3. Scala中的命令式和面向对象范例
在本章中,我们将通过Scala中的示例讨论命令式和面向对象编程范例。
3.1. 运行Scala代码的选项
在本节中,我们将讨论运行Scala代码的不同选项,包括应用程序和测试。
运行Scala代码片段的最简单方式是通过Scala REPL(读取-求值-打印循环)。我们可以启动Scala REPL,然后计算定义和表达式:
$ scala Welcome to Scala 3.2.0 (17.0.4.1, Java OpenJDK 64-Bit Server VM). Type in expressions for evaluation. Or try :help. scala> 3 + 4 res0: Int = 7 scala> def f(x: Int) = x + 2 f: (x: Int)Int scala> f(3) res1: Int = 5 scala> val z = f(4) z: Int = 6 scala> Seq(1, 2, 3).map(f) res2: Seq[Int] = List(3, 4, 5)
这是进行初步探索的一种非常有效、无痛苦的方式。这种方法的缺点是缺乏对 托管依赖项 ,这是更高级的工作所需的。在这种情况下,通过SBT启动Scala REPL是一个更好的选择,如下所述。不鼓励手动管理Scala/Java类路径。
您还可以直接通过Scala解释器运行简单的脚本(带有可选的命令行参数)。一个
main方法或@main需要注解,例如::$ cat > blah.scala def main(args: Array[String]) = println(args.toList) $ scala blah.scala 1 2 3 List(1, 2, 3)
在像IntelliJ IDEA这样的Scala IDE中,我们可以运行Scala应用程序(带有
main方法)和Scala测试。要将命令行参数传递给应用程序,我们必须创建合适的运行配置。最好使用 sbt (Scala构建工具)用于具有一个或多个外部依赖关系的项目,因为SBT(和类似的构建工具)能够以声明方式管理这些依赖关系:
$ sbt test $ sbt run $ sbt "run arg1 arg2 ..." $ sbt "runMain my.pkg.Main arg1 arg2 ..." $ sbt test:run
此外,SBT允许您启动REPL,该REPL公开项目中的代码及其托管依赖项。这是浏览现有库的首选方式:
$ sbt console
您还可以从测试范围中拉入其他依赖项::
$ sbt test:console
如果您希望在发生编译时错误时绕过您自己的代码,您可以使用以下任务之一:
$ sbt consoleQuick $ sbt test:consoleQuick
与一个 text editor ,SBT的 triggered execution for test将显著缩短编辑-编译-运行/测试周期,例如:
$ sbt ... > ~ test
一般来说,无论您选择哪种开发环境,在基本REPL之外进行探索性编程的一种便捷方法是从单个测试开始。在那里,您可以发展您的想法,并与您想要探索的库API进行交互。对于简单的测试,您可以在代码中散布断言或使用所选测试框架提供的测试支持,例如, JUnit 或 ScalaTest 。因此,您可以开始探索测试中的某些内容,然后将其转移到您的生产代码中 (main folder) when appropriate. The list performance example 说明了这种方法。
最后,要将基于SBT的Scala应用程序转换为可以在SBT外部运行的脚本(控制台应用程序),可以使用 sbt-native-packager 插件。要使用此插件,请将此行添加到
build.sbt**enablePlugins(JavaAppPackaging)
而这一次是为了
project/plugins.sbt::addSbtPlugin("com.typesafe.sbt" % "sbt-native-packager" % "1.7.5")
然后,在对源代码进行任何更改后,您可以创建/更新脚本并从命令行运行它,如下所示:
$ sbt stage ... $ ./target/universal/stage/bin/myapp-scala arg1 arg2 ...
