含规则和 terminals ,解析器将它们与输入文本匹配以创建树。
现在我们将介绍与示例映射文件匹配的所有规则。
第一法则 start 将始终位于树的根:
start: composite+
规则检查 composite 规则,后面跟一个加号,表示应该在输入中找到一个或多个复合类型。
接下来我们来看看 composite 规则:
composite: composite_type composite_body _END
| metadata
| validation
此规则由选项列表匹配-每个选项都在自己的行上,以***(管道)字符开头。在编写或调试语法时,可以注释掉选项,以查看哪个选项与特定输入匹配。
在我们的示例中,mapfile与第一个选项匹配 composite_type composite_body _END ,可分为以下几部分:
一
composite_type规则(在本例中MAP)一
composite_body规则这个
_END终端(文字字符串“end”)
当每个规则在树上创建一个新分支时,会从 start 分支创建一个新的 composite 分支。
!composite_type: "CLASS"i // i here is used for case insensitive matches, so CLASS, Class, or class will all be matched
| "CLUSTER"i
| "MAP"i
// list cut for brevity
这个 composite_type 规则还有一个选项列表,但在本例中是由字符串文本组成的。!**规则名称之前表示规则将保留所有终端。没有*!**树如下所示-注意 composite_type 分支中缺少 MAP 值。

接下来让我们看看 attr 规则:
attr: attr_name value+
这包括另外两条规则。安 attr_name 与一个或多个匹配 value 规则(如上所述,+表示一个或多个匹配项)。一个新的 attr 分支以这些规则作为子级添加到树中。
这个 attr_name 规则如下:
attr_name: NAME | composite_type
在我们的示例中,规则与 NAME 终端匹配(备选方案是 composite_type )这是使用正则表达式来匹配字符串定义的:
NAME: /[a-z_][a-z0-9_]*/i
正则表达式可以解释为:
[a-z_]-从A到Z的单个字母或下划线[a-z0-9_]-从A到Z的单个字母、从0到9的数字或下划线这个
*表示零到多个匹配项这个
i表示不区分大小写的搜索
因此,以下字符串都将匹配: NAME, name, Name, NAME_, MY_NAME 然而 'NAME', My Name, N@me 不会。
在我们的示例中匹配的最后一个规则是 value 规则。
?value: bare_string | string | int | float | expression | not_expression | attr_bind | path | regexp | runtime_var | list
规则之前的 ?,如果它有一个子级,则会导致它“内联”。这意味着没有为 value 规则及其子级将直接添加到分支。带有“inlining”的树会导致:

而且没有内嵌(the**?**字符)。 value 分支出现:

这个例子涵盖了语法文件中的大量规则,并希望为理解更复杂的规则提供基础。
6.2. 终端¶
终端在语法文件中以大写显示。它们用于使用字符串文本、正则表达式或其他终端的组合来匹配标记。
如果终端以下划线开头,它不会出现在树中,例如每个复合类型的闭合块:
_END: "END"i
许多终端使用正则表达式来匹配令牌。网站https://regex101.com/提供了这些有用的解释。记住设置python的“风格”,并删除周围的前斜杠。
例如,获取 COMMENT: /\#[^\n]*/ 进入 \#[^\n]* :
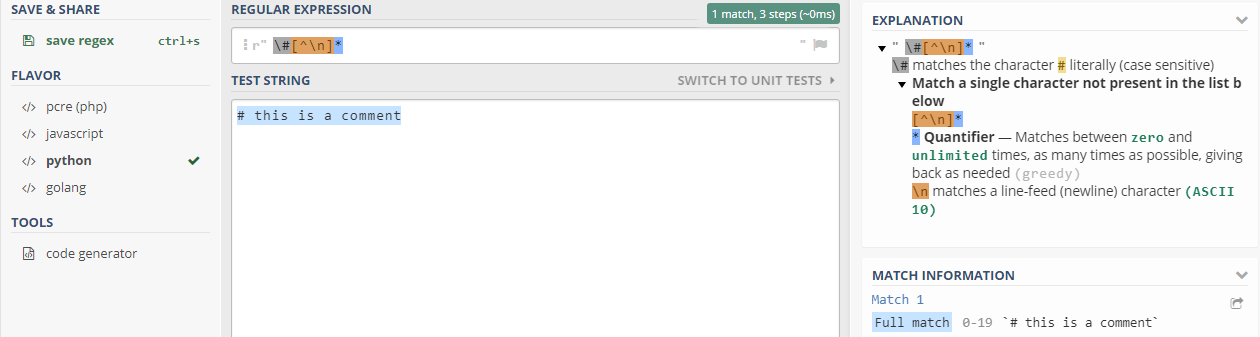
一些进一步的解释如下:
// check for path names e.g. /root/logs
PATH: /[a-z_]*[.\/][a-z0-9_\/.]+/i
6.3. 杂记说明¶
规则可以递归匹配,因此
composite_body可以包含一个_composite_item反过来又会是另一个composite. 这允许我们分析嵌套的复合类型,例如CLASS在一个LAYER在一个MAP.
