5. 程序表示和解释
在本章中,我们将讨论如何用特定语言表示并最终执行或解释程序。为此,我们需要讨论执行此操作所需的工具链,以及用我们的语言定义程序含义(语义)的技术。
5.1. 编程语言工具链
我们将首先概述编程语言的各个阶段 compilation / interpretation 工具链:
源代码(文件中存储的字符串)
词汇分析
令牌序列
语法分析(解析)
抽象语法树<-前端和后端接口
静电支票
优化
转换后的抽象语法树
代码生成
机器代码或字节代码
执行 在物理硬件、虚拟硬件或虚拟机上
替代方案: 直接解释抽象语法树
参考资料: Mogensen
5.1.1. 交叉编译
当目标环境没有提供足够的计算资源在目标环境本身中编译软件时,交叉编译是一种有用的技术。常见的示例包括移动电话和其他嵌入式设备。例如,人们通常在开发机器上开发Android应用程序,在Android虚拟设备(模拟器)上测试它们,然后将它们部署到实际的手机或平板电脑上。
下面的示例显示了在开发计算机上交叉编译一个小的C程序并在目标环境中执行的过程。
首先,我们在我们的开发机器上编译源代码,在本例中,是一个托管的Linux VM,使用 OpenWrt 嵌入式Linux工具链::
[laufer@boole:~/Work/hello] 130 $ cat hello.c main() { puts("hello ETL!"); } [laufer@boole:~/Work/hello] $ ~/Work/OpenWrt-SDK-15.05.1-ramips-rt305x_gcc-4.8-linaro_uClibc-0.9.33.2.Linux-x86_64/staging_dir/toolchain-mipsel_24kec+dsp_gcc-4.8-linaro_uClibc-0.9.33.2/bin/mipsel-openwrt-linux-uclibc-gcc hello.c现在,我们将生成的可执行文件部署到目标环境,比如说,
scp。最后,我们在一个基于MIPS的嵌入式Linux设备上本地运行此可执行文件,该设备作为“便携式旅行路由器”出售:
root@ExPodNano:~# ldd ./a.out libgcc_s.so.1 => /lib/libgcc_s.so.1 (0x770d5000) libc.so.0 => /lib/libc.so.0 (0x77069000) ld-uClibc.so.0 => /lib/ld-uClibc.so.0 (0x770f9000) root@ExPodNano:~# ./a.out hello ETL!
