

缓存类型¶
- 作者
托马斯堡
- 联系
t在terriscope.fr的端口
此文档详细介绍了可用于存储磁贴的不同缓存后端。
磁盘高速缓存¶
基于磁盘的缓存是要配置的最简单的缓存,也是对现有分片访问最快的缓存。它非常适合小的tile存储库,但通常会给承载数百万个tile的站点带来麻烦,因为文件或目录的数量可能会迅速克服底层文件系统的功能。此外,为文件系统选择的块大小必须与存储的块的平均大小紧密匹配:理想情况下,任何给定的块都应该正好适合于文件系统块,这样就不会浪费每个块内的存储空间,也不必在每个块中使用多个块。
运行tile服务器的用户必须能够读取和写入文件/目录的位置。
通用配置¶
磁盘缓存是通过
<cache name="disk_cache" type="disk" layout="...">
...
<symlink_blank/>
<creation_retry>3</creation_retry>
</cache>
除“template”外的所有缓存都支持<symlink_blank/>选项,该选项(取决于平台可用性)将检测到统一颜色的瓷砖,并创建到单个统一颜色瓷砖的符号链接,而不是将实际空白数据存储在瓷砖的文件中。
所有缓存都支持<creation_retry>选项,该选项指定当mapcache未能创建图块的文件或symlink时应重试的次数。默认设置是立即失败:如果使用的是网络安装的文件系统,其中瞬时错误很常见,那么您可能希望将其设置为正值。
默认结构¶
默认的磁盘缓存以与tilecache使用的文件/目录层次结构几乎相同的结构存储磁贴。唯一的变化是添加了与网格名称和tileset维度的最终值相对应的顶级目录结构。
此缓存能够检测空白(即统一颜色)磁贴,并使用指向单个空白磁贴的符号链接来获取磁盘空间。
<cache name="disk" type="disk">
<base>/tmp</base>
<symlink_blank/>
</cache>
只有两个配置键是存储块的根目录,以及激活空白块符号链接的键。
ARCGIS兼容结构¶
<cache name="arcgis" type="disk" layout="arcgis">
<base>/tmp</base>
<symlink_blank/>
</cache>
此布局创建与Arcgis分解缓存兼容的平铺结构。瓷砖将存储在类似于`/tmp/tileset/grid/dimension/l z/r y/c x ext的文件中。`
全球兼容结构¶
<cache name="worldwind" type="disk" layout="worldwind">
<base>/tmp</base>
<symlink_blank/>
</cache>
此布局创建与Worldwind缓存兼容的平铺结构。瓷砖将存储在类似`/tmp/tileset/grid/dimension/z/y/y x.ext的文件中。`
模板结构¶
基于模板的磁盘缓存允许您创建(或重用)预先定义的平铺结构。<template>参数采用一个字符串参数,其中运行时将用要存储的每个图块的正确值替换各种模板条目。
<cache name="tmpl" type="disk" layout="template">
<!-- template
string template that will be used to map a tile (by tileset, grid name, dimension,
format, x, y, and z) to a filename on the filesystem
the following replacements are performed:
- {tileset} : the tileset name
- {grid} : the grid name
- {dim} : a string that concatenates the tile's dimension
- {dim:dimname}: use the dimension value for dimname e.g. {dim:year} for year=2021 would
use the string 2021
- {ext} : the filename extension for the tile's image format
- {x},{y},{z} : the tile x,y,z values
- {inv_x}, {inv_y}, {inv_z} : inverted x,y,z values (inv_x = level->maxx - x - 1). This
is mainly used to support grids where one axis is inverted (e.g. the google schema)
and you want to create on offline cache.
* Note that this type of cache does not support blank-tile detection and symlinking.
* Warning: It is up to you to make sure that the template you chose creates a unique
filename for your given tilesets. e.g. do not omit the {grid} parameter if your
tilesets reference multiple grids. Failure to do so will result in filename
collisions !