3.2. 控制台应用程序的角色
控制台应用程序一直是UNIX命令行环境的重要组成部分。典型的控制台应用程序通过以下方式与其环境交互:
零个或多个特定于应用程序 command-line arguments 要将选项传递给应用程序,请执行以下操作:
app arg1 arg2 ...标准输入 (Stdin)用于读取输入数据
标准输出 (Stdout)用于写入输出数据
标准误差 (Stderr),用于与输出数据分开显示错误消息
以这种方式编写的应用程序可以用作使用Unix管道的可组合构建块。使用这些标准I/O机制比读取或写入名称硬编码在程序中的文件要灵活得多。
例如, yes 命令始终在连续的输出行上输出其参数,则 head 命令输出其输入的有限前缀,而 wc 命令统计字符数、字数或行数:
yes hello | head -n 10 | wc -l
您可能想知道管道中的上游(左)阶段如何知道何时终止。具体地说, yes 命令知道在以下时间终止 head 阅读前十行。什么时候 head 在读取并通过指定数量的行后完成,则关闭其输入流,并且 yes 将收到错误信号,称为 SIGPIPE 当它尝试向该流写入更多数据时。对该错误信号的默认响应是终止。有关以下内容的更多详细信息 SIGPIPE ,见 this StackExchange response 。
我们也可以使用Shell中内置的控制结构。例如,以下循环打印从0开始的连续整数的无限序列:
n=0 ; while :; do echo $n ; ((n=n+1)) ; done
这些技术对于为我们自己的应用程序生成测试数据很有用。为此,我们可以使用以下语法将输出重定向到新创建的文件:
n=0 ; while :; do echo $n ; ((n=n+1)) ; done > testdata.txt
如果 testdata.txt 已存在,则在使用此语法时将覆盖它。我们还可以附加到现有文件::
... >> testdata.txt
同样,我们可以使用以下表示法重定向来自文件的输入::
wc -l < testdata.txt
在UNIX管道和函数式编程之间存在着密切的关系:当将控制台应用程序视为将其输入转换为其输出的函数时,UNIX管道对应于函数组合。这条管道 p | q 对应于函数组合 q o p 。
3.2.1. Scala中的控制台应用程序
以下技术对于在Scala中创建控制台应用程序非常有用。与Java一样,命令行参数可用于Scala应用程序,如下所示 args 类型的 Array[String] 。
我们可以使用此迭代器将标准输入读取为行::
val lines = scala.io.Source.stdin.getLines()
这为您提供了一个字符串迭代器,每个项目代表一行。当迭代器没有更多的项时,您就完成了对所有输入的读取。(另请参阅 concise reference 。)
要将标准输入进一步分解为单词,我们可以使用以下食谱::
val words = {
import scala.language.unsafeNulls
lines.flatMap(l => l.split("(?U)[^\\p{Alpha}0-9']+"))
}