composite_body: _composite_item*
_composite_item: (composite|attr|points|projection|metadata|pattern|validation|values) _NL+
有一些常见的导入规则。这些可以在https://github.com/erezsh/lark/blob/master/lark/grammars/common.g.上找到。例如:
%import common.INT
// this is defined in common.g as follows
DIGIT: "0".."9"
INT: DIGIT+
6.4. 语法文件¶
完整的映射文件语法如下所示。
// =================================================================
//
// Authors: Erez Shinan, Seth Girvin
//
// Copyright (c) 2020 Seth Girvin
//
// Permission is hereby granted, free of charge, to any person
// obtaining a copy of this software and associated documentation
// files (the "Software"), to deal in the Software without
// restriction, including without limitation the rights to use,
// copy, modify, merge, publish, distribute, sublicense, and/or sell
// copies of the Software, and to permit persons to whom the
// Software is furnished to do so, subject to the following
// conditions:
//
// The above copyright notice and this permission notice shall be
// included in all copies or substantial portions of the Software.
//
// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
// EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
// OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
// NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
// HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
// WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
// FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
// OTHER DEALINGS IN THE SOFTWARE.
//
// =================================================================
start: "SYMBOLSET"i composite_body _END -> symbolset
| composite+
composite: composite_type composite_body _END
| metadata
| validation
| connectionoptions
composite_body: _composite_item*
_composite_item: (composite|attr|points|projection|pattern|values|config)
!projection: "PROJECTION"i (string*|AUTO) _END
!config: "CONFIG"i (string | UNQUOTED_STRING) (string | UNQUOTED_STRING)
!points: "POINTS"i num_pair* _END
!pattern: "PATTERN"i num_pair* _END
!values: "VALUES"i string_pair* _END
!metadata: "METADATA"i string_pair* _END
!validation: "VALIDATION"i string_pair* _END
!connectionoptions: "CONNECTIONOPTIONS"i string_pair* _END
attr: (UNQUOTED_STRING | composite_type) (value | UNQUOTED_STRING)
//attr: (UNQUOTED_STRING | SYMBOL) (value | UNQUOTED_STRING)
// SYMBOL is listed in composite_type but is also an attribute name
?value: string | int | float | expression | not_expression | attr_bind | path
| regexp | runtime_var | list | NULL | true | false | extent | rgb | hexcolor
| colorrange | hexcolorrange | num_pair | attr_bind_pair | _attr_keyword
int: SIGNED_INT
