注解
此笔记本可在此处下载: 02_RL_2_CarRacing.ipynb
实践工作:强化学习
第2部分:解决携带环境
在这种环境下,就像一个真正的人类一样,我们需要从像素中学习。
可观察的空间确实很大,因此我们需要通过手工制作特征,或者通过深入学习来缩小它。-手工制作功能大量使用图像处理(寻找轮廓、线条、预测运动…)。-图像的深度学习大量使用卷积神经网络从像素中提取特征。
然后,我们需要通过控制理论或深度预测模型来选择下一个动作(状态空间也很大)。请注意,此处的操作空间较低。
在这里,我们将采取深入学习的方式。
II-搬运
最简单的连续控制任务,从像素学习,一个自上而下的赛车环境。
在这种环境下,离散控制是合理的,开/关离散化是可以的。
国家包括 STATE_W x STATE_H pixels .
奖励
奖励是 -0.1 every frame 和 +1000/N for every track tile visited ,其中N是轨迹中的平铺总数。例如,如果你完成了732帧,你的奖励是1000-0.1*732=926.8点。
解决
CarRacing-v0将“解决”定义为 连续100次测试平均奖励900次 .
轨道
轨道是 每集随机 .
当访问所有磁贴时,该集结束。汽车也可以 走出操场 ,离轨道很远,然后它会 -100 and die .
指标
窗口底部和状态RGB缓冲区中显示的一些指示器:
真实速度
4个ABS传感器
方向盘位置
陀螺仪
由Oleg Klimov创造的环境。与其他Openai健身房的许可条款相同。
技术修复
HDPI固定1
此外,要修复大窗口,您可以更改Mac上的显示dpi,或更改:
WINDOW_W = 1200
WINDOW_H = 1000
在里面 gym/envs/box2d/car_racing.py 较小的值。
HDPI固定2
avconv -version
if not brew install libav
1-自己玩!
# Try to play by yourself!
import gym
from pyglet.window import key
import numpy as np
import time
bool_do_not_quit = True # Boolean to quit pyglet
scores = [] # Your gaming score
a = np.array( [0.0, 0.0, 0.0] ) # Actions
def key_press(k, mod):
global bool_do_not_quit, a, restart
if k==0xff0d: restart = True
if k==key.ESCAPE: bool_do_not_quit=False # To Quit
if k==key.Q: bool_do_not_quit=False # To Quit
if k==key.LEFT: a[0] = -1.0
if k==key.RIGHT: a[0] = +1.0
if k==key.UP: a[1] = +1.0
if k==key.DOWN: a[2] = +0.8 # set 1.0 for wheels to block to zero rotation
def key_release(k, mod):
global a
if k==key.LEFT and a[0]==-1.0: a[0] = 0
if k==key.RIGHT and a[0]==+1.0: a[0] = 0
if k==key.UP: a[1] = 0
if k==key.DOWN: a[2] = 0
def run_carRacing_asHuman(policy=None, record_video=False):
global bool_do_not_quit, a, restart
# env = CarRacing()
env = gym.make('CarRacing-v0').env
env.reset()
env.render()
if record_video:
env.monitor.start('/tmp/video-test', force=True)
env.viewer.window.on_key_press = key_press
env.viewer.window.on_key_release = key_release
while bool_do_not_quit:
env.reset()
total_reward = 0.0
steps = 0
restart = False
t1 = time.time() # Trial timer
while bool_do_not_quit:
state, reward, done, info = env.step(a)
# time.sleep(1/10) # Slow down to 10fps for us poor little human!
total_reward += reward
if steps % 200 == 0 or done:
print("Step: {} | Reward: {:+0.2f}".format(steps, total_reward), "| Action:", a)
steps += 1
if not record_video: # Faster, but you can as well call env.render() every time to play full window.
env.render()
if done or restart:
t1 = time.time()-t1
scores.append(total_reward)
scores.append(total_reward)
print("Trial", len(scores), "| Score:", total_reward, '|', steps, "steps | %0.2fs."% t1)
break
if not bool_do_not_quit:
scores.append(total_reward)
print("Trial", len(scores), "| Score:", total_reward, '|', steps, "steps | %0.2fs."% t1)
env.close()
run_carRacing_asHuman() # Run with human keyboard input
Track generation: 1140..1436 -> 296-tiles track
Track generation: 1107..1388 -> 281-tiles track
Step: 0 | Reward: +7.04 | Action: [0. 0. 0.]
Step: 200 | Reward: +22.76 | Action: [0. 1. 0.]
