6.2. 数据模型¶
数据模型是描述数据内容和数据之间联系的工具,它是衡量数据库能力强弱的主要标志之一。数据库设计的核心问题之一就是设计一个好的数据模型。目前在数据库领域,常用的数据模型有:层次模型、网络模型、关系模型以及最近兴起的面向对象模型。下面以两个简单的空间实体为例(图6-1),简述这几个数据模型中的数据组织形式及其特点。
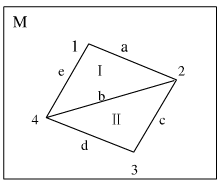
图 6-1 地图M及其空间实体ⅠⅡ
6.2.1. 传统数据模型¶
1.层次模型
层次数据库模型是用树形结构来表示实体间联系的模型。它将数据组织成一对多(或双亲与子女)关系的结构,其特点为:(1)有且仅有一个结点无双亲,这个结点即树的根;(2)其它结点有且仅有一个双亲。对于图6-1所示多边形地图可以构造出图6-2所示的层次模型。
图 6-2 层次模型
层次数据库结构特别适用于文献目录、土壤分类、部门机构等分级数据的组织。例如全国—省—县—乡是一棵十分标准的有向树,其中“全国”是根节点,省以下的行政区划单元都是子节点。这种数据模型的优点是层次和关系清楚,检索路线明确。
层次模型不能表示多对多的联系,这是令人遗憾的缺陷。在GIS中,若采用这种层次模型将难以顾及公共点、线数据共享和实体元素间的拓扑关系,导致数据冗余度增加,而且给拓扑查询带来困难。
2.网络模型
图 6-3 网络模型
用丛结构(或网结构)来表示实体及其联系的模型就是网络模型。在该模型中,各记录类型间可具有任意个连接关系。一个子结点可有多个父结点;可有一个以上的结点无父特点;父结点与某个子结点记录之间可以有多种联系(一对多、多对一、多对多)。图6-3是图6-1的网络模型。网络数据库结构特别适用于数据间相互关系非常复杂的情况,除了上面说的图形数据外,不同企业部门之间的生产、消耗联系也可以很方便地用网状结构来表示。网络数据库结构的缺点是:由于数据间联系要通过指针表示,指针数据项的存在使数据量大大增加,当数据间关系复杂时指针部分会占大量数据库存贮空间。另外,修改数据库中的数据,指针也必须随着变化。因此,网络数据库中指针的建立和维护可能成为相当大的额外负担。
3.关系模型
关系模型的基本思想是用二维表形式表示实体及其联系。二维表中的每一列对应实体的一个属性,其中给出相应的属性值,每一行形成一个由多种属性组成的多元组,或称元组(tupple),与一特定实体相对应。实体间联系和各二维表间联系采用关系描述或通过关系直接运算建立。元组(或记录)是由一个或多个属性(数据项)来标识,这一个或一组属性称为关键字,一个关系表的关键字称为主关键字,各关键字中的属性称为元属性。关系模型可由多张二维表形式组成,每张二维表的“表头”称为关系框架,故关系模型即是若干关系框架组成的集合。如图6-1所示的多边形地图,可用表6-1所示关系表示多边形与边界及结点之间的关系。
表 6-1 关系表
关系模型中应遵循以下条件:
(1) 二维表中同一列的属性是相同的;
(2) 赋予表中各列不同名字(属性名);
(3) 二维表中各列的次序是无关紧要的;
(4) 没有相同内容的元组,即无重复元组;
(5) 元组在二维表中的次序是无关紧要的。
关系数据库结构的最大优点是它的结构特别灵活,可满足所有用布尔逻辑运算和数学运算规则形成的询问要求;关系数据还能搜索、组合和比较不同类型的数据,加入和删除数据都非常方便。关系模型用于设计地理属性数据的模型较为适宜。因为在目前,地理要素之间的相互联系是难以描述的,只能独立地建立多个关系表,例如:地形关系,包含的属性有高度、坡度、坡向,其基本存贮单元可以是栅格方式或地形表面的三角面;人口关系,含的属性有人的数量、男女人口数、劳动力、抚养人口数等。基本存贮单元通常是对应于某一级的行政区划单元。
关系数据库的缺点是许多操作都要求在文件中顺序查找满足特定关系的数据,如果数据库很大的话,这一查找过程要花很多时间。搜索速度是关系数据库的主要技术标准,也是建立关系数据库花费高的主要原因。
6.2.2. 面向对象模型¶
面向对象的定义是指无论怎样复杂的事例都可以准确地由一个对象表示。每个对象都是包含了数据集和操作集的实体,即是说,面向对象的模型具有封装性的特点。
1.面向对象的概念
(1)对象与封装性(Encapsulation)
面向对象的系统中,每个概念实体都可以模型化为对象。对于多边形地图上的一个结点、一条弧段、一条河流、一个区域或一个省都可看成对象。一个对象是由描述该对象状态的一组数据和表达它的行为的一组操作(方法)组成的。例如,河流的坐标数据描述了它的位置和形状,而河流的变迁则表达了它的行为。由此可见,对象是数据和行为的统一体。
一个对象object可定义成一个三元组:
object=(ID,S,M)
其中,ID为对象标识,M为方法集,S为对象的内部状态,它可以直接是一属性值,也可以是另外一组对象的集合,因而它明显地表现出对象的递归。
(2)分类(Classification)
类是关于同类对象的集合,具有相同属性和操作的对象组合在一起。属于同一类的所有对象共享相同的属性项和操作方法,每个对象都是这个类的一个实例,即每个对象可能有不同的属性值。可以用一个三元组来建立一个类型:
class=(CID,CS,CM)
其中,CID为类标识或类型名,CS为状态描述部分,CM 为应用于该类的操作。显然有,
S∈CS 和 M=CM 当object∈class时