-->
<template>/tmp/template-test/{tileset}#{grid}#{dim}/{z}/{x}/{y}.{ext}</template>
</cache>
伯克利数据库缓存¶
Berkeley DB缓存后端将分片存储在一个键值平面文件数据库中,因此对于存储在文件系统上的文件数量,磁盘缓存没有任何缺点。由于映像块是连续存储的,为文件系统选择的块大小不会影响卷的存储容量。
请注意,对于给定的BDB缓存,只创建一个数据库文件,该文件将存储其关联的分片集的分片(即,没有每个分片集、网格和/或维度创建的数据库文件)。如果需要将不同的tileset存储到不同的文件中,则使用多个dbd缓存项。不能为tileset网格或维度使用多个数据库文件。
基于伯克利数据库的缓存在读取过程中比基于磁盘的缓存快一点,但如果大量线程都试图同时插入新的数据块,那么在并发写入过程中可能会慢一点。
<cache name="bdb" type="bdb">
<!-- base (required)
absolute filesystem path where the Berkeley DB database file is to be stored.
this directory must exist, and be writable
-->
<base>/tmp/foo/</base>
<!-- key_template (optional)
string template used to create the key for a tile entry in the database.
defaults to the value below. you should include {tileset}, {grid} and {dim} here
unless you know what you are doing, or you will end up with mixed tiles
<key_template>{tileset}-{grid}-{dim}-{z}-{y}-{x}.{ext}</key_template>
-->
</cache>
SQLite缓存¶
有两种不同的sqlite缓存,它们根据创建和查询的数据库模式而有所不同。sqlite缓存的优点是,它们在单个数据库文件中以blob的形式存储数据块,因此在存储的文件数量方面没有磁盘缓存的缺点。由于映像块是连续存储的,为文件系统选择的块大小不会影响卷的存储容量。
基于sqlite的缓存比基于磁盘的缓存慢一点,如果大量线程都试图同时插入新的数据块,那么在种子期可能会出现写锁定问题。
默认模式¶
图块存储在由mapcache创建的配置的sqlite文件中,
create table if not exists tiles(
tileset text,
grid text,
x integer,
y integer,
z integer,
data blob,
dim text,
ctime datetime,
primary key(tileset,grid,x,y,z,dim)
);
<cache name="sqlite" type="sqlite3">
<dbfile>/path/to/dbfile.sqlite3</dbfile>
</cache>
您还可以添加在第一次连接到sqlite数据库时将执行的自定义sqlite pragma,例如,重写在sqlite默认值中编译的某些pragma。
<cache name="sqlite" type="sqlite3">
<dbfile>/tmp/sqlitefile.db</dbfile>
<pragma name="max_page_count">10000000</pragma>
</cache>
<pragma>条目将导致调用
PRAGMA max_page_count = 1000000;
自定义模式¶
该缓存可以使用任何数据库模式:由您提供将被执行以选择或插入新的块的SQL。
