9.4. TIN的生成方法¶
由于相同的离散点集可以生成多个不同的三角网,因此也就有着多种不同的三角网的构网算法。一般三角网法未考虑地形线的骨架作用,同时在构网时有一定盲目性或任意性,有的三角形边不是贴在地面上,而是“架空”在河谷上或是“贯穿”于山体中。因此这种方法不能用来建立“地貌上”精确的数字地面模型,而只能用于精度要求不高且瞬时性较强的三维空间模型(如气压、气温、磁场等地理现象)。为了使三角网能够顾及地性线关系,可用人工的方法和程序自动建立的两种方法建立TIN模型。
9.4.1. 人工方法¶
地形测量员注意选取地面上的转折点并且在测量中携带一幅野外草图,用以表示由哪些测点构成地性线,例如山脊线及谷底线。在这些资料的基础上,人工构成三角形时,以可能的最短的边来构成三角形,并保证每条边位于地面上而不是悬空通过或贯穿地球表面。只要上述条件满足,三角形的形状是无关紧要的,因此,取得高质量等高线的关键在于获得地性线资料。如果没有它,任何自动化的处理都不能指望达到常规的人工勾绘等高线的质量。
9.4.2. 程序自动建立¶
Delaunay三角网构网算法可归纳为两大类,即静态三角网和动态三角网。静态三角网指的是在整个建网过程中,已建好的三角网不会因新增点参与构网而发生改变;而对于动态三角网则相反,在构网时,当一个点被选中参与构网时,原有的三角网被重构以满足Delaunay外切圆规则。
静态三角网(李志林,2000)构网法主要有辐射扫描算法、递归分裂算法、分解吞并算法、逐步扩展算法、改进层次算法等。动态三角网构网算法主要有增量式算法和增量式动态生成和修改算法。以上算法基本上反映了构建Delaunay三角网的各种途径。在生成TIN的算法中数据结构的设计和选择对算法的运行效率紧密相关。
1. 三角网生长算法
三角形生长算法是一种典型的静态三角网生长算法。
(1)递归生长算法
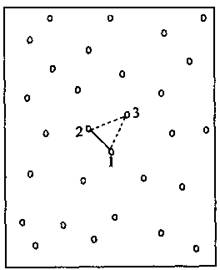
递归生长算法的基本过程如图9-10所示:
① 在所有数据中取任意一点l(一般从几何中心附近开始),查找距离此点最近的点2,相连后作为初始基线1-2;
② 在初始基线右边应用Delaunay法则搜寻第三点3,形成第一个Delaunay三角形;
③ 并以此三角形的两条新边(2-3,3-1)作为新的初始基线;
④ 重复步骤②和③直至所有数据点处理完毕。
该算法主要的工作是在大量数据点中搜寻给定基线符合要求的邻域点。一种比较简单的搜索方法是通过计算三角形外接圆的圆心和半径来完成对邻域点的搜索。为减少搜索时间,还可以预先将数据按X或Y坐标分块并进行排序。使用外接圆的搜索方法限定了基线的待选邻域点,因而降低了用于搜寻Delaunay三角网的计算时间。如果引入约束线段,则在确定第三点时还要判断形成的三角形边是否与约束线段交叉。
(2)凸闭包收缩算法
与递归生长算法相反。凸闭包搜索法的基本思想是首先找到包含数据区域的最小凸多边形。并从该多边形开始从外向里逐层形成三角形网络。平面点凸闭包的定义是包含这些平面点的最小凸多边形。在凸闭包中,连接任意两点的线段必须完全位于多边形内。凸闭包是数据点的自然极限边界。相当于包围数据点的最短路径。显然,凸闭包是数据集标准Delaunay三角网的一部分。计算凸闭包算法步骤包括:
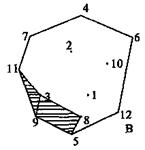
① 搜寻分别对应x-y,x+y最大值及x-y,x+y最小值的各两个点。这些点为凸闭包的顶点,且总是位于数据集的四个角上,如图9-11(a)中曲点7,9,12,6;
② 将这些点以逆时针方向存储于循环链表中;
③ 搜索线段IJ及其右边的所有点,计算对IJ有最大偏移量的点K作为IJ之间新的凸闭包顶点,如点11对边7―9。
④ 重复①~②,直至找不到新的顶点为止。
一旦提取出数据区域的凸闭包,就可以从其中的一条边开始逐层构建三角网,具体算法如下:
① 将凸多边形按逆时针顺序存入链表结构,左下角点附近的顶点排第一;
② 选择第一个点作为起点,与其相邻点的连线作为第一条基边,如图9-12(a)中的9―5;
③ 从数据点中寻找与基边左最邻近的点8作为三角形的顶点。这样便形成了第一个Delaunay三角形;
④ 将起点9与顶点8的连线换做基边。重复③即可形成第二个三角形;
⑤ 重复第④步,直到三角形的顶点为另一个边界点11。这样,借助于一个起点9便形成了一层Delaunay三角形;
⑥ 适当修改边界点序列。依次选取前一层三角网的顶点作为新起点,重复前面的处理,便可建立起连续的一层一层的三角网。

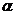
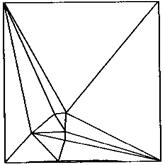
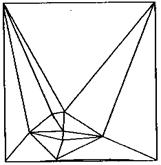
该方法同样可以考虑约束线段。但随着数据点分布密度的不同,实际情况往往比较复杂。比如边界收缩后一个完整的区域可能会分解成若干个相互独立的子区域。当数据量较大时,如何提高顶点选择的效率是该方法的关键。
2. 数据逐点插入法
数据逐点插入法是一种典型的动态三角网生长算法。三角网生长算法最大的问题是计算的时间复杂性,其原因是由于每个三角形的形成都涉及所有待处理的点,且难于通过简单的分块或排序予以彻底解决。数据点越多,问题越突出。而数据逐点插入法在很大程度上克服了这个问题。其具体算法如下(见图9-13):
(1)首先提取整个数据区域的最小外界矩形范围,并以此作为最简单的凸闭包。
(2)按一定规则将数据区域的矩形范围进行格网划分。为了取得比较理想的综合效率,可以限定每个格网单元平均拥有的数据点数。
(3)根据数据点的(x,y)坐标建立分块索引的线性链表。
(4)剖分数据区域的凸闭包形成两个超三角形,所有的数据点都一定在这两个三角形范围内。
(5)按照(3)建立的数据链表顺序往(4)的三角形中插入数据点。首先找到包含数据点的三角形,进而连接该点与三角形的三个顶点,简单剖分该三角形为三个新的三角形。
(6)根据Delaunay三角形的空圆特性,分别调整新生成的三个三角形及其相邻的三角形。对相邻的三角形两两进行检测,如果其中一个三角形的外接圆中包含有另一个三角形除公共顶点外的第三个顶点,则交换公共边。
(7)重复(5)―(6),直至所有的数据点都被插入到三角网中。
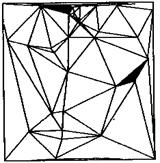

可见,由于步骤(3)的处理,从而保证了相邻的数据点渐次插入,并通过搜寻加入点的影响三角网(Influence Triangulation),现存的三角网在局部范围内得到了动态更新,从而大大提高了寻找包含数据点的三角形的效率。