其结果是 l.split(regex) 是字符串数组,其中某些字符串或整个数组可能是 null 。而当 flatMap 应该保留转换的迭代器的元素类型,以这种方式拆分行可能会引入 null 参考文献。因为我们需要空值引用的显式类型(通过添加 "-Yexplicit-nulls" 中的编译器选项 build.sbt )时,Scala编译器认为这段代码不正确,并指示错误,除非我们在本地启用这种潜在不安全的隐式空引用使用。
默认情况下,Java虚拟机将 SIGPIPE 错误信号发送到一个 IOException 。在斯卡拉, print 和 println 打印到stdout,它是 PrintStream 。此类将任何 IOException 设置为一个布尔标志,可通过其 checkError() 方法。(另见 this discussion 了解更多详细信息。)
因此,要将UNIX管道中的Scala(或Java)控制台应用程序用作产生无界(可能无限)输出序列的上游组件,我们必须在打印到stdout时监视该标志,并在必要时终止执行。
例如,该程序一次读取一行,并打印行数和读取的行数。打印后,它检查是否发生错误,如有必要,通过退出程序终止执行:
var count = 0
for line <- lines do
count += 1
println((count, line))
if scala.sys.process.stdout.checkError() then sys.exit(1)
3.2.2. 常量空间复杂性的重要性
常见的应用场景涉及大量的输入数据或无限的输入流,例如来自物联网设备的传感器数据。要实现此类应用程序的可靠性/可用性和可伸缩性等非功能需求,关键是要确保应用程序在执行期间不会超过恒定的内存占用。
具体地说,只要有可能,这意味着一次处理一个输入项,然后忘记它,而不是将整个输入存储在内存中。此版本的程序回显并计算其输入行数,具有恒定空间的复杂性:
var count = 0
for line <- lines do
count += 1
println(line)
if scala.sys.process.stdout.checkError() then sys.exit(1)
println(line + " lines counted")
相比之下,此版本具有线性空间复杂性,可能会耗尽大量输入数据的空间::
var count = 0
val listOfLines = lines.toList
for line <- listOfLines do
count += 1
println(line)
if scala.sys.process.stdout.checkError() then sys.exit(1)
println(line + " lines counted")
总之,要实现恒定空间复杂性,通常最好将输入数据表示为迭代器,而不是将其转换为内存中的集合(如列表)。迭代器支持大多数与内存中集合相同的行为。
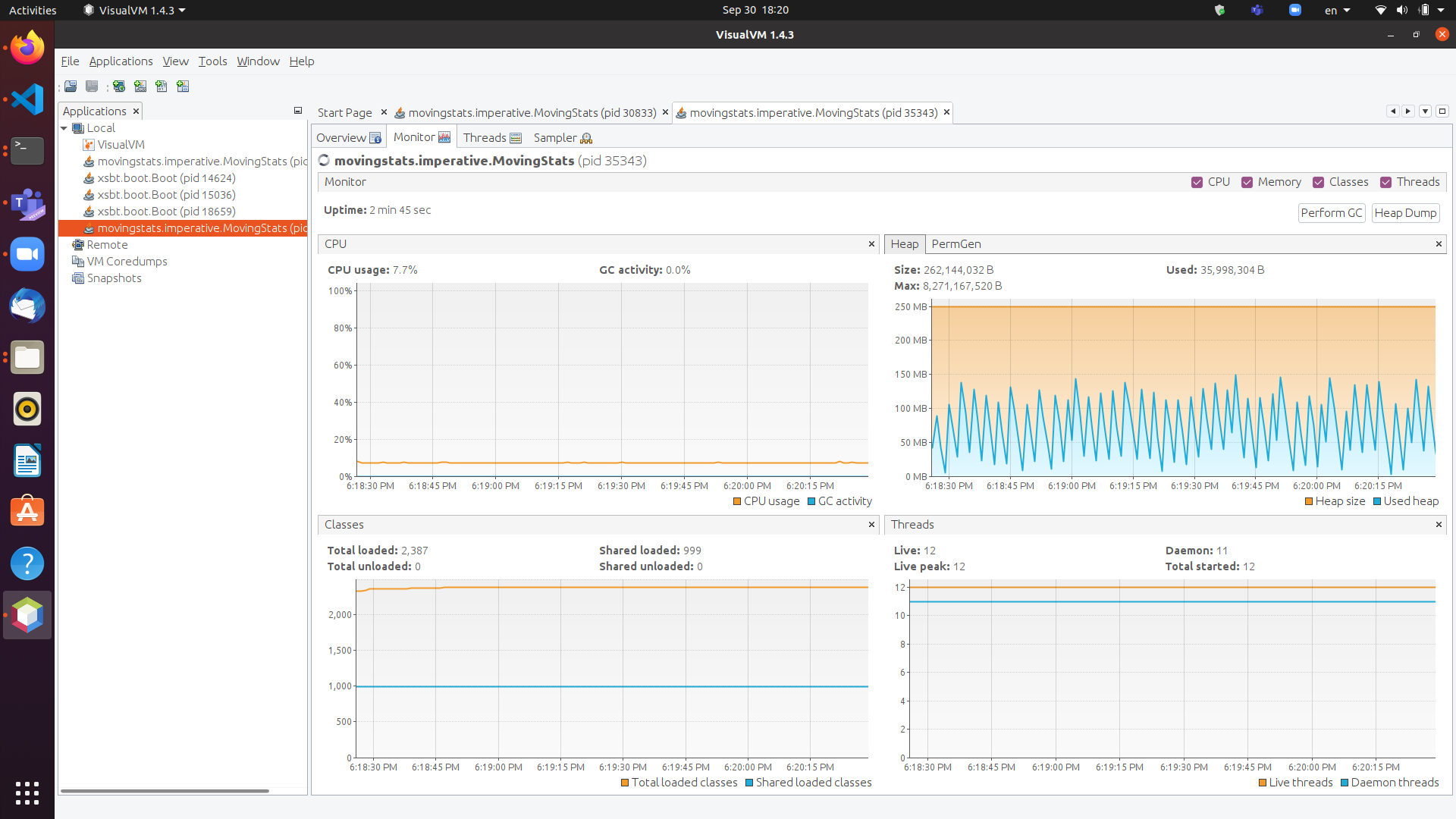
为了观察一段时间内程序的内存占用情况,我们通常使用堆分析器。对于在Java虚拟机(JVM)中运行的程序,我们可以使用VisualVM的独立版本。