Step: 400 | Reward: +59.90 | Action: [0. 0. 0.8]
Step: 600 | Reward: +39.90 | Action: [1. 1. 0.]
Trial 2 | Score: 22.999999999999254 | 770 steps | 20.88s.
Track generation: 1025..1288 -> 263-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1068..1339 -> 271-tiles track
Step: 0 | Reward: +7.31 | Action: [0. 0. 0.]
Step: 200 | Reward: +31.75 | Action: [-1. 1. 0.]
Step: 400 | Reward: +48.79 | Action: [0. 0. 0.8]
Step: 600 | Reward: +158.42 | Action: [0. 0. 0.]
Step: 800 | Reward: +264.34 | Action: [0. 0. 0.8]
Trial 3 | Score: 261.1444444444442 | 833 steps | 1551202624.86s.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Plot your score
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(1, len(scores)+1), scores)
plt.title('My human performance on CarRacing-v0')
plt.ylabel('Score')
plt.xlabel('Human Episode')
plt.show()
2-创建代理以解决问题
强化学习
政策梯度
模仿学习
深度Q学习
import gym
import numpy as np
# Define the Environments
env = gym.make('CarRacing-v0').env
# Number of Dimensions in the Observable Space and number of Control Actions in the Environments
print('Observation Space:', env.observation_space)
print('Action Space:', env.action_space)
print("\n")
print("Observation Space Param: 96x96x3 values for Red, Green and Blue pixels")
print("Observation Space Highs:", np.mean(env.observation_space.high))
print("Observation Space Lows: ", np.mean(env.observation_space.low))
Observation Space: Box(96, 96, 3)
Action Space: Box(3,)
Observation Space Param: 96x96x3 values for Red, Green and Blue pixels
Observation Space Highs: 255.0
Observation Space Lows: 0.0
# Run the environment
from collections import deque
import gym
import numpy as np
from pyglet.window import key
import time
bool_quit = False
def key_press(k, mod):
global bool_do_not_quit, action, restart
if k==0xff0d: restart = True
if k==key.ESCAPE: bool_do_not_quit=False # To Quit
if k==key.Q: bool_do_not_quit=False # To Quit
if k==key.LEFT: action[0] = -1.0
if k==key.RIGHT: action[0] = +1.0
if k==key.UP: action[1] = +1.0
if k==key.DOWN: action[2] = +0.8 # set 1.0 for wheels to block to zero rotation
def key_release(k, mod):
global action
if k==key.LEFT and action[0]==-1.0: action[0] = 0
if k==key.RIGHT and action[0]==+1.0: action[0] = 0
if k==key.UP: action[1] = 0
if k==key.DOWN: action[2] = 0
def run_carRacing(policy, n_episodes=1000, max_t=1500, print_every=100, record_video=False):
"""Run the CarRacing-v0 environment.
Params
======
n_episodes (int): maximum number of training episodes
max_t (int): maximum number of timesteps per episode
print_every (int): how often to print average score (over last 100 episodes)
Adapted from:
https://gist.github.com/lmclupr/b35c89b2f8f81b443166e88b787b03ab
"""
global bool_quit
if policy.__class__.__name__ == 'Policy_Human':
global action
action = np.array( [0.0, 0.0, 0.0] ) # Global variable used for manual control actions with key_press
env = gym.make('CarRacing-v0').env
env.reset() # This is mandatory for keyboard input
env.render() # This is mandatory for keyboard input
env.viewer.window.on_key_press = key_press
env.viewer.window.on_key_release = key_release
else:
print('** Evaluating', policy.__class__.__name__, '**')
# Define the Environments
env = gym.make('CarRacing-v0').env
# Set random generator for reproductible runs
env.seed(0)
np.random.seed(0)
if record_video:
env.monitor.start('/tmp/video-test', force=True)
scores_deque = deque(maxlen=100)
scores = []
trials_to_solve=[]
for i_episode in range(1, n_episodes+1):
rewards = []
state = env.reset()
if 'reset' in dir(policy): # Check if the .reset method exists
policy.reset(state)
for t in range(max_t): # Avoid stucked episodes
action = policy.act(state)
state, reward, done, info = env.step(action)
rewards.append(reward)
if 'memorize' in dir(policy): # Check if the .memorize method exists
policy.memorize(state, action, reward, done)
# Environment must be rendered! If not, all pixels are white...
env.render() # (mode='rgb_array')
if done:
trials_to_solve.append(t)