5.2. 编译器前端概念和技术
在本节中,我们将讨论关键的前端阶段、词法分析和语法分析,以及相关的概念和技术。
5.2.1. 词汇分析
正则表达式、NFA、DFA(Mogensen ch.2)
5.2.2. 语法分析
上下文无关文法,EBNF,解析(Mogensen ch.3)
5.2.3. 可选的前端方法
5.3. 编程语言语义学
语义学,形式化的 含义 一种特定语言的程序,包括 静电 和 动态的 语义学。
static semantics (编译时)
流量分析
打字
dynamic semantics (运行时)
外延
可操作的,例如我们的口译员
公理
解释器模式与动态语义的讨论有关。
5.4. 案例研究:一种简单的命令式语言
在本节中,我们将讨论简单命令式语言的解释器和编程环境的设计。
随附的讲座以一套截屏视频的形式提供:
5.4.1. 目标
我们正在为一种类似于JavaScript的语言构建一个解释器,该语言具有类似对象的特性。我们这样做有两个目的:
从“内部”理解面向对象的编程语言。
为了更好地理解我们通过在一个小但有点复杂的程序环境中使用它们而学到的面向对象和功能设计模式。
5.4.2. 语法
我们的语言有以下特点:
由BNF语法提供的整数表达式::
e ::= variable
| const
| e1 + e2
| e1 - e2
由BNF语法提供的语句::
S ::= x = e
| S1 ; S2
| while (e) S
到目前为止,在讲座的背景下,我们做了以下修改。我们向表达式添加了变量,因此我们可以处理如下情况 x + 3 ,而之前我们只能编写如下表达式 4 + 3 。我们还引入了赋值语句作为更改变量内容的一种方式。此外,我们还允许按顺序放置语句。我们还允许使用简单的While表达式,其中Guard是一个表达式,当Gurad表达式的计算结果为非零整数值时,执行循环体。
5.4.3. 结构化操作语义(SOS)
我们首先形式化玩具语言的直观执行语义。这样做的重点是在解释器中呈现基本思想,而不会被解释器的编程细节所束缚。无论如何,这些细节将在本课程的后面部分介绍。因为我们的玩具语言有变量,所以我们需要跟踪变量的状态。我们将变量视为具有两种功能的对象:
v.get() 返回变量的当前值
v.set(int i) changes the current value of the variable to that of i
我们考虑我们编写的程序的状态(内存存储 M ,作为将标识符与可变对象相关联的映射。
计算表达式的规则非常简单。
求值常量 c 。每个常量的计算结果都是它自己。