例如,下面的堆配置文件(屏幕截图的右上角)显示了一种平坦的锯齿图案,这表明即使我们正在处理越来越多的输入项,空间的复杂性也是恒定的。相比之下,如果锯齿图案随着时间的推移向上倾斜,那么当我们处理输入时,空间复杂性会增加,这意味着一些函数会随着输入大小n的增加而增长。
3.3. 测试Scala代码的选择
测试Scala代码有各种基本技术和库/框架。
最简单的方法是在代码中散布断言。这对于脚本和工作表特别有效:
val l = List(1, 2, 3)
assert { l.contains(2) }
以下测试库/框架可以很好地与Scala配合使用。
熟悉的人 JUnit 可以直接使用。
ScalaCheck 是Scala的测试框架,它强调基于属性的测试,包括通用量化的属性,例如“for all list
x和y,的价值(x ++ y).length等于x.length + y.length“ScalaTest 是一个Scala测试框架,它支持广泛的测试样式,包括行为驱动设计,包括与ScalaCheck的集成。
specs2 是一个基于规范的测试库,也支持与ScalaCheck的集成。
MUnit 是一个较新的Scala测试库。
这个 echotest 示例显示了其中一些库的运行情况。
为了在开发过程中更快地周转,我们可以将这些技术与 triggered execution 。
3.4. 日志记录的作用
日志记录是一种常见的动态非功能需求,在系统的整个生命周期中都很有用。日志记录可能具有挑战性,因为它是贯穿整个代码库的横切关注点。
在最简单的形式中,日志记录可以由普通的打印语句组成,最好是 标准误差 流 (stderr ):
System.err.println("something went wrong: " + anObject)
这允许将错误消息与输出数据分开显示(或重定向)。
对于更复杂的项目,能够集中配置日志记录是有利的,例如将日志消息隐藏在某个 log level 指示消息的严重性、配置日志消息的目的地或完全禁用日志记录。
日志记录框架 都是为了满足这一需求而出现的。现代日志记录框架具有非常低的性能开销,是实现专业级的一种方便有效的方式 separation of concerns 关于伐木。
3.4.1. 登录Scala
例如, log4s 包装器为Scala提供了一种方便的日志记录机制。要最低限度地使用log4,需要执行以下步骤:
为log4和一个简单的slf4j后端实现添加外部依赖项::
"org.log4s" %% "log4s" % "1.8.2", "org.slf4j" % "slf4j-simple" % "1.7.30"
如果您需要比默认值更详细(严重性更低)的日志级别
INFO,例如DEBUG,添加配置文件src/main/resources/simplelogger.properties内容如下:org.slf4j.simpleLogger.defaultLogLevel = debug
现在您就可以访问和使用记录器了::
private val logger = org.log4s.getLogger logger.debug(f"howMany = $howMany minLength = $minLength lastNWords = $lastNWords")
