
目录

>>> from helper import info; info()
页面更新时间: 2020-07-05 07:29:07
操作系统/OS: Linux-4.19.0-9-amd64-x86_64-with-debian-10.4 ;Python: 3.7.3
5.1. 处理 PDF 文档¶
PDF和Word文档是二进制文件,所以它们比纯文本文件
要复杂得多。除了文本之外,它们还保存了许多字体、
颜色和布局信息。如果希望程序能读取或写入 PDF 和 Word
文档,需要做的就不只是将它们的文件名 传递给 open()。
好在,有一些Python模块。使得处理PDF和Word文档变 得容易。本章将介绍两个这样的模块。
PDF文档¶
PDF表示Portable Document Format ,使用.pdf文件扩展名。
虽然PDF支持许多功能,但本章将专注于最常做的两件事:
从PDF读取文本内容和从已有的文档生成新的PDF。
用于处理PDF的模块是 PyPDF2 。要安装它, 就从命令行运行
pip install PyPDF2 。这个模块 名称是区分大小写的,所以要确保 y
是小写,其他 字母都是大写(请查看附录A,了解安装第三方模块的
所有细节)。如果该模块安装正确,在交互式环境中 运行 import PyPDF2
,应该不会显示任何错误。
从 PDF提取文本¶
PyPDF2没有办法从PDF文档中提取图像、图表或其他
媒体,但它可以提取文本,并将文本返回为Python字符串。 为了开始学习
PyPDF2 的工作原理,我们将它 用于一个示例PDF,如图13-1所示。
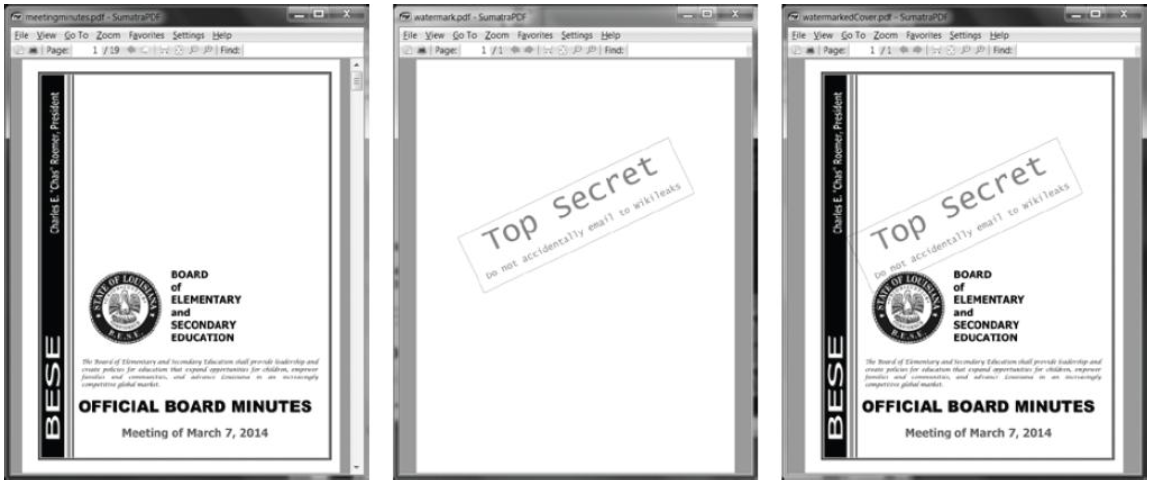
图13-1 PDF页面,我们将从中提取文本
有问题的PDF格式¶
虽然PDF文件对文本布局非常好,让人们很容易打印并阅读,但软件要将它们解析为纯文本却并不容易。
因此, PyPDF2 从PDF提取文本时可能会出错,甚至根本不能打开某些PDF。
遗憾的是,你对此没有什么办法, PyPDF2 可能就是不能处理某些PDF文件。
话虽这样说,我至今没有发现不能用 PyPDF2 打开的PDF文件。
从 http://nostarch.com/automatestuff/ 下载这个PDF文件,并在交互式环境中输入以下代码:
>>> import PyPDF2
>>> pdfFileObj = open('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
>>> pdfReader.numPages
19
>>> pageObj = pdfReader.getPage(0)
>>> pageObj.extractText()
'OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS Meeting of nMarch 7n, 2014n n The Board of Elementary and Secondary Education shall provide leadership and ncreate policies for education that expand opportunities for children, empower nfamilies and communities, and advance Louisiana in an increasingly ncompetitive globnal market.n BOARD n of ELEMENTARYn and n SECONDARYn EDUCATIONn '
首先,导入 PyPDF2 模块。然后以读二进制模式打开
meetingminutes.pdf ,并将它保存在 pdfFileObj 中。
为了取得表示这个PDF的 PdfFileReader 对象,调用
PyPDF2.PdfFileReader() 并向它传入 pdfFileObj 。 将这个
PdfFileReader 对象保存在 pdfReader 中。
该文档的总页数保存在 PdfFileReader 对象的 numPages
属性中。示例PDF文档有19页,但我们 只提取第一页的文本。
要从一页中提取文本,需要通过 PdfFileReader 对象 取得一个 Page
对象,它表示PDF中的一页。可以调用 PdfFileReader 对象的 getPage()
方法,向它 传入感兴趣的页码(在我们的例子中是0),从而取得 Page
对象。
PyPDF2 在取得页面时使用从0开始的下标:第一页是0页,
第二页是1页,以此类推。事情总是这样,即使文档中页面的