计算名称为的变量 x :检索变量对象(例如 v )与 x 从记忆库 M ,通过使用 M(x) 。所需的结果通过调用 v.get() 。
评估 e1 + e2 :评估 e1 第一,说要产生价值。 r1 。评估 e2 其次,说要产生价值。 r2 。必需的结果是数值 r1 + r2 。
评估 e1 - e2 :评估 e1 第一,说要产生价值。 r1 。评估 e2 其次,说要产生价值。 r2 。必需的结果是数值 r1 - r2 。
评估规则准确地写在下图中。

语句的执行规则如下。与表达式求值不同,语句执行不会产生结果。执行语句的主要结果是对存储的副作用,即。变量值的变化。
执行赋值语句:考虑赋值语句 x = e 。这里 e 是一种表达方式。步骤如下:首先,计算表达式 e 为了产生结果,比方说 r 。接下来,检索变量对象(比如 v )与 x 从记忆库 M ,通过使用 M(x) 。执行 v.set(r) 若要更改变量对象的值,请执行以下操作。
执行一系列语句 S1; S2 :执行 S1 第一。当它终止时,执行 S2 。
执行 while (e) do S :评估条件 e 产生一个结果 r 。如果 r 为零,则执行终止。否则,执行 S 然后重复这个过程。
执行规则如下图所示:


请注意,各种语句之间的联系是它们共享一个存储,即。在语句序列中 x = 2; y = x + 1 ,第二次引用 x 反映第一个赋值的效果,因为两个赋值语句之间存在(共享)存储。
5.4.4. 解释器程序
现在我们继续编写解释器程序。整个代码可以作为 misc-scala 举个例子。也可以使用类似的示例,但是基于F-代数并且具有更好的运行时错误处理: simpleimperative-algebraic-scala 。
5.5. 案例研究:带有记录的简单命令式语言
在本节中,我们将讨论带记录的简单命令式语言(如带有公共字段而不带方法的类)的解释器和编程环境的设计。
5.5.1. 目标
我们正在为一种类似于JavaScript的语言构建一个解释器,该语言具有类似对象的特性。我们这样做有两个目的:
从“内部”理解面向对象的编程语言。
为了更好地理解我们通过在一个小但有点复杂的程序环境中使用它们而学到的面向对象和功能设计模式。
我们现在考虑由于添加记录而引起的变化。因此,我们允许:
记录类型的声明
创建给定记录类型的新记录
记录字段的选择
表达式左侧和右侧记录的使用
5.5.2. 语法
我们的语言有以下特点:
下面的语法体现了我们语言的句法特点。在激励方面,我们感兴趣的计划示例如下:
StudentCourseRecord = record
int firstExamScore;
int secondExamScore;