为了使用这些功能,您应该提供将用于自定义架构的SQL查询。由您来确定您的查询是否正确,并将返回给定tileset、dimension、grid、x、y和z的正确数据。
<cache name="sqlitecustom" type="sqlite3">
<dbfile>/tmp/sqlitefile.db</dbfile>
<queries>
<create>create table if not exists tiles(tileset text, grid text, x integer, y integer, z integer, data blob, dim text, ctime datetime, primary key(tileset,grid,x,y,z,dim))</create>
<exists>select 1 from tiles where x=:x and y=:y and z=:z and dim=:dim and tileset=:tileset and grid=:grid</exists>
<get>select data,strftime("%s",ctime) from tiles where tileset=:tileset and grid=:grid and x=:x and y=:y and z=:z and dim=:dim</get>
<set>insert or replace into tiles(tileset,grid,x,y,z,data,dim,ctime) values (:tileset,:grid,:x,:y,:z,:data,:dim,datetime('now'))</set>
<delete>delete from tiles where x=:x and y=:y and z=:z and dim=:dim and tileset=:tileset and grid=:grid</delete>
</queries>
</cache>
注意,对于返回给定图块数据的<get>查询,第一个返回的参数被认为是图像blob,第二个可选参数是表示该图块创建时间戳的时间戳。
空白瓷砖检测¶
mapcache的sqlite缓存支持检测和存储空白(即统一颜色)图块,并将在数据blob中存储rgba颜色组件的四倍,而不是压缩图像数据本身。在返回到客户机之前,这四个接口将被动态转换为一个1位的palledpng。
<cache name="sqliteblank" type="sqlite3">
<dbfile>/tmp/sqlitefile.db</dbfile>
<detect_blank/>
</cache>
备注
使用此选项创建的sqlite文件只能被mapcache完全理解,因为每个tile blob可能包含一个rgba四重字,而不是预期的png或jpeg数据。
使用多个sqlite数据库文件¶
为了组织的目的,您可能希望将一个sqlite缓存拆分为多个文件,或者在缓存大量数据时将每个文件的大小保持在合理的限制范围内。
为此,您可以使用模板来确定应将哪个文件用于给定文件:
<cache name="sqlite" type="sqlite3">
<dbfile>/path/to/{grid}/{dim}/{tileset}.sqlite3</dbfile>
</cache>
您还可以限制要存储在单个数据库文件中的磁贴的X和Y数量:
<cache name="sqlite" type="sqlite3">
<dbfile>/path/to/{grid}/{dim}/{tileset}/{z}/{x}-{y}.sqlite3</dbfile>
<xcount>1000</xcount>
<ycount>1000</ycount>
</cache>
在这种情况下,你 should 在确定要使用的文件的模板中包括和替换项。在上一个示例中,tile(z,x,y)=(1530241534)将存储在名为/path/to/g/mytileset/15/3000-1000的文件中。sqlite3和tile(5,2,8)将存储在名为/path/to/g/mytileset/5/0-0.sqlite3的文件中。