这会产生信息性调试输出,例如:
[main] DEBUG edu.luc.cs.cs371.topwords.TopWords - howMany = 10 minLength = 6 lastNWords = 1000
3.5. 用命令式和面向对象语言定义域模型
在命令式和面向对象语言中,基本类型抽象是
寻址:指针、引用
聚合:结构/记录、数组
示例:链表中的节点
变体:标记的联合,一个接口的多个实现
示例:可变集合抽象
添加元素
删除图元
检查元素是否存在
检查是否为空
有多少元素
几种可能的实现
合理:二叉搜索树、哈希表、位向量(适用于较小的底层域)
不太合理:数组、链表
(结构)递归:根据类型本身定义类型,通常涉及聚合和变量
示例:带有叶子和内部节点实现类的树形接口
泛型(类型参数化):就一个或多个类型参数而言,类型是参数化的
示例:元素类型中的集合参数化
在面向对象的语言中,我们通常使用设计模式的组合(基于这些基本抽象)来表示域模型结构和相关行为:
3.5.1. 作为“更好的Java”的面向对象Scala
Scala提供了对Java的各种改进,包括:
traits: 接口的泛化和抽象类的受限形式,可以组合/堆叠
与文件夹层次结构解耦的包结构
null safety: 确保在编译时表达式不能为空
multiversal equality: 确保苹果只与其他苹果比较
higher-kinded types (高级主题)
然而,较新版本的Java已经开始响应这些进步:
λ表达式
接口中的默认方法
局部类型推理
溪流
我们将在遇到这些功能时对其进行研究。
以下示例说明了如何将Scala用作“更好的Java”,以及如何过渡到上述一些改进:
3.6. 模块化和依赖注入
备注
要理解这一部分,您可能需要首先回顾/回顾 stopwatch example 摘自Comp 313/413(中级面向对象编程)。在这款应用中,模型相当复杂,有三四个相互依赖的组件。创建这些组件的实例后,您必须使用setter将它们彼此连接起来。 Does that ring a bell? 在本节和相关示例中,我们通过将两个或多个Scala特征声明性地连接在一起来实现基本相同的目标。
3.6.1. 设计目标
我们追求与非功能代码质量需求相关的以下设计目标:
testability
modularity 用于分离关注点
reusability 为避免代码重复(“Dry”)
特别是,为了管理日益增长的系统复杂性,我们通常试图将其分解为其设计维度,例如,
混合和匹配具有多个实现的接口
在生产中运行代码与测试
我们可以在许多常见情况下识别它们,包括下面列出的示例。
在面向对象的语言中,我们经常使用类(和接口)作为实现这些设计目标的主要机制。
3.6.2. Scala特征
Scala的特点是 abstract 可用作完全抽象接口以及部分实现的、可组合的构建块(混合)的类型。与Java接口(Java 8之前的版本)不同,Scala特征可以有方法实现(和状态)。这个 Thin Cake idiom 展示了特征如何帮助我们实现设计目标。
备注
我们故意打电话给 薄饼 一个 成语 与模式相反,因为它是 language-specific 。