int totalScore;
end;
StudentSemRecord = record
StudentCourseRecord course1;
StudentCourseRecord course2;
end;
StudentSemRecord r = new StudentSemRecord();
r.course1 = new StudentCourseRecord();
r.course1.firstExamScore = 25;
r.course1.secondExamScore = 35;
r.course1.totalScore = r.course1.firstExamScore + r.course1.secondExamScore;
r.course2 = r.course1;
在C语言中,这类东西称为结构。在熟悉的面向对象术语中,我们可以这样思考它们:
记录类型是其唯一成员是公共成员变量的类
记录是对象
字段是公共成员变量
上例中的记录类型定义在JAVA中如下所示,PROGRAM的睡觉将如下所示:
class StudentCourseRecord {
public int firstExamScore;
public int secondExamScore;
public int totalScore;
}
class StudentSemRecord {
public StudentCourseRecord course1;
public StudentCourseRecord course2;
}
形式上,我们通过以下BNF语法进行。为了简化我们的生活,我们将忽略类型信息。在这个BNF语法中,我们稍微小心地将L(Eft)值和R(Ight)值分开。L值是可以出现在赋值语句左侧的值,而R值是出现在赋值语句右侧的值。
记录定义由BNF语法给出::
Defn ::= record
FieldList
end
FieldList ::= fieldName, FieldList
| fieldName
L值(从记录中选择的字段以及变量)由BNF语法给出::
Lval ::= e.fieldName
| variable
表达式(R值)由BNF语法给出::
e ::= new C
| Lval
| const
| e1 + e2
| e1 - e2
语句由BNF语法给出::
S ::= Lval = e
| S1; S2
| while (e) do S
我们首先形式化玩具语言的直观执行语义。和以前一样,这样做的目的是在解释器中呈现基本思想,而不会被解释器的编程细节所束缚。无论如何,这些细节将在本课程的后面部分介绍。特别是,在最初的第一次削减中,我们将从忽略声明开始。另外,在这个新的演示文稿中