以下模板键可用于在给定图块的X、Y和Z上操作:
` z`替换为缩放级别。
` x `替换为包含请求的图块的sqlite文件中最左边的图块的x值。
` inv_x `替换为最右边瓷砖的x值。
` y_`替换为最底部瓷砖的y值。
` inv_y_`替换为最上面瓷砖的y值。
` div_x`替换为从网格左侧开始的sqlite文件索引(即` div_x=x/<xcount>`)。
` INV_DIV_x `与DIV_x相同,但从右侧开始。
` div_y`替换为从网格底部开始的sqlite文件的索引(即` div_y/<ycount>`)。
` inv div `与div y相同,但从顶部开始。
备注
inv_x和inv_div_x可能很少使用,而inv_y和inv_y会发现喜欢从上到下而不是从下到上索引其dbfile文件的人有一些用法。
备注
替换{dim}模板的维值不能包含多个目录名(即不能包含‘/’分隔符)。在特定条件下可以绕过此限制,详情请参阅 MS RFC 131:允许MapCache二级维值中的文件路径 。
Z03-R00003-C000009.sqlite3 Z3-R3-C9.sqlite3.
<cache name="mysqlite" type="sqlite3">
<dbfile
x_fmt="%08d"
inv_y_fmt="%08d"
>/data/{tileset}/{grid}/L{z}/R{inv_y}/C{x}.sqlite</template>
</cache>
备注
如果未指定,默认行为是使用“%d”进行格式化。
在多个SQLite数据库文件中使用多个金字塔(Z-top)¶
另一种构造SQLite缓存的方法是将其组织成多个金字塔:在最低缩放级别上使用一个金字塔,然后在给定缩放级别下使用与切片一样多的金字塔,例如8个,称为 最高缩放级别 。这些棱锥体中的每一个都从该最高缩放级别的一个平铺开始,然后是下一个缩放级别的四个平铺,依此类推。当然,顶级变焦级别值是可配置的。
这种结构的主要优点是,当用户只想脱机使用世界的一个子集时:只需要复制两个(相对较小的)SQLite文件。
下图说明了此缓存结构。
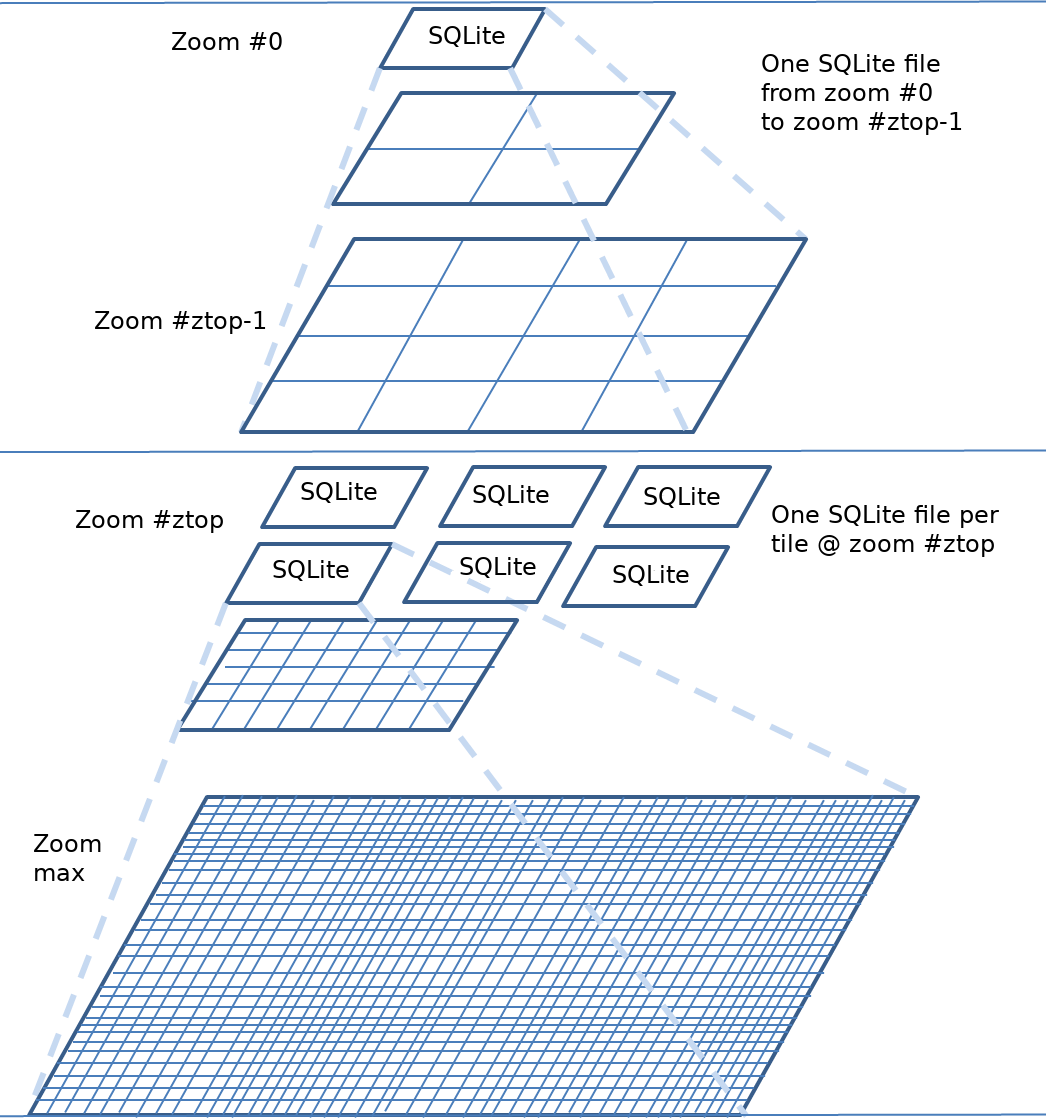
从配置的角度来看,类的多SQLite缓存 ztop 被指定为 <top> 定义最高缩放级别的标记。需要模板密钥来确定要使用的SQLite文件。
<!-- multi-pyramid, multi-SQLite, starting at zoom level 8 -->
<cache name="z8" type="sqlite3">
<top>8</top>
<dbfile top_fmt="%02d">/path/to/z{top}-{top_x}-{top_y}.sqlite3</dbfile>
</cache>
<!-- single cache from zoom levels 0 to 7 -->
<cache name="z1-7" type="sqlite3">
<dbfile>/path/to/z0-0-0.sqlite3</dbfile>
</cache>
<!-- Composite cache made of all caches to address all zoom levels -->
<cache name="zfull" type="composite">
<cache min-zoom="0" max-zoom="7">z1-7</cache>
<cache min-zoom="8">z8</cache>
</cache>
以下模板键可用:
{{top}} 替换为最高缩放级别。
{{top_x}} 被顶部缩放级别的平铺索引的x值替换,从左开始
{{top_y}} 被顶部缩放级别的平铺索引的y值替换,从底部开始。
{{inv_top_x}} 被顶端缩放级别的平铺索引的x值替换,从右开始
{{inv_top_y}} 被顶端缩放级别的平铺索引的y值替换,从顶端开始
