入门
备注
一本包含使用PySD进行高级数据分析的简单手册的手册,请访问:http://pysd-cookbook.readthedocs.org/
该手册包括模型、示例数据和iPython笔记本形式的代码,它们演示了各种数据集成和分析任务。这些模型可以在您的本地机器上执行,并进行修改以适应您的特定分析要求。
初始化模型并开始
首先,我们必须首先加载PySD模块,并使用它导入模型文件:
>>> import pysd
>>> model = pysd.read_vensim('Teacup.mdl')
此代码创建 PySD Model class 从一个示例模型中,我们将使用它作为“Hello World”的系统动力学等价物:一杯在室温下冷却的茶。
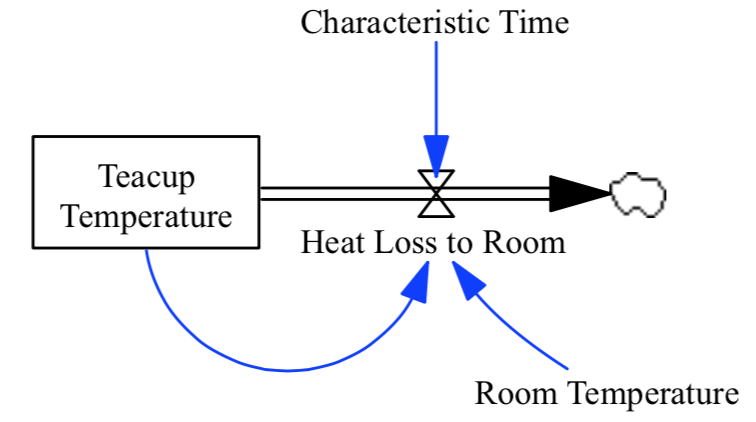
备注
茶杯模型可以在 samples of the test-models repository .
要查看模型方程和文档的概要,请使用 doc Model类的属性。这将生成所有模型元素、其文档、单位和初始值(如果适当)的列表,并将它们作为 pandas.DataFrame .以下是茶杯模型的示例::
>>> model.doc
Real Name Py Name Subscripts Units Limits Type Subtype Comment
0 Characteristic Time characteristic_time None Minutes (0.0, nan) Constant Normal How long will it take the teacup to cool 1/e o...
1 FINAL TIME final_time None Minute (nan, nan) Constant Normal The final time for the simulation.
2 Heat Loss to Room heat_loss_to_room None Degrees Fahrenheit/Minute (nan, nan) Auxiliary Normal This is the rate at which heat flows from the ...
3 INITIAL TIME initial_time None Minute (nan, nan) Constant Normal The initial time for the simulation.
4 Room Temperature room_temperature None Degrees Fahrenheit (-459.67, nan) Constant Normal Put in a check to ensure the room temperature ...
5 SAVEPER saveper None Minute (0.0, nan) Auxiliary Normal The frequency with which output is stored.
6 TIME STEP time_step None Minute (0.0, nan) Constant Normal The time step for the simulation.
7 Teacup Temperature teacup_temperature None Degrees Fahrenheit (32.0, 212.0) Stateful Integ The model is only valid for the liquid phase o...
8 Time time None None (nan, nan) None None Current time of the model.
备注
您还可以加载已转换的模型文件。这将比加载原始模型更快,因为不需要转换::
>>> import pysd
>>> model = pysd.load('Teacup.py')
备注
的功能 pysd.read_vensim() , pysd.read_xmile() 和 pysd.load() 具有高级使用的可选参数。您可以在中查看完整描述 Model loading 或使用 help() 例如::
>>> import pysd
>>> help(pysd.load)
备注
并非所有功能和功能都已实现。如果您在导入Vensim或Xmile模型时遇到麻烦,请检查 Vensim supported functions 或 Xmile supported functions .