我们将在本节中使用以下示例:
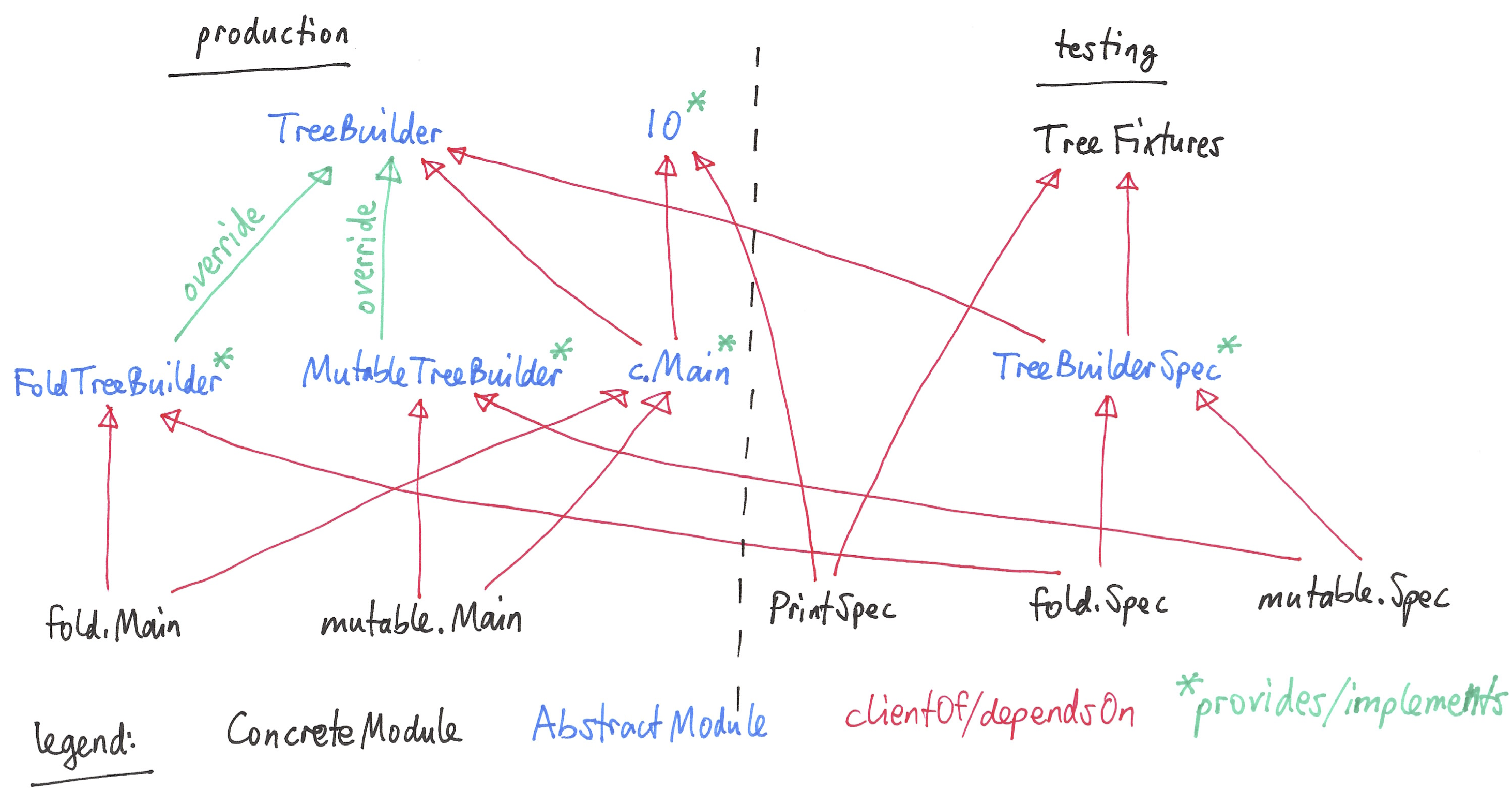
首先,为了实现可测试性,我们可以定义所需的功能,例如 common.IO ,作为它自己的特性,而不是一个具体的类或其他特性的一部分,例如 common.Main 。这些特点是 提供商 某些功能,而使用此功能的构建块有 客户端 ,如``common.Main``(生产端)和 PrintSpec (在测试端)。具体地说,在流程树示例中,我们使用 PrintSpec 为了测试 common.IO 与世隔绝,独立于 common.Main 。
为了避免出现上面提到的设计维度的代码重复,我们可以再次利用Scala特性作为构建块。在一些维度上,有三个可能的角色:
提供商 例如,具体实施方式 MutableTreeBuilder , FoldTreeBuilder 等。
客户端 例如,生产端上的各种主要对象,以及 TreeBuilderSpec 在测试方面
合同 提供者和客户端之间的公共抽象,例如, TreeBuilder
通常,当存在公共合同时,提供商 覆盖 合同中声明的部分或全部抽象行为。某些构建块具有多个角色。例如, common.Main 是(取决于)的客户 TreeBuilder 而是提供具体的主对象所需的主应用行为。同样, TreeBuilderSpec 还取决于 TreeBuilder 而是提供具体测试类的测试代码 (Spec )需要。这种安排使我们能够混合搭配所需的 TreeBuilder 使用以下任一项实施 common.Main 用于生产或 TreeBuilderSpec 用于测试。
下图显示了流程树示例的各个构建块的角色和它们之间的关系。
这个 iterators example 中包含基于特征的模块化的其他实例。 imperative/modular 包裹。
备注
出于教学原因,流程树和迭代器示例相对于它们的简单功能被过度设计:为了增加对代码功能正确性的信心,我们应该测试它;这需要可测试性,这驱动了我们在这些示例中看到的模块化。换句话说,由此产生的设计复杂性是可测试性的成本。另一方面,由于关注点分离、可维护性和其他非功能质量原因,更现实的系统可能已经在其核心功能中具有相当大的设计复杂性;在这种情况下,为实现可测试性而引入的额外复杂性将相对较小。
3.6.3. 基于特征的依赖注入
在存在模块化的情况下, dependency injection (DI)是一种技术,用于从外部向客户端提供依赖项,从而将客户端从“发现”其依赖项的责任中解脱出来,即执行 dependency lookup 。为了响应依赖注入的流行,出现了许多依赖注入框架,如Spring和Guice。
Thin Cake成语在Scala中提供了基本的DI,而不需要DI框架。简单地说, common.Main 不能自己运行,但通过扩展 TreeBuilder 它需要实现 buildTree 方法。其中一个 TreeBuilder 实现特征,例如 FoldTreeBuilder 可以满足这种依赖性。实际的“注射”发生在我们注射的时候,比方说, FoldTreeBuilder 变成 common.Main 在具体的主要客体的定义中 fold.Main 。