使用浏览器的开发人员工具进行抓取¶
下面是关于如何使用浏览器的开发人员工具来简化抓取过程的一般指南。现在几乎所有浏览器都内置了 Developer Tools 尽管我们将在本指南中使用firefox,但这些概念适用于任何其他浏览器。
在本指南中,我们将介绍通过抓取从浏览器的开发人员工具中使用的基本工具 quotes.toscrape.com .
检查实时浏览器DOM时的注意事项¶
由于开发人员工具在一个活动的浏览器DOM上运行,所以在检查页面源代码时,您实际上看到的不是原始的HTML,而是应用了一些浏览器清理和执行javascript代码后修改的HTML。尤其是火狐,以添加 <tbody> 元素到表。另一方面,scrapy不修改原始页面html,因此如果使用 <tbody> 在xpath表达式中。
因此,您应该记住以下几点:
检查DOM以查找要在Scrapy中使用的xpaths时禁用javascript(在“开发人员工具”设置中,单击 Disable JavaScript )
不要使用完整的xpath路径,使用基于属性的相对路径和智能路径(例如
id,class,width或任何识别特征,如contains(@href, 'image').从不包括
<tbody>xpath表达式中的元素,除非您真正知道自己在做什么
查看网站¶
到目前为止,开发人员工具最方便的特性是 Inspector feature, which allows you to inspect the underlying HTML code of any webpage. To demonstrate the Inspector, let's look at the quotes.toscrape.com 现场。
在这个网站上,我们总共有来自不同作者的十个引用,其中有特定的标签,还有前十个标签。假设我们想要提取这个页面上的所有引用,而不需要任何关于作者、标签等的元信息。
我们不必查看页面的整个源代码,只需右键单击一个报价并选择 Inspect Element (Q) 打开了 Inspector . 在里面你应该看到这样的东西:
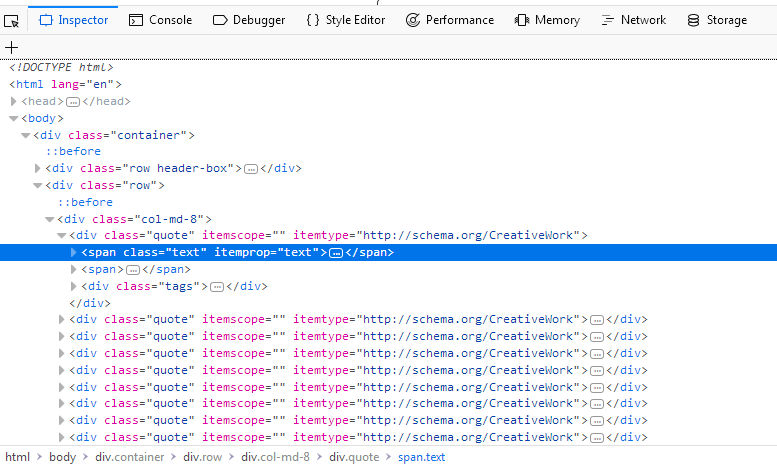
我们感兴趣的是:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">(...)</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
如果你在第一个上面徘徊 div 正上方 span 在屏幕截图中突出显示的标签,您将看到网页的相应部分也会突出显示。现在我们有了一个部分,但是我们在任何地方都找不到报价文本。
的优势 Inspector 它自动展开和折叠网页的部分和标签,大大提高了可读性。您可以通过单击标签前面的箭头或直接双击标签来展开和折叠标签。如果我们扩大 span 带标签 class= "text" 我们将看到我们单击的报价文本。这个 Inspector 允许您将xpath复制到选定的元素。让我们试试看。
首先在http://quotes.toscrape.com/在终端中:
$ scrapy shell "http://quotes.toscrape.com/"
然后,返回web浏览器,右键单击 span 选择标记 Copy > XPath 然后把它贴在这个破壳里:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
添加 text() 最后,我们可以用这个基本选择器提取第一个报价。但这个xpath并没有那么聪明。它所做的就是在源代码中沿着所需的路径从 html . 那么让我们看看我们是否可以改进一下xpath:
如果我们检查 Inspector 我们将再次看到,在我们的 div 标签我们有九个相同的 div 标签,每个标签都具有与第一个相同的属性。如果我们扩展其中任何一个,我们将看到与第一个报价相同的结构:两个 span 标签和一个 div 标签。我们可以扩大每个 span 带标签 class="text" 在我们内部 div 标记并查看每个引用:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
有了这些知识,我们可以改进我们的xpath:我们只需选择 span 标签与 class="text" 通过使用 has-class-extension :
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
通过一个简单、更聪明的xpath,我们能够从页面中提取所有的引号。我们可以在第一个xpath上构建一个循环,以增加最后一个xpath的数量。 div ,但这将不必要地复杂,只需使用 has-class("text") 我们能够在一行中提取所有报价。
这个 Inspector 还有很多其他有用的功能,比如在源代码中搜索或者直接滚动到您选择的元素。让我们演示一个用例:
说你想找到 Next 页面上的按钮。类型 Next 在搜索栏的右上角 Inspector . 你应该得到两个结果。第一个是 li 带标签 class="next" ,第二个是 a 标签。右键单击 a 标记与选择 Scroll into View . 如果您将鼠标悬停在标签上,您将看到突出显示的按钮。从这里我们可以很容易地创建一个 Link Extractor 跟随分页。在这样一个简单的站点上,可能不需要从视觉上查找元素,而是 Scroll into View 函数在复杂的站点上非常有用。
请注意,搜索栏也可用于搜索和测试CSS选择器。例如,您可以搜索 span.text 查找所有报价文本。而不是全文搜索,这将搜索 span 带标签 class="text" 在页面中。
网络工具¶
在抓取过程中,您可能会遇到动态网页,其中页面的某些部分是通过多个请求动态加载的。虽然这很棘手,但是 Network-tool in the Developer Tools greatly facilitates this task. To demonstrate the Network-tool, let's take a look at the page quotes.toscrape.com/scroll .