页码不同。例如,假定你的PDF是从一个较长的报告中抽取出
3页,它的页码分别是42、43和44,要取得这个文档的第一 页,需要调用
pdfReader.getPage(O) ,而不是 getPage(42) 或 getPage(l) 。
在取得 Page 对象后,调用它的 extractText() 方法,
返回该页文本的字符串。文本提取并不完美: 该PDF中的文本 Charles
E.“Chas”Roemer,President,在函数返
回的字符串中消失了,而且空格有时候也会没有。但是,这种近似
的PDF文本内容,可能对你的程序来说已经足够了。
解密PDF¶
某些PDF文档有加密功能,以防止别人阅读,只有在打开文档时
提供口令才能阅读。在交互式环境中输入以下代码,处理下载的
PDF,它已经用口令 rosebud 加密:
>>> import PyPDF2
>>> pdfReader =PyPDF2.PdfFileReader(open('watermark.pdf', 'rb'))
>>> # pdf Reader.isEncrypted
>>> pdfReader.getPage(0)
{'/Type': '/Page',
'/Parent': {'/Type': '/Pages', '/Count': 1, '/Kids': [IndirectObject(3, 0)]},
'/Resources': {'/Font': {'/F1': {'/Type': '/Font',
'/Subtype': '/TrueType',
'/Name': '/F1',
'/BaseFont': '/ABCDEE+Calibri',
'/Encoding': '/WinAnsiEncoding',
'/FontDescriptor': {'/Type': '/FontDescriptor',
'/FontName': '/ABCDEE+Calibri',
'/Flags': 32,
'/ItalicAngle': 0,
'/Ascent': 750,
'/Descent': -250,
'/CapHeight': 750,
'/AvgWidth': 521,
'/MaxWidth': 1743,
'/FontWeight': 400,
'/XHeight': 250,
'/StemV': 52,
'/FontBBox': [-503, -250, 1240, 750],
'/FontFile2': {'/Filter': '/FlateDecode', '/Length1': 168868}},
'/FirstChar': 32,
'/LastChar': 32,
'/Widths': [226]}},
'/ExtGState': {'/GS7': {'/Type': '/ExtGState', '/BM': '/Normal', '/CA': 1},
'/GS8': {'/Type': '/ExtGState', '/BM': '/Normal', '/CA': 0.50196},
'/GS11': {'/Type': '/ExtGState', '/BM': '/Normal', '/ca': 0.49804}},
'/XObject': {'/Image9': {'/Type': '/XObject',
'/Subtype': '/Image',
'/Width': 1237,
'/Height': 304,
'/ColorSpace': '/DeviceRGB',
'/BitsPerComponent': 8,
'/Interpolate': <PyPDF2.generic.BooleanObject at 0x7fb8c1442cf8>,
'/SMask': {'/Type': '/XObject',
'/Subtype': '/Image',
'/Width': 1237,
'/Height': 304,
'/ColorSpace': '/DeviceGray',
'/Matte': [0, 0, 0],
'/BitsPerComponent': 8,
'/Interpolate': <PyPDF2.generic.BooleanObject at 0x7fb8c14475f8>,
'/Filter': '/FlateDecode'},
'/Filter': '/FlateDecode'}},
'/ProcSet': ['/PDF', '/Text', '/ImageB', '/ImageC', '/ImageI']},
'/MediaBox': [0, 0, 612, 792],
'/Contents': {'/Filter': '/FlateDecode'},