int_pair: int int
rgb: int int int
colorrange: int int int int int int
hexcolorrange: hexcolor hexcolor
hexcolor: DOUBLE_QUOTED_HEXCOLOR | SINGLE_QUOTED_HEXCOLOR
extent: (int|float) (int|float) (int|float) (int|float)
!_attr_keyword: "AUTO"i | "HILITE"i | "SELECTED"i
string: DOUBLE_QUOTED_STRING | SINGLE_QUOTED_STRING | ESCAPED_STRING
string_pair: (string|UNQUOTED_STRING) (string|UNQUOTED_STRING)
attr_bind_pair: attr_bind attr_bind
float: SIGNED_FLOAT
float_pair: float float
path: PATH
regexp: REGEXP1 | REGEXP2
runtime_var: RUNTIME_VAR
list: "{" (value | UNQUOTED_STRING_SPACE) ("," (value | UNQUOTED_STRING_SPACE))* "}"
num_pair: (int|float) (int|float)
attr_bind: "[" UNQUOTED_STRING "]"
not_expression: ("!"|"NOT"i) comparison
expression: "(" or_test ")"
?or_test : (or_test ("OR"i|"||"))? and_test
?and_test : (and_test ("AND"i|"&&"))? comparison
?comparison: (comparison compare_op)? sum
!compare_op: ">=" | "<" | "=*" | "==" | "=" | "!=" | "~" | "~*" | ">" | "%"
| "<=" | "IN"i | "NE"i | "EQ"i | "LE"i | "LT"i | "GE"i | "GT"i | "LIKE"i
?sum: product
| sum "+" product -> add
| sum "-" product -> sub
?product: unary_expr
| product "*" unary_expr -> mul
| product "/" unary_expr -> div
| product "^" unary_expr -> power
?unary_expr: atom
| "-" unary_expr -> neg
| "+" unary_expr
?atom: (func_call | value)
// ?multiply: (multiply "*")? (func_call | value)
func_call: UNQUOTED_STRING "(" func_params ")"
func_params: value ("," value)*
!true: "TRUE"i
!false: "FALSE"i
!composite_type: "CLASS"i
| "CLUSTER"i
| "COMPOSITE"i
| "FEATURE"i
| "GRID"i
| "JOIN"i
| "LABEL"i
| "LAYER"i
| "LEADER"i
| "LEGEND"i
| "MAP"i
| "OUTPUTFORMAT"i
| "QUERYMAP"i
| "REFERENCE"i
| "SCALEBAR"i
| "SCALETOKEN"i
| "STYLE"i
| "WEB"i
| "SYMBOL"i
AUTO: "AUTO"i
PATH: /([a-z0-9_]*\.*\/|[a-z0-9_]+[.\/])[a-z0-9_\/\.-]+/i
// rules allow optional alphachannel
DOUBLE_QUOTED_HEXCOLOR.2: /\"#(?:[0-9a-fA-F]{3}){1,2}([0-9a-fA-F]{2})?\"/
SINGLE_QUOTED_HEXCOLOR.2: /'#(?:[0-9a-fA-F]{3}){1,2}([0-9a-fA-F]{2})?'/
NULL: "NULL"i
SIGNED_FLOAT: ["-"|"+"] FLOAT
SIGNED_INT: ["-"|"+"] INT
INT: /[0-9]+(?![_a-zA-Z])/
%import common.FLOAT
// UNQUOTED_STRING: /[a-z_][a-z0-9_\-]*/i
UNQUOTED_STRING: /[a-z0-9_\xc0-\xff\-:]+/i
UNQUOTED_STRING_SPACE: /[a-z0-9\xc0-\xff_\-: ]+/i
DOUBLE_QUOTED_STRING: "\"" ("\\\""|/[^"]/)* "\"" "i"?
SINGLE_QUOTED_STRING: "'" ("\\'"|/[^']/)* "'" "i"?
ESCAPED_STRING: /`.*?`i?/
//KEYWORD: /[a-z]+/i
//UNQUOTED_NUMERIC_STRING: /[a-z_][a-z0-9_\-]*/i
REGEXP1.2: /\/.*?\/i?/
REGEXP2: /\\\\.*?\\\\i?/
RUNTIME_VAR: /%.*?%/
COMMENT: /\#[^\n]*/
CCOMMENT.3: /\/[*].*?[*]\//s
_END: "END"i
WS: /[ \t\f]+/
_NL: /[\r\n]+/
%ignore COMMENT
%ignore CCOMMENT
%ignore WS
%ignore _NL