以下格式属性可用: top_fmt , top_x_fmt , top_y_fmt , inv_top_x_fmt , inv_top_y_fmt 。它们默认为 "%d" 。
缓冲区缓存¶
此缓存类型是上一个自定义架构sqlite缓存的快捷方式,其中包含与mbtiles规范对应的预填充SQL查询。
尽管默认mbtiles模式非常简单,但mapcache使用大多数可下载mbtiles文件中的相同多表模式,尤其是在不复制编码图像数据的情况下(与磁盘缓存支持tile符号链接的方式相同),可以存储空白(即统一)tiles。
mbtiles模式创建时使用:
create table if not exists images(
tile_id text,
tile_data blob,
primary key(tile_id));
create table if not exists map (
zoom_level integer,
tile_column integer,
tile_row integer,
tile_id text,
foreign key(tile_id) references images(tile_id),
primary key(tile_row,tile_column,zoom_level));
create table if not exists metadata(
name text,
value text); -- not used or populated yet
create view if not exists tiles
as select
map.zoom_level as zoom_level,
map.tile_column as tile_column,
map.tile_row as tile_row,
images.tile_data as tile_data
from map
join images on images.tile_id = map.tile_id;
<cache name="mbtiles" type="mbtiles">
<dbfile>/Users/XXX/Documents/MapBox/tiles/natural-earth-1.mbtiles</dbfile>
</cache>
备注
与标准的sqlite mapcache模式相反,mbtiles db文件只支持每个缓存一个tileset。如果多个tileset与同一mbtiles缓存关联,则该行为未定义,并且肯定会产生不正确的结果。
警告
当处理多个进程(-p开关)和sqlite缓存后端时,在写入sqlite数据库时,在高并发性下可能会出现一些错误(错误:SQL逻辑错误或缺少数据库(1))。升级到sqlite>=3.7.15似乎可以解决这个问题。
内存缓存¶
此缓存类型将磁贴存储到运行在本地计算机上或可在网络上访问的外部memcached服务器。这种缓存类型的优点是memcached可以处理过期的数据块,因此缓存的大小永远不会超过memcache实例中配置的大小。
memcache支持需要apr-util库的更新版本。请注意,在非常高的负载下(通常只能在本地主机上的合成基准上实现),apr-util的memcache实现可能会失败,并在稍后重新联机之前每隔一段时间开始断开连接。
您可以添加多个<server>条目。
<cache name="memcache" type="memcache">
<server>
<host>localhost</host>
<port>11211</port>
</server>
</cache>
备注
存储在memcache后端的磁贴默认配置为在1天内过期。这可以在tileset级别用关键字<auto_expire>覆盖。
要限制memcache实例中空白磁贴使用的内存,可以启用空白磁贴检测,在这种情况下,“rgba”四个磁贴将存储到缓存中,而不是实际的图像数据。mapcache会在将其返回到客户机之前,将其动态转换为一个1位的palledpng图像。
<cache name="memcache" type="memcache">
<detect_blank/>
...