运行模型
模拟模型的最简单方法是使用 run() 没有选项的命令。这将使用模型文件中提供的默认参数运行模型,并返回 pandas.DataFrame 每个时间戳时模型组件的值::
>>> stocks = model.run()
>>> stocks
Characteristic Time Heat Loss to Room Room Temperature Teacup Temperature FINAL TIME INITIAL TIME SAVEPER TIME STEP
0.000 10 11.000000 70 180.000000 30 0 0.125 0.125
0.125 10 10.862500 70 178.625000 30 0 0.125 0.125
0.250 10 10.726719 70 177.267188 30 0 0.125 0.125
0.375 10 10.592635 70 175.926348 30 0 0.125 0.125
0.500 10 10.460227 70 174.602268 30 0 0.125 0.125
... ... ... ... ... ... ... ... ...
29.500 10 0.565131 70 75.651312 30 0 0.125 0.125
29.625 10 0.558067 70 75.580671 30 0 0.125 0.125
29.750 10 0.551091 70 75.510912 30 0 0.125 0.125
29.875 10 0.544203 70 75.442026 30 0 0.125 0.125
30.000 10 0.537400 70 75.374001 30 0 0.125 0.125
[241 rows x 8 columns]
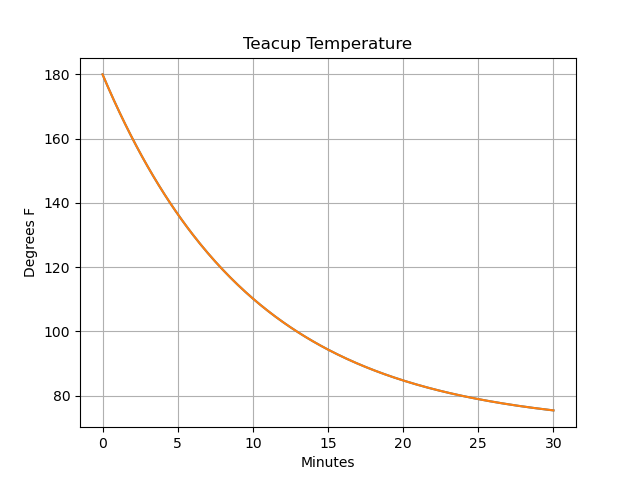
Pandas提供了一种简单的绘图功能,我们可以用它来查看茶杯的温度如何随着时间的推移而变化::
>>> import matplotlib.pyplot as plt
>>> stocks["Teacup Temperature"].plot()
>>> plt.title("Teacup Temperature")
>>> plt.ylabel("Degrees F")
>>> plt.xlabel("Minutes")
>>> plt.grid()
要在模型集成期间显示进度条, progress 参数可以传递给 run() 方法:
>>> stocks = model.run(progress=True)
备注
The full description of the run() method and other methods can be found in the Model methods section.
使用DATA类型组件运行模型
Venim允许从二进制导入数据类型数据 .vdf 文件.模型中未定义方程的变量将尝试从 .vdf . PySD允许在调用时使用data_files参数运行具有此类数据定义的模型 run() 命令,例如::
>>> stocks = model.run(data_files="input_data.tab")
可以通过使用列表传递多个文件。如果在第一个文件中找不到数据信息,则将使用下一个文件,直到找到数据值::
>>> stocks = model.run(data_files=["input_data.tab", "input_data2.tab", ..., "input_datan.tab"])
如果变量在不同的文件中定义,则可以使用字典来选择特定的文件::
>>> stocks = model.run(data_files={"input_data.tab": ["data_var1", "data_var3"], "input_data2.tab": ["data_var2"]})
备注
只 tab 和 csv 文件支持。它们应该以表格的形式给出,每个变量在一列(或一行)中,时间在第一列(或第一行)中。列(或行)的名称可以使用原始模型中变量的名称或使用python名称。
备注
- 订阅变量必须以Vensim格式给出,每个订阅组合一列(或行)。2x 2变量的列名示例:
subs var[A, C] subs var[B, C] subs var[A, D] subs var[B, D]
输出各种运行信息
的 run() 命令有一些选项使其更加有用。在许多情况下,我们希望访问模型的组件,而不仅仅是股票-我们可以通过将模型的哪些组件包括在传递给 run() 命令,使用Return_lines关键字参数::
>>> model.run(return_columns=['Teacup Temperature', 'Room Temperature'])
Teacup Temperature Room Temperature
0.000 180.000000 70
0.125 178.625000 70
0.250 177.267188 70
0.375 175.926348 70
0.500 174.602268 70
... ... ...