break
# if t + 1 == max_t:
# print('This episode is stuck.')
scores_deque.append(sum(rewards))
scores.append(sum(rewards))
if 'update' in dir(policy): # Check if the .update method exists
policy.update(state) # Update the policy
if i_episode % print_every == 0:
print('Episode {}\tAverage Score: {:.2f}\tSteps: {:d}'.format(i_episode, np.mean(scores_deque), t))
if np.mean(scores_deque) >= 900.0:
print('Episode {}\tAverage Score: {:.2f}\tSteps: {:d}'.format(i_episode, np.mean(scores_deque), t))
print('** Environment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(max(1, i_episode-100), np.mean(scores_deque)))
break
if bool_quit:
break
if np.mean(scores_deque) < 900.0:
print('** The environment has never been solved!')
print(' Mean scores on last 100 runs was < 900.0')
if record_video:
env.env.close()
env.close()
return scores, trials_to_solve
# Performance plots
import matplotlib.pyplot as plt
%matplotlib inline
def plot_performance(scores):
# Plot the policy performance
fig = plt.figure()
ax = fig.add_subplot(111)
x = np.arange(1, len(scores) + 1)
y = scores
plt.scatter(x, y, marker='x', c=y)
fit = np.polyfit(x, y, deg=4)
p = np.poly1d(fit)
plt.plot(x,p(x),"r--")
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.title(policy.__class__.__name__ + ' performance on CartPole-v0')
plt.show()
def plot_trials_to_solve(trials_to_solve):
# Plot the policy number of trials to solve the Environment
fig = plt.figure()
ax = fig.add_subplot(111)
plt.hist(trials_to_solve, bins='auto', density=True, facecolor='g', alpha=0.75)
plt.ylabel('Frequency')
plt.xlabel('Number of Trial to solve')
plt.title(policy.__class__.__name__ + ' trials to solve CartPole-v0')
plt.show()
时间差(td0)
信息约简的图像处理
从A (96, 96, 3) = 27 648 values 观测空间至(10*10+7+4)=111 values_.
请注意,如果没有这种减少,问题仍然可以解决,但具有重要的计算能力。
从原始(96、96、3)像素图像
将轨迹裁剪为10*10像素。
从车窗底部的杆上提取1个转向设置、1个速度、1个陀螺仪和4个abs值
资源
# env = wrappers.Monitor(env, "monitor-folder", force=True) # video_callable=lambda episode_id: True
import cv2
# Hand-crafted image processing to extract: 10*10 pixels track, upper and car images
def transform(state):
# crop_img = img[200:400, 100:300] # Crop from x, y, w, h -> 100, 200, 300, 400
# NOTE: its img[y: y + h, x: x + w] and *not* img[x: x + w, y: y + h]
# bottom_black_bar is the section of the screen with steering, speed, abs and gyro information.
# we crop off the digits on the right as they are illigible, even for ml.
# since color is irrelavent, we grayscale it.
bottom_black_bar = state[84:, 12:]
img = cv2.cvtColor(bottom_black_bar, cv2.COLOR_RGB2GRAY)
bottom_black_bar_bw = cv2.threshold(img, 1, 255, cv2.THRESH_BINARY)[1]
bottom_black_bar_bw = cv2.resize(bottom_black_bar_bw, (84, 12), interpolation = cv2.INTER_NEAREST)
# upper_field = observation[:84, :96] # This is the section of the screen that contains the track
upper_field = state[:84, 6:90] # We crop side of screen as they carry little information
img = cv2.cvtColor(upper_field, cv2.COLOR_RGB2GRAY)
upper_field_bw = cv2.threshold(img, 120, 255, cv2.THRESH_BINARY)[1]
upper_field_bw = cv2.resize(upper_field_bw, (10, 10), interpolation = cv2.INTER_NEAREST) # rescaled to 10*10 pixels
upper_field_bw = upper_field_bw.astype('float') / 255
car_field = state[66:78, 43:53]
img = cv2.cvtColor(car_field, cv2.COLOR_RGB2GRAY)
car_field_bw = cv2.threshold(img, 80, 255, cv2.THRESH_BINARY)[1]
car_field_t = [
car_field_bw[:, 3].mean() / 255,
car_field_bw[:, 4].mean() / 255,
car_field_bw[:, 5].mean() / 255,
car_field_bw[:, 6].mean() / 255]
return bottom_black_bar_bw, upper_field_bw, car_field_t
def convert_argmax_qval_to_env_action(output_value):