</cache>
(GEO)TIFF缓存¶
TIFF缓存是对缓存系列的最新添加,并使用TIFF规范的内部tile结构访问tile数据。tiles只能存储在jpeg中(tiff不支持png tiles)。
由于单个TIFF文件可能包含许多块,因此必须存储在文件系统上的文件数量急剧减少,这就解决了磁盘缓存的主要缺点。另一个优点是相同的TIFF文件可以被只理解常规GIS栅格格式的程序或WMS服务器使用,并且可以提供高性能的瓷砖访问。
暂时应将TIFF缓存视为只读。写访问已经是可能的,但应该被认为是实验性的,因为可能存在一些文件损坏问题,特别是在网络文件系统上。请注意,在给定TIFF文件中的所有图块都已播种/创建之前,TIFF文件被称为“稀疏”,因为它缺少许多JPEG图块。因此,大多数非基于gdal的程序在打开这些不完整的文件时都会遇到问题。
请注意,tiff tile结构必须与tileset使用的网格结构完全匹配,并且tiff文件名必须遵循严格的命名规则。
定义TIFF文件大小¶
必须定义每个水平和垂直方向上存储的瓷砖数量:
沿tiff文件的x(水平)方向存储的磁贴数
沿tiff文件的y(垂直)方向存储的磁贴数
<cache name="tiff" type="tiff">
<xcount>64</xcount>
<ycount>64</ycount>
...
</cache>
设置文件命名约定¶
<template>标记设置在查找给定所请求图块的x、y、z的tiff文件名时要使用的模板。
<cache name="tiff" type="tiff">
<template>/data/tiffs/{tileset}/{grid}/L{z}/R{inv_y}/C{x}.tif</template>
...
</cache>
以下模板键可用于在给定图块的X、Y和Z上操作:
x替换为包含请求的图块的TIFF文件中最左边的图块的x值。
inv_x替换为最右边的tile的x值。
Y替换为最底部瓷砖的Y值。
inv_y替换为最上面的瓷砖的y值。
Div_x替换为从网格左侧开始的TIFF文件索引(即_Div_x=x/<xCount>)。
INV_DIV_U X与_DIV_U X相同,但从右侧开始。
Div_y替换为从网格底部开始的TIFF文件索引(即_Div_y/<ycount>)。
INV_DIV_Y与_DIV_Y相同,但从顶部开始。
备注
inv_x和inv_div_x可能很少使用,而inv_y和inv_y会发现,喜欢从上到下而不是从下到上索引TIFF文件的人会使用某些用法。
自定义模板键¶
在某些情况下,对于给定的x、y、z图块查找,可能需要精确掌握文件名,例如查找名为“z03-r0003-c000009.tif”的文件,而不是仅查找“z3-r3-c9.tif”。<template>条目支持格式化属性,遵循unix printf语法(c.f.:http://linux.die.net/man/3/printf),在每个模板键后加上“fmt”,例如:
<cache name="tiff" type="tiff">
<template
x_fmt="%08d"
inv_y_fmt="%08d"
>/data/tiffs/{tileset}/{grid}/L{z}/R{inv_y}/C{x}.tif</template>
</cache>
备注
如果未指定,默认行为是使用“%d”进行格式化。
设置jpeg压缩选项¶
另一个可选参数定义在保存到TIFF文件中时应将哪些JPEG压缩应用于图块:
<format>要使用的(jpeg)格式的名称
参见
<cache name="tiff" type="tiff">
...
<format>myjpeg</format>
</cache>
在本例中,假设网格使用256x256分片,则读取以加载分片的文件是使用jpeg压缩的分片tiff,其大小为16384x16384。因此,与基本磁盘缓存相比,存储在磁盘上的文件数减少了4096倍。
使用特定的储物柜¶
mapcache需要创建一个 lock 在TIFF文件中写入时,确保没有两个实例同时更新同一文件。默认情况下,将使用全局mapcache locker;但是,您可以通过在TIFF缓存内部配置不同的锁定机制或行为来配置它。
参见
<cache name="tiff" type="tiff">
...