页面与基本页面非常相似 quotes.toscrape.com -第页,但不是上面提到的 Next 按钮,则当您滚动到底部时,页面会自动加载新的引号。我们可以直接尝试不同的xpath,但是我们将从Scrapy shell中检查另一个非常有用的命令:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
浏览器窗口应该和网页一起打开,但有一个关键的区别:我们看到的不是引用,而是一个带单词的绿色条。 Loading... .

这个 view(response) 命令让我们查看shell或稍后蜘蛛从服务器接收到的响应。这里我们看到加载了一些基本模板,其中包括标题、登录按钮和页脚,但是缺少引号。这告诉我们报价是从不同的请求加载的,而不是 quotes.toscrape/scroll .
如果你点击 Network 选项卡,您可能只能看到两个条目。我们要做的第一件事是通过单击 Persist Logs . 如果禁用此选项,则每次导航到不同的页面时,日志都会自动清除。启用这个选项是一个很好的默认设置,因为它可以让我们控制何时清除日志。
如果我们现在重新加载页面,您将看到日志中填充了六个新的请求。
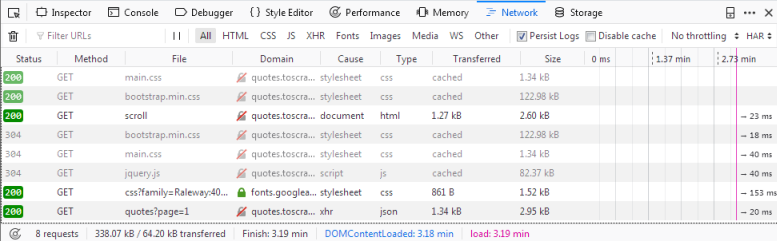
在这里,我们可以看到在重新加载页面时发出的每个请求,并且可以检查每个请求及其响应。因此,让我们找出我们的报价来自哪里:
首先单击带有名称的请求 scroll . 在右边,您现在可以检查请求。在 Headers 您将找到有关请求头的详细信息,例如URL、方法、IP地址等。我们将忽略其他选项卡并直接单击 Response .
你应该在里面看到什么 Preview 窗格是呈现的HTML代码,这正是我们调用 view(response) 在贝壳里。相应地 type 日志中的请求为 html . 其他请求的类型如下 css 或 js 但是我们感兴趣的是一个要求 quotes?page=1 与类型 json .
如果我们点击这个请求,我们会看到请求的URL是 http://quotes.toscrape.com/api/quotes?page=1 响应是一个包含我们的引号的JSON对象。我们也可以右键单击请求并打开 Open in new tab 以获得更好的概述。
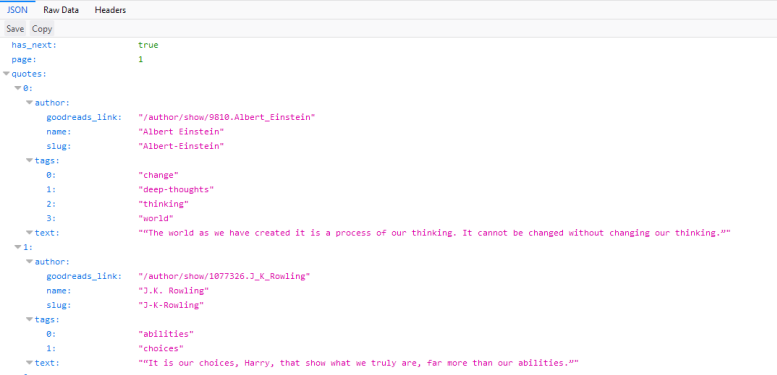
有了这个响应,我们现在可以轻松地解析JSON对象,并请求每个页面获取站点上的每个引用:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api/quotes?page=1']
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
这个蜘蛛程序从QuotesAPI的第一页开始。对于每个响应,我们分析 response.text 并分配给 data . 这让我们可以像在Python字典上一样对JSON对象进行操作。我们迭代 quotes 打印出 quote["text"] . 如果方便的话 has_next 元素是 true (尝试加载 quotes.toscrape.com/api/quotes?page=10 在您的浏览器或大于10的页码中,我们增加 page 属性与 yield 一个新的请求,将递增的页码插入到 url .
在更复杂的网站中,可能很难轻松地重现请求,因为我们可能需要添加 headers 或 cookies 才能让它发挥作用。在这些情况下,您可以将请求导出到 cURL 格式,方法是在网络工具中右键单击它们中的每一个,然后使用 from_curl() 方法以生成等效请求::
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者,如果您想知道重新创建该请求所需的参数,可以使用 curl_to_request_kwargs() 函数获取具有等效参数的字典:
- scrapy.utils.curl.curl_to_request_kwargs(curl_command: str, ignore_unknown_options: bool = True) dict[源代码]¶
将cURL命令语法转换为请求kwargs。
注意,要将cURL命令转换为Scrapy请求,可以使用 curl2scrapy .
如你所见,在 Network -工具我们能够轻松地复制页面滚动功能的动态请求。对动态页面进行爬行可能非常困难,页面也可能非常复杂,但是(主要)归根结底就是识别正确的请求并在蜘蛛中复制它。