# we reduce the action space to 15 values. 9 for steering, 6 for gaz/brake.
# to reduce the action space, gaz and brake cannot be applied at the same time.
# as well, steering input and gaz/brake cannot be applied at the same time.
# similarly to real life drive, you brake/accelerate in straight line, you coast while sterring.
gaz = 0.0
brake = 0.0
steering = 0.0
# output value ranges from 0 to 10
if output_value <= 8:
# steering. brake and gaz are zero.
output_value -= 4
steering = float(output_value) / 4
elif output_value >= 9 and output_value <= 9:
output_value -= 8
gaz = float(output_value) / 3 # 33%
elif output_value >= 10 and output_value <= 10:
output_value -= 9
brake = float(output_value) / 2 # 50% brakes
else:
print("[WARNING] Error in convert_argmax_qval_to_env_action()")
white = np.ones((round(brake * 100), 10))
black = np.zeros((round(100 - brake * 100), 10))
brake_display = np.concatenate((black, white))*255
white = np.ones((round(gaz * 100), 10))
black = np.zeros((round(100 - gaz * 100), 10))
gaz_display = np.concatenate((black, white))*255
control_display = np.concatenate((brake_display, gaz_display), axis=1)
# cv2.namedWindow('controls', cv2.WINDOW_NORMAL)
# cv2.resizeWindow('controls', 100, 20)
# cv2.imshow('controls', control_display)
# cv2.waitKey(1)
return [steering, gaz, brake]
# This function uses the black bar at the window botttom to extract steering setting, speed and gyro data
def compute_steering_speed_gyro_abs(a):
right_steering = a[6, 36:46].mean() / 255
left_steering = a[6, 26:36].mean() / 255
steering = (right_steering - left_steering + 1.0) / 2
left_gyro = a[6, 46:60].mean() / 255
right_gyro = a[6, 60:76].mean() / 255
gyro = (right_gyro - left_gyro + 1.0) / 2
speed = a[:, 0][:-2].mean() / 255
abs1 = a[:, 6][:-2].mean() / 255
abs2 = a[:, 8][:-2].mean() / 255
abs3 = a[:, 10][:-2].mean() / 255
abs4 = a[:, 12][:-2].mean() / 255
# white = np.ones((round(speed * 100), 10))
# black = np.zeros((round(100 - speed * 100), 10))
# speed_display = np.concatenate((black, white))*255
# cv2.imshow('sensors', speed_display)
# cv2.waitKey(1)
return [steering, speed, gyro, abs1, abs2, abs3, abs4]
# Information reduction from the original image pixels:
# - Crop the track to 10*10 pixels
# - Extract 1 steering setting, 1 speed, 1 gyro and 4 abs values from the bar on the window bottom
state_space_dim = 10 * 10 + 7 + 4
print(state_space_dim)
111
from keras.models import load_model, Sequential
from keras.layers import Dense
from keras.optimizers import SGD, RMSprop, Adam, Adamax
import math
import os
from pathlib import Path
import random
import shutil
import time
state_space_dim = 10 * 10 + 7 + 4 # We extract a 10*10 image and values from the window bottom
# 7*7 + 3. or 14*14 + 3
# Define a Temporal Difference Policy
class Policy_TD0():
def __init__(self, state_space_dim=state_space_dim, action_space_dim=3):
self.action_space_dim = action_space_dim
self.state_space_dim = state_space_dim
self.gamma = 0.99 # 0.95 is slow # Discount rate
# self.epsilon = 1.0 # 1.0 0.2 1.0<->0.1 # This should be tuned carefuly
self.epsilon = 0.5 / np.sqrt(901)
# self.epsilon_min = 0.01 # 0.0001 0.001
self.epsilon_decay = 0.995 # 0.995
self.learning_rate = 0.002 # 0.001 # This should be tuned carefuly
self.learning_rate_decay = 0.01 # 0.01 Learning rate decay
# self.batch_size = 64 # 32
self.episode = 0 # Episode counter
print('Deep Neural Networks to model the Q Table:')
if os.path.exists('race-car.h5'):
print('** Found a local race-car.h5 model.')
self.model = load_model('race-car.h5')
print(' race-car.h5 model loaded!')
else:
self.model = self._build_model(self.state_space_dim, action_space_dim)
self.model.summary()
# self.memory = []
# self.memory = deque(maxlen=100000) # We can limit the memory size
def _build_model(self, state_space_dim, action_space_dim):
# Neural Net for Deep-Q learning Model
model = Sequential()
print('** Build a 2FC layers to model the Q-table of this problem **')
model.add(Activation('linear'))
# Optimizer:
# rms = RMSprop(lr=0.005)
# sgd = SGD(lr=0.1, decay=0.0, momentum=0.0, nesterov=False)
# Adam(lr=0.0005)
# Adamax(lr=0.001)
model.add(Dense(action_space_dim, activation='linear')) # Linear output so we can have range of real-valued outputs
model.compile(loss='mse', optimizer=Adamax(lr=self.learning_rate, decay=self.learning_rate_decay))
def act(self, state):
self.qval = self.model.predict(self.current_state, verbose=0)[0]
# epsilon = max(self.epsilon_min, min(self.epsilon, 1.0 - math.log10((self.episode + 1) * self.epsilon_decay)))
if np.random.random() < self.epsilon: # epsilon-greedy action selection
self.argmax_qval = random.randint(0, 10)
# action = env.action_space.sample()
else:
self.argmax_qval = np.argmax(self.qval)
return convert_argmax_qval_to_env_action(self.argmax_qval)
def memorize(self, next_state, action, reward, done):
# Memorize all observables and environment trial results
a, b, c = transform(next_state)
next_state = np.concatenate( # this is 3 + 7*7 size vector. all scaled in range 0..1
(np.array([compute_steering_speed_gyro_abs(a)]).reshape(1,-1).flatten(),
b.reshape(1,-1).flatten(), c), axis=0)
next_state = np.array(next_state).reshape(1, self.state_space_dim)
# self.memory.append((self.current_state, action, reward, next_state, done))
# Standard Q-Learning TD(0)
next_qval = self.model.predict(next_state, verbose=0)[0]
G = reward + self.gamma * np.max(next_qval)
y = self.qval[:]
# y[np.argmax(self.qval)] = G
y[self.argmax_qval] = G
self.train(self.current_state, y) # Update model on every run?
self.current_state = next_state
def update(self, state):
self.episode += 1 # Increment trial counter
# Train the Q-Network
# if len(self.memory) > self.batch_size: # If there are enough trial in memory
# if len(self.memory) % 4: # Train only every 4th trial
# if len(self.memory) > 2000: # We can lazy start to acquire more data before learn on it
# self.replay_to_train(self.batch_size)
# Update epsilon
# if self.epsilon > self.epsilon_min:
# self.epsilon *= self.epsilon_decay
# self.epsilon = 0.5 / np.sqrt(self.episode + 1 + 900)
self.epsilon = 0.5 / np.sqrt(self.episode + 900)
def train(self, state, G):
self.model.fit(state, np.array(G).reshape(1, 11), epochs=1, verbose=0)
def replay_to_train(self, batch_size): # TODO: implement TD
state_batch, Q_batch = [], []
minibatch = random.sample(self.memory, min(len(self.memory), batch_size))
for state, action, reward, next_state, done in minibatch:
Q_target = self.model.predict(state)[0] # Use the model to predict the target
if done : # Full reward because environment was solved
Q_target[np.argmax(Q_target)] = reward
else: # Discount the reward by gamma because environment was not solved
Q_target[np.argmax(Q_target)] = reward + self.gamma * np.max(self.model.predict(next_state)[0])
state_batch.append(state[0])
Q_batch.append(Q_target)
self.model.fit(np.array(state_batch), np.array(Q_batch), batch_size=len(state_batch), verbose=0)
def reset(self, state):
# Set current_state
a, b, c = transform(state) # this is 3 + 7*7 size vector. all scaled in range 0..1
self.current_state = np.concatenate((np.array([compute_steering_speed_gyro_abs(a)]).reshape(1, -1).flatten(),
b.reshape(1, -1).flatten(), c), axis=0).reshape(1, self.state_space_dim)
def save_model(self):
filepath = 'race-car.h5'
if Path(filepath).exists():
timestamp = os.stat(filepath).st_ctime
print('** OLD', filepath, 'exists! Created:', time.ctime(timestamp))
shutil.copy(filepath, filepath + '_' + str(timestamp))
self.model.save('race-car.h5')
print('** Model saved to', filepath, '!')
policy = Policy_TD0()
scores, trials_to_solve = run_carRacing(policy, n_episodes=102, max_t=1000, print_every=1)
Deep Neural Networks to model the Q Table:
** Found a local race-car.h5 model.
race-car.h5 model loaded!