<locker> .... </locker>
</cache>
大地支援¶
如果使用geotiff和write支持进行编译,mapcache会将引用信息添加到它创建的tiff文件中,以便tiff文件可以在任何支持geotiff的软件中使用。写支持并不能生成完整的geotiff(使用投影的定义),而只能生成像素比例和连接点,即通常在.tfw文件中找到的内容。
以下是使用geotiff支持编译时由mapcache创建的tiff文件上的gdalinfo输出,以供参考:
LOCAL_CS["unnamed",
UNIT["metre",1,
AUTHORITY["EPSG","9001"]]]
Origin = (-20037508.342789247632027,20037508.342789247632027)
Pixel Size = (156543.033928040997125,-156543.033928040997125)
Metadata:
AREA_OR_POINT=Area
Image Structure Metadata:
COMPRESSION=YCbCr JPEG
INTERLEAVE=PIXEL
SOURCE_COLOR_SPACE=YCbCr
Corner Coordinates:
Upper Left (-20037508.343,20037508.343)
Lower Left (-20037508.343,-20037508.343)
Upper Right (20037508.343,20037508.343)
Lower Right (20037508.343,-20037508.343)
Center ( 0.0000000, 0.0000000)
休息缓存¶
以下缓存类型通过标准的HTTP GET和PUT操作存储和检索数据块,并可用于在流行的云存储提供商中存储数据块。
纯静态缓存¶
此缓存类型可用于将磁贴存储到启用WebDAV的服务器。您必须提供一个模板URL,当使用给定的x、y、z等访问图块时应使用该URL…
<cache name="myrestcache" type="rest">
<url>https://myserver/webdav/{tileset}/{grid}/{z}/{x}/{y}.{ext}</url>
</cache>
指定HTTP头¶
您可以为每个HTTP请求或特定类型的请求(例如,获取、设置或删除图块时)自定义要添加到HTTP请求的头:
<cache name="myrestcache" type="rest">
<url>https://myserver/webdav/{tileset}/{grid}/{z}/{x}/{y}.{ext}</url>
<headers>
<Host>my-virtualhost-alias.domain.com</Host>
</headers>
<operation type="put">
<headers>
<X-my-specific-put-header>foo</X-my-specific-put-header>
</headers>
</operation>
<operation type="get">
<headers>
<X-my-specific-get-header>foo</X-my-specific-get-header>
</headers>
</operation>
<operation type="head">
<headers>
<X-my-specific-head-header>foo</X-my-specific-head-header>
</headers>
</operation>
<operation type="delete">
<headers>
<X-my-specific-delete-header>foo</X-my-specific-delete-header>
</headers>
</operation>
</cache>
Amazon S3 REST缓存¶
REST缓存已经专门用于启用对AmazonS3的访问,以便添加该平台所需的身份验证/授权层。
<cache name="s3" type="s3">
<url>https://foo.s3.amazonaws.com/tiles/{tileset}/{grid}/{z}/{x}/{y}/{ext}</url>
<headers>
<Host>foo.s3.amazonaws.com</Host>
</headers>
<id>AKIE3SDEIT6TUG8DXEQI</id>
<secret>5F+dGsTfsdfkjdsfSDdasf4555d/sSff56sd/RDS</secret>
<region>eu-west-1</region>
<operation type="put">
<headers>
<x-amz-storage-class>REDUCED_REDUNDANCY</x-amz-storage-class>
<x-amz-acl>public-read</x-amz-acl>
</headers>
</operation>
</cache>
<id><secret>和<region>标记是必需的,通过Amazon管理控制台获取和配置。您应该阅读文档,了解您希望根据您的用例(提供的示例在更便宜的存储空间上承载数据块,并允许它们公开访问)向请求添加什么头。
Microsoft Azure REST缓存¶
REST缓存专门用于启用对Azure存储的访问,以便添加该平台所需的身份验证/授权层。
<cache name="azure" type="azure">
<url>https://foo.blob.core.windows.net/tiles/{tileset}/{grid}/{z}/{x}/{y}/{ext}</url>
<headers>
<Host>foo.blob.core.windows.net</Host>