29.500 75.651312 70
29.625 75.580671 70
29.750 75.510912 70
29.875 75.442026 70
30.000 75.374001 70
[241 rows x 2 columns]
如果我们正在与模型进行比较的测量数据是在不规则的时间戳中出现的,那么我们可能希望在时间戳上对模型进行采样以进行匹配。的 run() 函数通过Return_timestamps关键字参数提供此功能::
>>> model.run(return_timestamps=[0, 1, 3, 7, 9.5, 13, 21, 25, 30])
Characteristic Time Heat Loss to Room Room Temperature Teacup Temperature FINAL TIME INITIAL TIME SAVEPER TIME STEP
0.0 10 11.000000 70 180.000000 30 0 0.125 0.125
1.0 10 9.946940 70 169.469405 30 0 0.125 0.125
3.0 10 8.133607 70 151.336071 30 0 0.125 0.125
7.0 10 5.438392 70 124.383922 30 0 0.125 0.125
9.5 10 4.228756 70 112.287559 30 0 0.125 0.125
13.0 10 2.973388 70 99.733876 30 0 0.125 0.125
21.0 10 1.329310 70 83.293098 30 0 0.125 0.125
25.0 10 0.888819 70 78.888194 30 0 0.125 0.125
30.0 10 0.537400 70 75.374001 30 0 0.125 0.125
检索平面数据帧
一般来说,带有后缀的变量将返回为 xarray.DataArray 在输出中 pandas.DataFrame .要获得平坦的氨纶,设置 flatten_output=True 接口中返回 run() 方法:
>>> model.run(flatten_output=True)
将模拟结果存储在文件中
模拟结果可以存储为 .csv , .tab 或 .nc (netCDF4)文件,通过在中定义所需的输出文件路径 output_file 参数,当调用 run() 方法:
>>> model.run(output_file="results.tab")
如果 output_file 未设置, run() 方法将返回一个 pandas.DataFrame .
对于大多数情况下, .tab 文件格式是最安全的选择。它比 .csv 当模型包括带后缀的变量时,格式。的 .nc 对于大型模型,以及当用户希望保留变量单位和描述等元数据时,建议使用格式。
备注
PySD包括要输出的帮助器函数 .nc 文件内容到 .csv 或 .tab 文件.看到 Exporting netCDF data_vars to csv or tab 了解详情。
警告
.nc 文件需要 netCDF4 库,这是可选要求,因此不会与包一起自动安装。我们建议使用 netCDF4 1.6.0或以上,但是,它也适用于 netCDF4 1.5.0或以上。
设置参数值
在某些情况下,我们可能想要修改模型的参数,以调查其在不同假设下的行为。在PySD中有多种方法可以做到这一点,但 run() 方法为我们提供了一个方便的方法 params 关键字参数。
此参数需要一个其键对应于模型的组件的字典。关联的值可以是常数,也可以是 pandas.Series 其索引是时间戳,其值是模型组件在相应时间应该采用的值。例如,在我们的模型中,我们可以将室温设置为恒定值::
>>> model.run(params={'Room Temperature': 20})
或者,如果我们希望室温在模拟过程中变化,我们可以给出 run() 方法一组形式的时间序列值 pandas.Series ,而PySD将在其集成过程中在给定值之间线性内插::
>>> import pandas as pd
>>> temp = pd.Series(index=range(30), data=range(20, 80, 2))
>>> model.run(params={'Room Temperature': temp})
如果要更改的参数值是带后缀的变量(vector、matrix.),有三种不同的选项来设置新值。假设我们有带Dims的“订阅var” ['dim1', 'dim2'] 并协调 {'dim1': [1, 2], 'dim2': [1, 2]} .可以使用常数值,并且所有值都将被替换::
>>> model.run(params={'Subscripted var': 0})
部分 xarray.DataArray 可以使用例如,一个带有“dim2”但不带有“dim1”的新变量。在这种情况下,结果将在剩余维度中重复::
>>> import xarray as xr
>>> new_value = xr.DataArray([1, 5], {'dim2': [1, 2]}, ['dim2'])
>>> model.run(params={'Subscripted var': new_value})
相同尺寸 xarray.DataArray 可以使用(推荐)::
>>> import xarray as xr
>>> new_value = xr.DataArray([[1, 5], [3, 4]], {'dim1': [1, 2], 'dim2': [1, 2]}, ['dim1', 'dim2'])
>>> model.run(params={'Subscripted var': new_value})
同样,a pandas.Series 可以与部分定义的常数值一起使用 xarray.DataArray 或相同尺寸 xarray.DataArray .