回想一下,我们将变量视为具有两种功能的对象:
get()返回变量的当前值
set(Int X)将变量的当前值更改为x的值
人们对记录也有类似的看法。

与前面一样,我们将程序的状态(我们将其写为S)视为将标识符与变量对象相关联的映射。此外,和以前一样,我们将评估和执行区分开来。在求值中,有两个子情况,求值为L值和求值为R值。

有两种方法可以获得L值。一种是通过变量,第二种是通过字段选择。
与变量名关联的L值是关联的变量对象。
通过首先将表达式e求值为R值(比方说r)来获得与选择E.f相关联的L值。接下来,使用字段名为f的记录r进行查找以获得所需的L值。
这些评估规则精确地写在下图中。

下面再次介绍了我们先前评估R值的规则。
评估L值。在我们的设置中,每个L值(比如l)都是一个从存储M获取的变量对象。执行l.get()来计算返回值。此规则包含变量的前一种情况。
求值e1+e2:先求值e1,比方说产生值v1。然后计算e2,比如说产出值v2。所需的结果是v1+v2。
评估e1-e2:首先评估e1,比方说产生值v1。然后计算e2,比如说产出值v2。所需的结果是v1-v2。
计算常数c。每个常数的计算结果都是它自己。

执行语句的规则如下。它们和以前看到的很相似。执行语句的主要结果仍然是对存储的副作用,即。变量值的变化。
执行赋值语句L=e。这里L是L值表达式,e是R值表达式。具体步骤如下。首先,计算表达式L以产生一个L值,比方说l。接下来,计算表达式e以产生一个R值,比方说v。接下来,使用l.set(V)来更改变量对象的值。
执行语句序列“S1;S2”和“WHILE”循环与前面一样。
执行规则如下图所示:

5.5.3. 实施
提供了实现带记录的简单命令式语言的全部代码 here 。
5.6. 类型系统
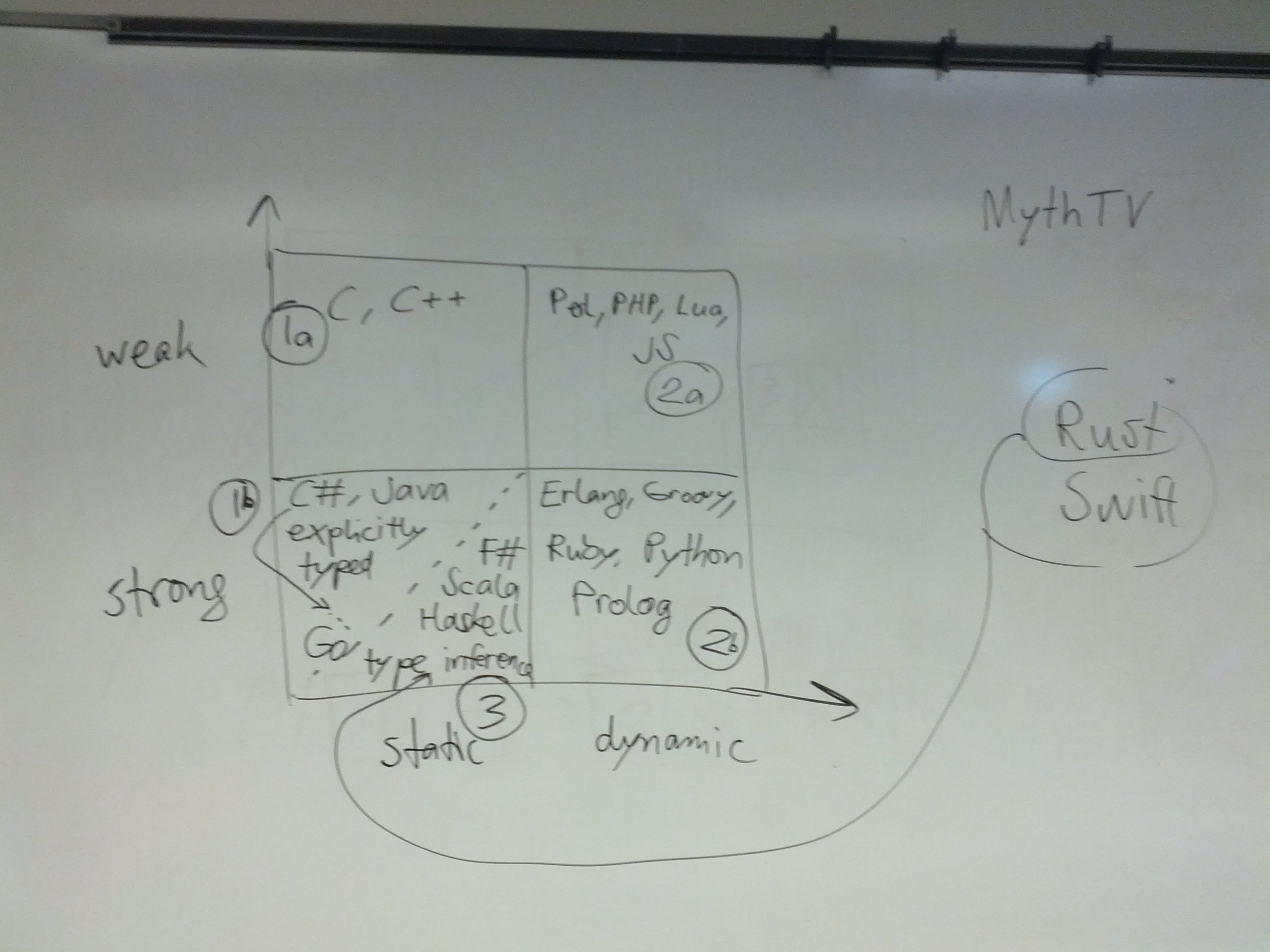
类型系统是编程语言的一个重要方面。我们在类型系统设计空间中确定以下维度:
静电与动态键入
强类型安全与弱类型安全
隐式类型信息与显式类型信息
名义类型等效与结构类型等效
有关更多信息,请访问此处:
待处理
阐述多态性的设计空间(Cardelli/Wegner)
5.7. 特定于领域的语言
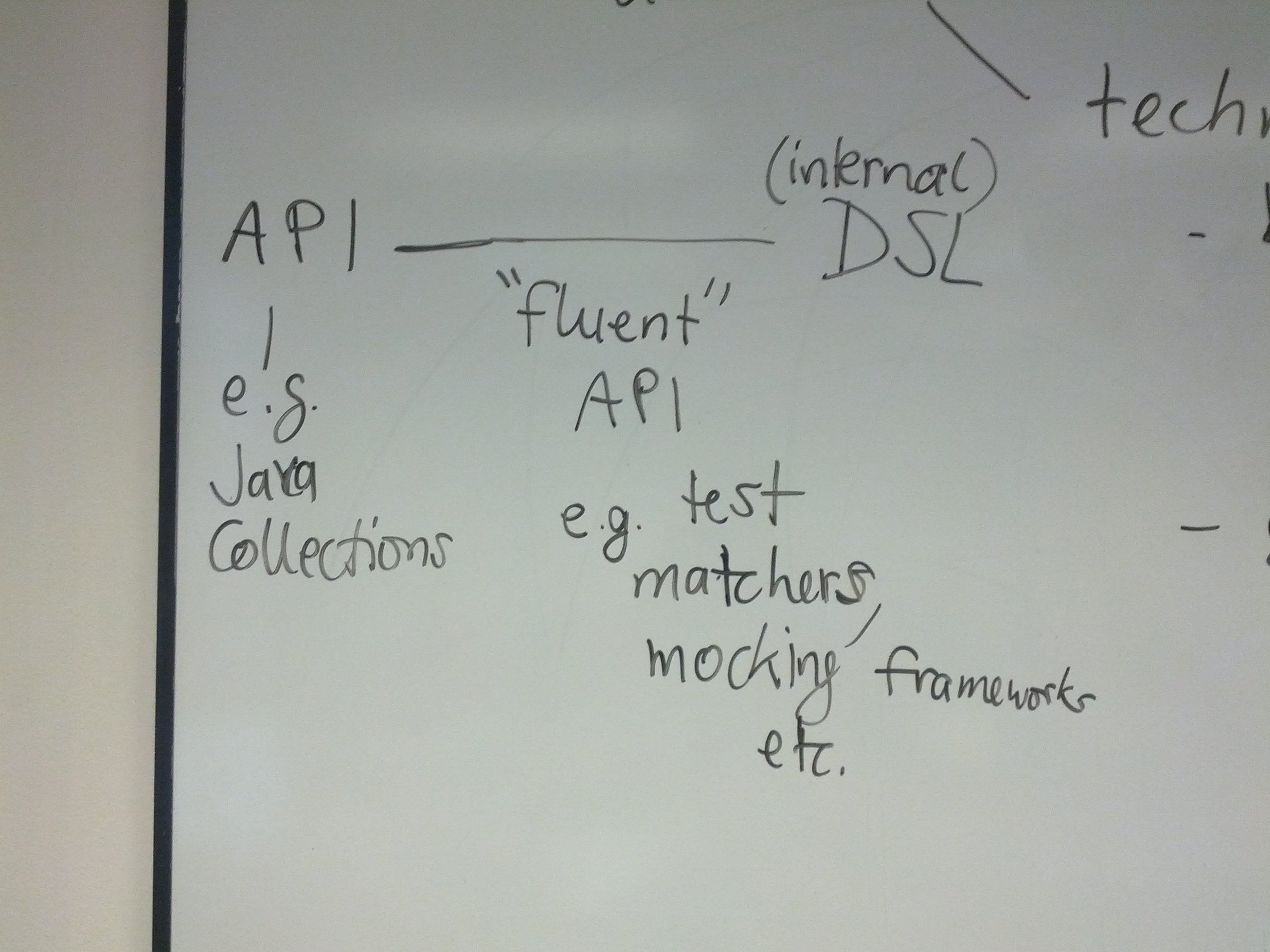
领域特定语言是解决特定领域问题的专用语言。我们确定以下维度:
内部/嵌入式语言与外部语言
业务领域与技术领域

此外,API和内部DSL之间存在一个连续体。
有关更多信息,请访问此处: