Pelican的一些历史¶
警告
这一页来自于2010年12月原作者(AlexisMétaireau)在写完Pelican之后写的一篇报告。这些信息可能不是最新的。
Pelican是一个简单的静态博客生成器。它解析标记文件(现在是Markdown或restructedext)并生成一个包含所有文件的HTML文件夹。我选择使用Python实现Pelican,因为它看起来很简单,并且适合我的需要。我不想为每件事都定义一个类,但仍然想让我的东西松散耦合。原来这正是我想要的。时不时,由于一些用户的反馈,我花了很长时间才提供修复程序。到目前为止,我已经对Pelican代码进行了两次重新计算,每次都不到30分钟。
用例¶
我以前使用的是WordPress,一个可以托管在web服务器上管理博客的解决方案。大多数时候,我更喜欢使用Markdown或restructedText之类的标记语言来键入我的文章。为此,我使用vim。我认为让人们选择他们想写文章的工具是很重要的。在我看来,博客管理员应该允许你接受任何类型的输入并将其转换为一个weblog。Pelican就是这么做的。您可以使用所需的工具和标记语言编写文章,然后生成静态HTML日志。
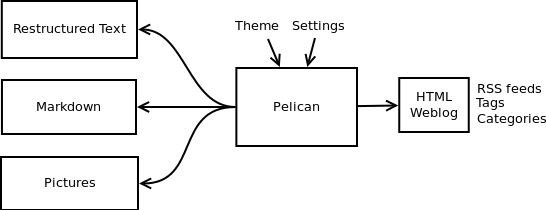
为了足够灵活,Pelican有模板支持,所以如果您愿意,您可以轻松地编写自己的主题。
设计过程¶
Pelican来自我的需要。我从创建一个单一文件应用程序开始,现在我已经使它能够支持它的功能。首先,我写了一份关于我想做什么的文件。然后,我创建了我想要解析的内容(reStructuredText文件),并开始尝试代码。Pelican有200行长,在第一次使用时包含了几乎10个函数和一个类。
我一直面临着不同的问题,我想在使用Pelican的同时添加一些特性。我做的第一个更改是添加了对设置文件的支持。可以将选项传递到命令行,但如果有很多选项,则可能会很乏味。同样,随着时间的推移,我添加了对不同事物的支持:Atom提要、多主题、多标记支持等等。在某个时候,“只有一个文件”的口号对Pelican来说似乎不够好,所以我决定重新做一点,并将其拆分为多个不同的文件。
我将逻辑划分为不同的类和概念:
作家 负责所有文件的编写过程。他们负责编写.html文件、RSS提要等。因为这些操作是常用的,所以对象只创建一次,然后传递给生成器。
读者 用于读取各种格式(目前是Markdown和restructedText,但系统是可扩展的)。给定一个文件,它们返回元数据(作者、标记、类别等)和内容(HTML格式)。
生成器 生成不同的输出。例如,Pelican附带了ArticlesGenerator和PagesGenerator,into others。给定一个配置,他们可以做任何你想让他们做的事情。大多数时候它是从输入(用户输入和文件)生成文件的。
我还处理内容对象。他们可以 Articles , Pages , Quotes 或者你想要的任何东西。它们在 contents.py 模块并表示程序要使用的一些内容。
更详细地¶
以下是Pelican相关课程的概述。
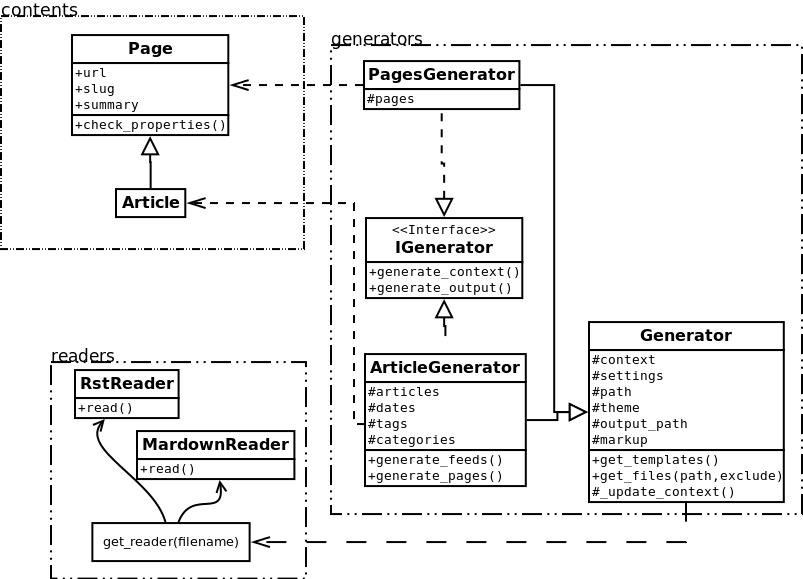
界面并不真的存在,我添加它只是为了澄清整个画面。我确实使用duck类型,而不是接口。
内部流程如下:
首先,解析命令行,并使用用户的一些内容初始化不同的生成器对象。
A
context已创建。它包含命令行中的设置和设置文件(如果提供)。这个
generate_context方法,更新上下文。writer 被创造并给予
generate_output每个生成器的方法。
我进行了两次调用,因为重要的是,当生成器生成输出时,上下文不会更改。换句话说,第一种方法 generate_context 第二,上下文应该修改 generate_output 方法不应该。
然后,由生成器来做他们想做的,在 generate_context 和 generate_content 方法。带着 ArticlesGenerator 课程将有助于理解其他一些概念。调用的时候发生了什么 generate_context 方法:
读取文件夹“path”,查找重组后的文本文件,加载每个文件,并构造一个内容对象 (
Article)用它。为此,请使用Reader物体。更新
context所有那些文章。
然后, generate_content 方法使用 context 以及 writer 产生想要的输出。