备注
一旦由 run() 命令时,它们会在模型中永久更改。我们还可以使用PySD更改模型参数,而无需运行模型 set_components() 方法,该方法使用与 run() 法在我们将多次运行模型并且只想设置参数一次的情况下,我们可能会选择这样做。
备注
如果您需要了解变量的维度,可以使用 get_coords() 方法:
>>> model.get_coords('Room Temperature')
None
>>> model.get_coords('Subscripted var')
({'dim1': [1, 2], 'dim2': [1, 2]}, ['dim1', 'dim2'])
如果变量是后缀,则返回coords字典和维度列表;如果变量是纯量,则返回“无”。
备注
如果您将查找函数的值更改为一个常数,则该常数值将始终使用。如果 pandas.Series 当在模型中调用该函数时,给定索引和值将用于插值,保留模型文件中包含的参数。
如果您通过常数更改任何其他变量类型的值,则将始终使用该常数值。如果 pandas.Series 当在模型中调用该函数时,将使用时间作为参数,给定索引和值用于插值。
如果您需要知道变量是否包含参数,即如果它是查找变量,则可以使用 get_args() 方法:
>>> model.get_args('Room Temperature')
[]
>>> model.get_args('Growth lookup')
['x']
设置模拟初始条件
我们模型的初始条件可以通过多种方式设置。到目前为止,我们已经使用了 initial_condition 关键字参数,即“原始”。此值根据最初在模型文件中指定的初始条件运行模型。我们可以选择指定包含开始时间的二元组和系统股票的值字典。在这里,我们以略高于冰点温度的茶开始模型::
>>> model.run(initial_condition=(0, {'Teacup Temperature': 33}))
新值可以是 xarray.DataArray ,如前一节所述。
此外,我们可以通过传递initial_condition ='当前'从当前位置向前运行模型。从时间0到30运行模型后,我们可以要求模型继续向前运行另一段时间::
>>> model.run(initial_condition='current',
return_timestamps=range(31, 45))
集成在前一运行条件中返回的最后一个值处拾取,并在请求的时间戳处返回值。
有时候我们可以选择用一个固定值覆盖一个股票(例如,为了测试)。要做到这一点,我们只需要像以前一样使用params值。当你真的想设置初始条件时,请注意不要使用“params”!
查询当前值
我们可以使用方括号轻松访问模型组件的当前值。例如,要找到茶杯的温度,我们只需调用::
>>> model['Teacup Temperature']
如果您尝试获取查找变量的当前值,则前面的方法将失败,因为查找变量需要参数。但是,可以使用 get_series_data() 方法:
>>> model.get_series_data('Growth lookup')
查看模型
有时,您可能需要运行模型的多个版本。为此,复制已经加载的模型以进行更改,同时保留未修改的模型是有用的。的 copy() 方法将有助于做到这一点;它将从转换后的文件加载新模型,并对其应用与原始模型相同的更改(修改组件、选择子模型等)。您还可以加载源模型的副本(无需应用)设置参数的任何更改 reload=True .
警告
复制函数将从文件加载新模型并对其应用相同的更改。如果这些更改中的任何一个已用引用模型中其他变量的函数替换了变量,则复制将无法正常工作,因为该函数仍然将引用原始模型中的变量,在这种情况下,应该重新定义该函数。