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 57344
_________________________________________________________________
activation_1 (Activation) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 11) 5643
_________________________________________________________________
activation_2 (Activation) (None, 11) 0
=================================================================
Total params: 62,987
Trainable params: 62,987
Non-trainable params: 0
_________________________________________________________________
** Evaluating Policy_TD0 **
Track generation: 1143..1442 -> 299-tiles track
Episode 1 Average Score: -13.34 Steps: 979
Track generation: 1087..1369 -> 282-tiles track
Episode 2 Average Score: 89.24 Steps: 999
Track generation: 964..1212 -> 248-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1176..1474 -> 298-tiles track
Episode 3 Average Score: 158.60 Steps: 999
Track generation: 1283..1608 -> 325-tiles track
Episode 4 Average Score: 174.19 Steps: 999
Track generation: 1217..1526 -> 309-tiles track
Episode 5 Average Score: 208.32 Steps: 999
Track generation: 1096..1374 -> 278-tiles track
Episode 6 Average Score: 208.07 Steps: 999
Track generation: 1198..1501 -> 303-tiles track
Episode 7 Average Score: 191.03 Steps: 999
Track generation: 1159..1453 -> 294-tiles track
Episode 8 Average Score: 192.62 Steps: 999
Track generation: 957..1205 -> 248-tiles track
Episode 9 Average Score: 175.85 Steps: 999
Track generation: 1181..1480 -> 299-tiles track
Episode 10 Average Score: 198.60 Steps: 999
Track generation: 979..1234 -> 255-tiles track
Episode 11 Average Score: 183.43 Steps: 257
Track generation: 1320..1654 -> 334-tiles track
Episode 12 Average Score: 181.59 Steps: 999
Track generation: 1067..1338 -> 271-tiles track
Episode 13 Average Score: 184.14 Steps: 999
Track generation: 1067..1338 -> 271-tiles track
Episode 14 Average Score: 189.51 Steps: 999
Track generation: 1207..1513 -> 306-tiles track
Episode 15 Average Score: 193.16 Steps: 999
Track generation: 1106..1396 -> 290-tiles track
Episode 16 Average Score: 184.44 Steps: 262
Track generation: 1296..1628 -> 332-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1047..1319 -> 272-tiles track
Episode 17 Average Score: 172.57 Steps: 760
Track generation: 1245..1560 -> 315-tiles track
Episode 18 Average Score: 176.19 Steps: 999
Track generation: 1232..1544 -> 312-tiles track
Episode 19 Average Score: 181.62 Steps: 999
Track generation: 1120..1408 -> 288-tiles track
Episode 20 Average Score: 177.29 Steps: 999
Track generation: 1225..1536 -> 311-tiles track
Episode 21 Average Score: 182.98 Steps: 999
Track generation: 1077..1357 -> 280-tiles track
Episode 22 Average Score: 174.58 Steps: 488
Track generation: 1322..1664 -> 342-tiles track
Episode 23 Average Score: 183.94 Steps: 999
Track generation: 1035..1297 -> 262-tiles track
Episode 24 Average Score: 182.61 Steps: 429
Track generation: 1297..1626 -> 329-tiles track
Episode 25 Average Score: 183.62 Steps: 999
Track generation: 1294..1621 -> 327-tiles track
Episode 26 Average Score: 181.33 Steps: 999
Track generation: 1055..1331 -> 276-tiles track
Episode 27 Average Score: 176.12 Steps: 338
Track generation: 1202..1507 -> 305-tiles track
Episode 28 Average Score: 177.42 Steps: 999
Track generation: 863..1087 -> 224-tiles track
Episode 29 Average Score: 186.72 Steps: 999
Track generation: 1227..1538 -> 311-tiles track
Episode 30 Average Score: 199.85 Steps: 999
Track generation: 1317..1652 -> 335-tiles track
Episode 31 Average Score: 201.77 Steps: 999
Track generation: 1115..1402 -> 287-tiles track
Episode 32 Average Score: 211.90 Steps: 999
Track generation: 1168..1464 -> 296-tiles track
Episode 33 Average Score: 208.74 Steps: 872
Track generation: 1056..1324 -> 268-tiles track
Episode 34 Average Score: 207.11 Steps: 688