'/Group': {'/Type': '/Group', '/S': '/Transparency', '/CS': '/DeviceRGB'},
'/Tabs': '/S',
'/StructParents': 0}
>>> # pdfReader.decrypt('rosebud')
>>> pageObj = pdfReader.getPage(0)
所有 PdfFileReader 对象都有一个 isEncrypted 属性,
如果PDF是加密的,它就是 True ,如果不是,它就是 False
。在文件用正确的口令解密之前,尝试调用函数来 读取文件,将会导致错误。
要读取加密的PDF,就调用 decrypt() 函数,传入口令字
符串。在用正确的口令调用 decrypt() 后,你会看到调用 getPage()
不再导致错误。如果提供了错误的口令, decrypt() 函数将返回0,并且
getPage() 会继续 失败。请注意, decrypt()
方法只解密了PdfFileReader 对象,
而不是实际的PDF文件。在程序中止后,硬盘上的文件仍然是
加密的。程序下次运行时,仍然需要再次调用 decrypt() 。
创建PDF¶
在 PyPDF2 中,与 PdfFileReader 对象相对的是 PdfFileWriter
对象,它可以创建一个新的PDF文件。 但 PyPDF2
不能将任意文本写入PDF,就像 Python 可以写入纯文本文件那样。
PyPDF2 写入PDF的能力,
仅限于从其他PDF中拷贝页面、旋转页面、重叠页面和加密 文件。
模块不允许直接编辑PDF。必须创建一个新的PDF,然后从已有 的文档拷贝内容。本节的例子将遵循这种一般方式:
打开一个或多个已有的PDF(源PDF),得到
PdfFileReader对象。
创建一个新的
PdfFileWriter对象。将页面从
PdfFileReader对象拷贝到PdfFileWriter对象中。最后,利用
PdfFileWriter对象写入输出的PDF。
创建一个PdfFileWriter 对象,只是在Python中创建了
一个代表PDF文档的值,这并没有创建实际的PDF文件,
要实际生成文件,必须调用 PdfFileWriter 对象的 write() 方法。
write() 方法接受一个普通的 File 对象,它以写
二进制的模式打开。你可以用两个参数调用 Python 的 open()
函数,得到这样的 File 对象:一个是要 打开的PDF文件名字符串,一个是
'wb',表明文件应该 以写二进制的模式打开。
如果这听起来有些令人困惑,不用担心,在接下来的代码 示例中,你会看到这种工作方式。
拷贝页面¶
可以利用 PyPDF2 ,从一个PDF文档拷贝页面到另一个PDF
文档。这让你能够组合多个PDF文件,去除不想要的页面,或 调整页面的次序。
从http://nostarch.com/automatestuff 下载 meetingminutes.pdf和meetingminutes2.pdf, 放在当前工作目录中。在交互式环境中输入以下代码:
>>> import PyPDF2
>>> pdf1File = open('meetingminutes.pdf', 'rb')
>>> pdf2File = open('meetingminutes2.pdf', 'rb')
>>> pdf1Reader = PyPDF2.PdfFileReader(pdf1File)
>>> pdf2Reader = PyPDF2.PdfFileReader(pdf2File)
>>> pdfWriter = PyPDF2.PdfFileWriter()
>>>
>>> for pageNum in range(pdf1Reader.numPages):
>>> pageObj = pdf1Reader.getPage(pageNum)
>>> pdfWriter.addPage(pageObj)
>>> for pageNum in range(pdf2Reader.numPages):
>>> pageObj = pdf2Reader.getPage(pageNum)
>>> pdfWriter.addPage(pageObj)
>>>
>>> pdfOutputFile = open('combinedminutes.pdf', 'wb')
>>> pdfWriter.write(pdfOutputFile)
>>> pdfOutputFile.close()
>>> pdf1File.close()
>>> pdf2File.close()
