
目录
- Ⅰ Python基础
- 1. Python入门
- 2. 流程控制
- 3. Python函数使用
- 4. Python中的列表
- 5. 字典
- 6. Python中的字符串
- 7. 异常处理
- Ⅱ Python 进阶
- Ⅲ Python常用类库
- 1. 正则表达式
- 2. 文件读写
- 3. 文件操作
- 4. CSV与JSON
- 5. 日期与时间
- 6. 文本文件
- Ⅳ Python日常工具
- 1. 用 Python 处理电子表格
- 2. DOCX 文档解析与处理
- 3. 用Python进行图像处理
- 4. 使用Python处理PDF文档
- 5. Web信息解析与处理
- 6. Web信息生成与发布
- 7. 自动化Email处理
- 8. 杂项
- Ⅴ 专题
- 1. Pillow图像处理
- 2. OpenCV处理
- 3. 数据库自动化报表处理:使用SQLite
- 4. Python和Web
- 5. Web信息处理
- 6. Web模板引擎
- 7. XML 处理
- Ⅵ 图像处理:使用scikit-image
- 1. skimage数字图像处理基础
- 2. skimage数字图像处理中级
- 3. skimage数字图像处理高级
- Ⅶ 科学计算
- 1. NumPy数值计算
- 2. SciPy科学类库
- 3. SymPy符号运算
- 4. Matplotlib绘图
- 5. Pandas 第一部分
- 6. Pandas 第二部分
- 6.1. Pandas排序
- 6.2. Pandas字符串和文本数据
- lower()函数示例
- upper()函数示例
- len()函数示例
- strip()函数示例
- split(pattern)函数示例
- cat(sep=pattern)函数示例
- get_dummies()函数示例
- contains()函数示例
- replace(a,b)函数示例
- repeat(value)函数示例
- count(pattern)函数示例
- startswith(pattern)函数示例
- endswith(pattern)函数示例
- find(pattern)函数示例
- findall(pattern)函数示例
- swapcase()函数示例
- islower()函数示例
- isupper()函数示例
- isnumeric()函数示例
- 6.3. Pandas选项和自定义
- 6.4. Pandas索引和选择数据
- 6.5. Pandas统计函数
- 6.6. Pandas窗口函数
- 6.7. Pandas聚合
- 6.8. Pandas缺失数据
- 6.9. Pandas分组(GroupBy)
- 6.10. Pandas合并/连接
- 6.11. Pandas级联
- 7. Pandas 第三部分
- Ⅷ 自然语言与知识图谱
上一个主题
下一个主题

4.8. 实例:读取PDF内中文内容¶
我们前面介绍的PyPDF4库,对解析中文支持的并不好,获取输出会出现乱码,下面我们使用其他库来解析中文内容。
使用PyPDF4解析文档¶
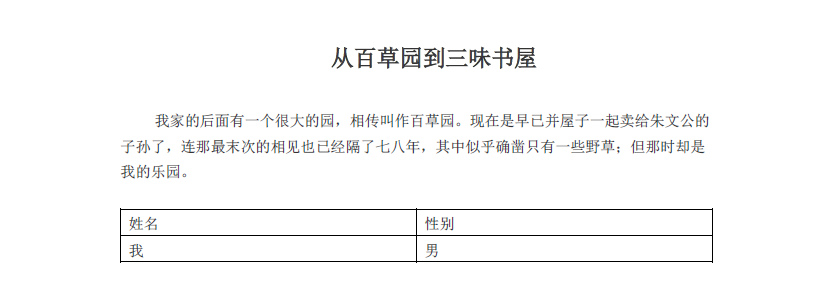
文档的内容如图所示:
>>> import PyPDF4
>>>
>>> FILE_PATH = './pdf_file/zh.pdf'
>>>
>>> with open(FILE_PATH, mode='rb') as f:
>>> reader = PyPDF4.PdfFileReader(f)
>>> page = reader.getPage(0)
>>> print(page.extractText().strip())
,®9y
,´
FÓ˛0˛[!Q,´-(4ÿLÄGþ9y˝_
˘A
+g
使用pdfplumber解析PDF文档¶
需要先安装pdfplumber库
pip install pdfplumber
即可使用。
>>> import pdfplumber
>>>
>>> with pdfplumber.open(FILE_PATH) as pdf:
>>> content = ''
>>> for i in range(len(pdf.pages)):
>>> page = pdf.pages[i]
>>> page_content = '\n'.join(page.extract_text().split('\n')[:-1])
>>> content = content + page_content
>>> print(content)
从百草园到三味书屋
我家的后面有一个很大的园,相传叫作百草园。现在是早已并屋子一起卖给朱文公的
子孙了,连那最末次的相见也已经隔了七八年,其中似乎确凿只有一些野草;但那时却是
我的乐园。
姓名 性别
我 男
使用Tika解析PDF文档Tika¶
Tika是一个内容分析工具,自带全面的parser工具类,能解析基本所有常见格式的文件,得到文件的metadata,content等内容,返回格式化信息。总的来说可以作为一个通用的解析工具。特别对于搜索引擎的数据抓去和处理步骤有重要意义。Tika是Apache的Lucene项目下面的子项目,在lucene的应用中可以使用tika获取大批量文档中的内容来建立索引,非常方便,也很容易使用。所以他是使用Java编写的,Tika集成了现有的文档解析库,并提供统一的接口,使针对不同类型的文档进行解析变得更简单。Tika针对搜索引擎索引、内容分析、转化等非常有用。让我们来看看他的强大。
安装
pip install tika
>>> import tika
>>> tika.initVM()
>>> from tika import parser
>>> parsed = parser.from_file(FILE_PATH)
>>> print(parsed["content"].strip())
从百草园到三味书屋
我家的后面有一个很大的园,相传叫作百草园。现在是早已并屋子一起卖给朱文公的
子孙了,连那最末次的相见也已经隔了七八年,其中似乎确凿只有一些野草;但那时却是
我的乐园。
姓名 性别
我 男
使用tika库可以读取文档内的所有所有信息,包括超链接等。