Track generation: 1204..1509 -> 305-tiles track
Episode 35 Average Score: 212.53 Steps: 999
Track generation: 1260..1579 -> 319-tiles track
Episode 36 Average Score: 214.41 Steps: 999
Track generation: 1100..1379 -> 279-tiles track
Episode 37 Average Score: 220.21 Steps: 999
Track generation: 1185..1485 -> 300-tiles track
Episode 38 Average Score: 220.23 Steps: 999
Track generation: 1034..1296 -> 262-tiles track
Episode 39 Average Score: 232.55 Steps: 999
Track generation: 1076..1352 -> 276-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1132..1419 -> 287-tiles track
Episode 40 Average Score: 232.72 Steps: 999
Track generation: 1292..1619 -> 327-tiles track
Episode 41 Average Score: 234.48 Steps: 999
Track generation: 1275..1598 -> 323-tiles track
Episode 42 Average Score: 232.72 Steps: 999
Track generation: 1056..1324 -> 268-tiles track
Episode 43 Average Score: 236.05 Steps: 999
Track generation: 1092..1377 -> 285-tiles track
Episode 44 Average Score: 231.00 Steps: 586
Track generation: 1127..1413 -> 286-tiles track
Episode 45 Average Score: 230.74 Steps: 999
Track generation: 1104..1384 -> 280-tiles track
Episode 46 Average Score: 235.86 Steps: 999
Track generation: 1131..1430 -> 299-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1195..1498 -> 303-tiles track
Episode 47 Average Score: 239.00 Steps: 999
Track generation: 1155..1448 -> 293-tiles track
Episode 48 Average Score: 237.08 Steps: 999
Track generation: 1317..1650 -> 333-tiles track
Episode 49 Average Score: 235.85 Steps: 999
Track generation: 1180..1479 -> 299-tiles track
Episode 50 Average Score: 236.79 Steps: 999
Track generation: 1170..1467 -> 297-tiles track
Episode 51 Average Score: 235.48 Steps: 573
Track generation: 1022..1282 -> 260-tiles track
Episode 52 Average Score: 236.68 Steps: 999
Track generation: 1230..1542 -> 312-tiles track
Episode 53 Average Score: 239.73 Steps: 999
Track generation: 1018..1278 -> 260-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1126..1412 -> 286-tiles track
Episode 54 Average Score: 240.20 Steps: 999
Track generation: 1251..1568 -> 317-tiles track
Episode 55 Average Score: 237.32 Steps: 936
Track generation: 1202..1507 -> 305-tiles track
Episode 56 Average Score: 232.17 Steps: 232
Track generation: 1265..1592 -> 327-tiles track
Episode 57 Average Score: 229.03 Steps: 999
Track generation: 1049..1315 -> 266-tiles track
Episode 58 Average Score: 231.49 Steps: 999
Track generation: 1345..1685 -> 340-tiles track
Episode 59 Average Score: 231.53 Steps: 999
Track generation: 929..1167 -> 238-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1059..1328 -> 269-tiles track
Episode 60 Average Score: 233.84 Steps: 999
Track generation: 981..1236 -> 255-tiles track
Episode 61 Average Score: 234.69 Steps: 999
Track generation: 1220..1529 -> 309-tiles track
Episode 62 Average Score: 236.05 Steps: 999
Track generation: 1062..1332 -> 270-tiles track
Episode 63 Average Score: 241.33 Steps: 999
Track generation: 1148..1439 -> 291-tiles track
Episode 64 Average Score: 241.12 Steps: 999
Track generation: 983..1235 -> 252-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1106..1387 -> 281-tiles track
Episode 65 Average Score: 240.24 Steps: 554
Track generation: 1068..1339 -> 271-tiles track
Episode 66 Average Score: 244.23 Steps: 999
Track generation: 1285..1611 -> 326-tiles track
Episode 67 Average Score: 241.20 Steps: 999
Track generation: 1224..1534 -> 310-tiles track
Episode 68 Average Score: 242.47 Steps: 999
Track generation: 1095..1373 -> 278-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1209..1515 -> 306-tiles track
Episode 69 Average Score: 245.68 Steps: 999
Track generation: 1167..1463 -> 296-tiles track
Episode 70 Average Score: 247.52 Steps: 999
Track generation: 1215..1523 -> 308-tiles track
Episode 71 Average Score: 249.51 Steps: 999