以读二进制的模式打开两个PDF文件,将得到的两个: File 对象保存在
pdf1File 和 pdf2File中。 调用 PyPDF2.PdfFiIeReader()
,传入 pdf1File , 得到一个表示 meetingminutes.pdf 的
PdfFileReader 对象。再次调用 PyPDF2.PdfFileReader() ,传入
pdf2File, 得到一个表示 meetingminutes2.pdf 的
PdfFileReader 对象。然后创建一个新的 PdfFileWriter
对象,它表示一个空白的PDF文档。
接下来,从两个源PDF拷贝所有的页面,将它们添加到 PdfFileWriter
对象。在 PdfFileReader 对象 上调用 getPage() ,取得 Page
对象。然后 将这个 Page 对象传递给 PdfFileWriter 的 addPage()
方法。这些步骤先是针对 pdf1Reader 进行, 然后再针对 pdf2Reader
进行。在拷贝页面完成后, 向 PdfFileWriter 的 write()
方法传入一个 File 对象,写入一个新的PDF文档,名为
combinedminutes.pdf。
注意
PyPDF2 不能在 PdfFileWriter 对象中间插入页面, addPage()
方法只能够在末尾添加页面。
现在你创建了一个新的 PDF 文件,将来自 meetingminutes.pdf 和
meetingminutes2.pdf 的页面组合在一个文档中。要记住,传递给
PyPDF2.PdfFileWriter()的 File
对象,需要以读二进制的方式打开。即使用'rb’作为 open()
的第二个参数。类似的,传 入
pdfWriter.write()的File对象需要以写二进制的模式打开,即使用'wb'。
旋转页面¶
利用 rotateClockwise() 和 rotateCounterClockwise()
方法,PDF文档的页面也可以旋转90度的整数倍。向这些
方法传入整数90、180或270就可以了。在交互式环 境中输入以下代码,同时将
meetingminutes.pdf 放在当前工作目录中:
>>> import PyPDF2
>>> minutesFile = open('meetingminutes.pdf','rb')
>>> pdfReader = PyPDF2.PdfFileReader(minutesFile)
>>> page = pdfReader.getPage(0)
>>> page.rotateClockwise(90)
>>> print()
>>> pdfWriter = PyPDF2.PdfFileWriter()
>>> pdfWriter.addPage(page)
>>> resultPdfFile = open('rotatedPage.pdf', 'wb')
>>> pdfWriter.write(resultPdfFile)
>>> resultPdfFile.close()
>>> minutesFile.close()
这里,我们使用 getPag(O) 来选择PDF的第一页, 然后对该页调用
rotateClockwise(90)。我们
将旋转过的页面写入一个新的PDF文档,并保存为 rotatedPage.pdf。
得到的PDF文件有一个页面,顺时针旋转了90度,如图 13-2所示。
rotateClockwise()和 rotateCounterClockwise()
的返回值包含许多信息, 你可以忽略。
图13-2 rotatedPage.pdf文件,页面顺时针旋转了90度
叠加页面¶
PyPDF2 也可以将一页的内容叠加到另一页上,这可以
用来在页面上添加公司标志、时间戳或水印。利用Python,
很容易为多个文件添加水印,并且只针对程序指定的页面添加。
从http://nostarch.com/automatestuff/ 下载watermark.pdf,将它和meetingminutes.pdf—起放在 当前工作目录中。然后在交互式环境中输入以下代码:
>>> import PyPDF2
>>> minutesFile = open('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader(minutesFile)
>>> minutesFirstPage = pdfReader.getPage(0)
>>> pdfWatermarkReader = PyPDF2.PdfFileReader(open('watermark.pdf','rb'))