</headers>
<id>foo</id>
<secret>foobarcccccccccccccccccccccyA==</secret>
<container>tiles</container>
</cache>
<id><secret>和<container>标记是必需的,通过管理控制台获取和配置。您应该阅读文档,了解根据您的用例,您希望向请求添加哪些头文件。
谷歌云存储REST缓存¶
REST缓存专门用于访问Google云存储,以便添加该平台所需的身份验证/授权层。
<cache name="google" type="google">
<url>https://storage.googleapis.com/mytiles-mapcache/{tileset}/{grid}/{z}/{x}/{y}.{ext}</url>
<access>GOOGPGDWFDG345SDFGSD</access>
<secret>sdfgsdSDFwedfwefr2345324dfsGdsfgs</secret>
<operation type="put">
<headers>
<x-amz-acl>public-read</x-amz-acl>
</headers>
</operation>
</cache>
需要使用<access>和<secret>标记,这些标记是通过管理控制台获取和配置的。您应该阅读文档,了解根据您的用例,您希望向请求添加哪些头文件。请注意,对Google云存储的支持使用其Amazon兼容层。
元缓存¶
这些缓存类型本身不存储图块,而是根据一组规则或行为将图块的存储委托给多个子缓存。这些缓存主要用于跨多个实例部署大型mapcache,具有共享缓存后端(即专用memcache服务器和网络安装的文件系统)。
复合缓存¶
此缓存根据图块的缩放级别使用不同的子缓存,并可用于将低缩放级别的图块存储到永久存储,将高缩放级别的图块存储到临时(即memcache)缓存。
<cache name="mydisk" ...> ... </cache>
<cache name="mymemcache" ...> ... </cache>
<cache name="composite" type="composite">
<cache grids="mygrid,g">mycache</cache>
<cache min-zoom="0" max-zoom="8">mydisk</cache>
<cache min-zoom="9">mymemcache</cache>
</cache>
<tileset ...>
<cache>composite</cache>
...
</tileset>
对于每个图块,将按照配置文件中定义的顺序测试缓存,并使用第一个满足最小/最大缩放和网格约束的图块。由用户来确定最小/最大缩放值和网格的连续性是否合理,例如:
<cache name="composite" type="composite">
<cache min-zoom="0">cache1</cache>
<cache min-zoom="9">this_cache_will_never_be_used</cache>
</cache>
回退缓存¶
这些缓存类型将从第一个配置的不返回错误的子缓存返回分片。当其中一个缓存容易出错时(例如远程REST缓存、memcache),可以使用它们。
<cache name="fallback" type="fallback">
<cache>mymemcache</cache>
<cache>mysqlitecache</cache>
</cache>
当将一个图块写入这样的缓存时,它将被写入所有子缓存。
多层次缓存¶
这些缓存类型可用于将快速/昂贵的缓存与慢速/廉价的缓存相结合。
<cache name="multitier" type="multitier">
<cache>fast</cache>
<cache>cheap</cache>
</cache>
如果在第一个子缓存中找不到给定的磁贴,则将从第二个子缓存中读取该磁贴。 and 复制到第一个子缓存中以供后续访问。当第一个缓存自动修剪最近使用最少的图块(即memcache图块)时,将使用此缓存类型。
当向这样的缓存中写入磁贴时,它将被写入最后一个子缓存。
缓存组合¶
所有这些元缓存可以组合在一起,根据存储成本、重新创建丢失的数据块的时间等来微调可用性和性能。
<cache name="slow_and_permanent" type="sqlite">...</cache>
<cache name="fast_and_transient" type="memcache">...</cache>
<cache name="low_zooms" type="multitier">
<cache>fast_and_transient</cache>
<cache>slow_and_permanent</cache>
<cache>
<cache name="mycache" type="composite">
<cache maxzoom="12">low_zooms</cache>
<cache>fast_and_transient</cache>
<cache>
<tileset>
<cache>mycache</cache>
...
</tileset>
在上一个示例中,所有图块主要从memcache实例访问,但是较低缩放级别的图块备份到永久的sqlite缓存,该缓存将用于填充快速memcache缓存,例如在重新启动时。
里亚克高速缓存¶
需要https://github.com/trifork/riack
<cache name="myriak" type="riak">
<server>
<host>riakhost</host>
<port>12345</port>
<bucket>mytiles</bucket>
</server>
</cache>