Track generation: 1292..1619 -> 327-tiles track
Episode 72 Average Score: 252.92 Steps: 999
Track generation: 1099..1378 -> 279-tiles track
Episode 73 Average Score: 255.52 Steps: 999
Track generation: 1179..1478 -> 299-tiles track
Episode 74 Average Score: 254.44 Steps: 999
Track generation: 1107..1388 -> 281-tiles track
Episode 75 Average Score: 253.66 Steps: 999
Track generation: 1209..1519 -> 310-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1233..1544 -> 311-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1234..1555 -> 321-tiles track
Episode 76 Average Score: 251.07 Steps: 999
Track generation: 1232..1553 -> 321-tiles track
Episode 77 Average Score: 247.70 Steps: 614
Track generation: 1214..1522 -> 308-tiles track
Episode 78 Average Score: 247.08 Steps: 999
Track generation: 1151..1450 -> 299-tiles track
Episode 79 Average Score: 244.98 Steps: 999
Track generation: 1213..1529 -> 316-tiles track
Episode 80 Average Score: 242.93 Steps: 999
Track generation: 1252..1569 -> 317-tiles track
Episode 81 Average Score: 242.20 Steps: 583
Track generation: 1040..1304 -> 264-tiles track
Episode 82 Average Score: 241.67 Steps: 471
Track generation: 1128..1414 -> 286-tiles track
Episode 83 Average Score: 244.15 Steps: 999
Track generation: 1121..1408 -> 287-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1048..1319 -> 271-tiles track
Episode 84 Average Score: 246.18 Steps: 999
Track generation: 1224..1534 -> 310-tiles track
Episode 85 Average Score: 246.45 Steps: 999
Track generation: 1140..1429 -> 289-tiles track
Episode 86 Average Score: 248.44 Steps: 999
Track generation: 1114..1400 -> 286-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1052..1319 -> 267-tiles track
Episode 87 Average Score: 250.57 Steps: 999
Track generation: 1045..1313 -> 268-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1131..1418 -> 287-tiles track
Episode 88 Average Score: 252.82 Steps: 999
Track generation: 1122..1412 -> 290-tiles track
Episode 89 Average Score: 249.96 Steps: 231
Track generation: 1239..1553 -> 314-tiles track
Episode 90 Average Score: 249.05 Steps: 999
Track generation: 1022..1283 -> 261-tiles track
retry to generate track (normal if there are not many of this messages)
Track generation: 1123..1408 -> 285-tiles track
Episode 91 Average Score: 249.59 Steps: 999
Track generation: 1158..1462 -> 304-tiles track
Episode 92 Average Score: 248.59 Steps: 999
Track generation: 1313..1645 -> 332-tiles track
Episode 93 Average Score: 248.80 Steps: 999
Track generation: 1000..1254 -> 254-tiles track
Episode 94 Average Score: 248.66 Steps: 999
Track generation: 1259..1578 -> 319-tiles track
Episode 95 Average Score: 246.75 Steps: 999
Track generation: 1316..1655 -> 339-tiles track
Episode 96 Average Score: 244.65 Steps: 999
Track generation: 1086..1367 -> 281-tiles track
Episode 97 Average Score: 244.74 Steps: 999
Track generation: 988..1238 -> 250-tiles track
Episode 98 Average Score: 241.85 Steps: 223
Track generation: 1072..1344 -> 272-tiles track
Episode 99 Average Score: 240.71 Steps: 999
Track generation: 1152..1444 -> 292-tiles track
Episode 100 Average Score: 237.61 Steps: 413
Track generation: 1066..1341 -> 275-tiles track
Episode 101 Average Score: 242.11 Steps: 999
Track generation: 1070..1341 -> 271-tiles track
Episode 102 Average Score: 242.06 Steps: 724
** The environment has never been solved!
Mean scores on last 100 runs was < 900.0
** Mean average score: 239.06616008258862
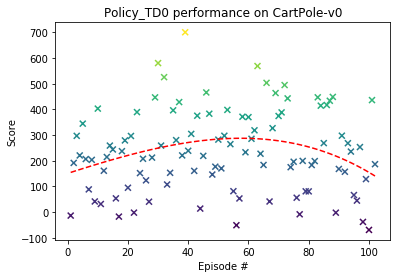

print('** Mean average score:', np.mean(scores))
plot_performance(scores)
plot_trials_to_solve(trials_to_solve)
** Mean average score: 239.06616008258862
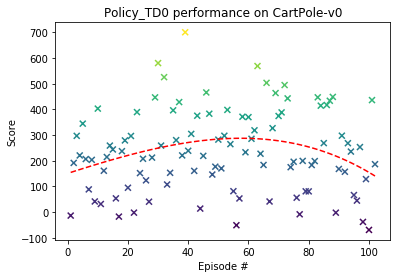

# Save the model
policy.save_model()
更进一步
在自动驾驶汽车上
Comma.ai’s real self-driving dataset & solutions Self Racing Car challenge & dataset