>>> minutesFirstPage.mergePage(pdfWatermarkReader.getPage(0))
>>> pdfWriter = PyPDF2.PdfFileWriter()
>>> pdfWriter.addPage(minutesFirstPage)
>>>
>>> for pageNum in range(1, pdfReader.numPages):
>>> pageObj =pdfReader.getPage(pageNum)
>>> pdfWriter.addPage(pageObj)
>>>
>>> resultPdfFile = open('watermarkedCover.pdf', 'wb')
>>> pdfWriter.write(resultPdfFile)
>>> minutesFile.close()
>>> resultPdfFile.close()
这里我们生成了 meetingminutes.pdf 的 PdfFileReader 对象。调用
getPage(O) ,取得第一页的 Page 对象, 并将它保存在
minutesFirstPage 中。然后生成了 watermark.pdf 的
PdffileReader 对象, 并在 minutesFirstPage
上调用mergePage()。 传递给 mergePage() 的参数,是
watermark.pdf 第一页的 Page 对象。
既然我们已经在 minutesFirstPage 上调用了 mergePage()
,minutesFirstPage 就代 表加了水印的第-一页。我们创建一个
PdfFileWriter 对象,并加入加了水印的第一页。 然后循环遍历
meetingminutes.pdf 的剩余页面, 将它们添加到 PdfFileWriter
对象中。 最后,我们打开一个新的PDF文件 watermarkedCover.pdf ,并将
PdffileWriter 的内容写入该文件。
图 13-3 展示了结果。新的PDF文件 watermarkedCover.pdf ,包含
meetingminutes.pdf 的全部内容,并在第一页加了水印。
图13-3 最初的PDF(左边)、水印PDF(中间) 以及合并的PDF(右边)
加密PDF¶
PdfFileWriter 对象也可以为PDF文档进行加密。
在交互式环境中输入以下代码:
>>> import PyPDF2
>>> pdfFile = open('meetingminutes.pdf','rb')
>>> pdfReader = PyPDF2.PdfFileReader(pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter()
>>> for pageNum in range(pdfReader.numPages):
>>> pdfWriter.addPage(pdfReader.getPage(pageNum))
>>>
>>> pdfWriter.encrypt('swordfish')
>>> resultPdf = open('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write(resultPdf)
>>> resultPdf.close()
在调用 write() 方法保存文件之前, 调用 encrypt()
方法,传入口令字符串。 PDF可以有一个用户口令(允许查看这个PDF)和一个
拥有者口令(允许设置打印、注释、提取文本和其他功能
的许可)。用户口令和拥有者口令分别是 encrypt()的
第一个和第二个参数。如果只传入一个字符串给 encrypt()
,它将作为两个口令。
在这个例子中,我们将 meetingminutes.pdf 的页面 拷贝到
PdfFileWriter 对象。用口令 swordfish 加密了 PdfFileWriter
,打开了一个名为 encryptedminutes.pdf 的新PDF,将PdfFileWriter
的内容写入新PDF。任何人要查看 encryptedminutes.pdf,
都必须输入这个口令。在确保文件的拷贝被正确加密后,
你可能会删除原来的未加密的文件。
文本信息不仅仅是纯文本文件,实际上,很有可能更经常遇到的是 PDF和Word文档。可以利用 PyPDF2 模块来读写PDF文档。遗憾 的是,从PDF文档读取文本并非总是能得到完美转换的字符串,因为 PDF文档的格式很复杂,某些PDF可能根本读不出来。在这种情况下, 你就不太走运了,除非将来 PyPDF2 更新,支持更多的PDF功能。