因此,在实际的系统中,仅需对每个类型定义一组操作,供该类中的每个对象应用。由于每个对象的内部状态不完全相同,所以要分别存储每个对象的属性值。
例如,一个城市的GIS中,包括了建筑物、街道、公园、电力设施等类型。而洪山路一号楼则是建筑物类中的一个实例,即对象。建筑物类中可能有建筑物的用途、地址、房主、建筑日期等属性,并可能需要显示建筑物、更新属性数据等操作。每个建筑物都使用建筑物类中操作过程的程序代码,代入各自的属性值操作该对象。
(3)概括(Generalization)
在定义类型时,将几种类型中某些具有公共特征的属性和操作抽象出来,形成一种更一般的超类。例如,将GIS中的地物抽象为点状对象、线状对象、面状对象以及由这三种对象组成的复杂对象,因而这四种类型可以作为GIS中各种地物类型的超类。
比如,设有两种类型
Class1=(CID1,CSA,CSB,CMA,CMB)
Class2=(CID2,CSA,CSC,CMA,CMC)
Class1和Class2中都带有相同的属性子集CSA和操作子集CMA并且
CSA∈CS1和 CSA∈CS2及 CMA∈CM1和 CMA∈CM2
因而将它们抽象出来,形成一种超类
Superclass =(SID,CSA,CMA)
这里的SID为超类的标识号。
在定义了超类以后,Class1和Class2可表示为
Class1=(CID1,CSB,CMB)
Class2=(CID2,CSC,CMC)
此时,Class1和Class2称为Superclass的子类(Subclass)。
例如,建筑物是饭店的超类,因为饭店也是建筑物。子类还可以进一步分类,如饭店类可以进一步分为小餐馆、普通旅社、宾馆、招待所等类型。所以,一个类可能是某个或某几个超类的子类,同时又可能是几个子类的超类。
建立超类实际上是一种概括,避免了说明和存储上的大量冗余。由于超类和子类的分开表示,所以就需要一种机制,在获取子类对象的状态和操作时,能自动得到它的超类的状态和操作。这就是面向对象方法中的模型工具——继承,它提供了对世界简明而精确的描述,以利于共享说明和应用的实现。
(4)联合(Association)
在定义对象时,将同一类对象中的几个具有相同属性值的对象组合起来,为了避免重复,设立一个更高水平的对象表示那些相同的属性值。
假设有两个对象
Object1=(ID1,SA,SB,M)
Object2=(ID2,SA,SC,M)
其中,这两个对象具有一部分相同的属性值,可设立新对象Object3包含Object1和Object2
Object3 =(ID3,SA,Object1,Object2,M)
此时,Object1和Object2可变为
Object1=(ID1,SB,M)
Object2=(ID2,SC,M)
Object1和Object2称为“分子对象”,它们的联合所得到的对象称为“组合对象”。联合的一个特征是它的分子对象应属于一个类型。
(5)聚集(Aggregation)
聚集是将几个不同特征的对象组合成一个更高水平的对象。每个不同特征的对象是该复合对象的一部分,它们有自己的属性描述数据和操作,这些是不能为复合对象所公用的,但复合对象可以从它们那里派生得到一些信息。例如,弧段聚集成线状地物或面状地物,简单地物组成复杂地物。
例如,设有两种不同特征的分子对象
Object1 =(ID1,S1,M1)
Object2 =(ID2,S2,M2)
用它们组成一个新的复合对象
Object3 =(ID3,S3,Object1(Su),Object2(Sv),M3)
其中Su∈S1,SV∈S2,从式中可见,复合对象Object3拥有自己的属性值和操作,它仅是从分子对象中提取部分属性值,且一般不继承子对象的操作。
在联合和聚集这两种对象中,是用“传播”作为传递子对象的属性到复杂对象的工具。即是说,复杂对象的某些属性值不单独存于数据库中,而是从它的子对象中提取或派生。例如,一个多边形的位置坐标数据,并不直接存于多边形文件中,而是存于弧段和结点文件中,多边形文件仅提供一种组合对象的功能和机制,通过建立聚集对象,借助于传播的工具可以得到多边形的位置信息。
2.GIS中的面向对象模型
(1)空间地物的几何数据模型
GIS中面向对象的几何数据模型如图6-4所示。从几何方面划分,GIS的各种地物可抽象为:点状地物、线状地物、面状地物以及由它们混合组成的复杂地物。每一种几何地物又可能由一些更简单的几何图形元素构成。例如,一个面状地物是由周边弧段和中间面域组成,弧段又涉及到结点和中间点坐标。或者说,结点的坐标传播给弧段,弧段聚集成线状地物或面状地物,简单地物组成复杂地物。
(2)拓扑关系与面向对象模型
图 6-4 面向对象的几何数据模型

图 6-5 拓扑关系与数据共享
通常地物之间的相邻、关联关系可通过公共结点、公共弧段的数据共享来隐含表达。在面向对象数据模型中,数据共享是其重要的特征。将每条弧段的两个端点(通常它们与另外的弧段公用)抽象出来,建立应该单独的结点对象类型,而在弧段的数据文件中,设立两个结点子对象标识号,即用“传播”的工具提取结点文件的信息,如图6-5所示。
这一模型既解决了数据共享问题,又建立了弧段与结点的拓扑关系。同样,面状地物对弧段的聚集方式与数据共享、几何拓扑关系的建立亦达到一致。
(3)面向对象的属性数据模型
关系数据模型和关系数据库管理系统基本上适应于GIS中属性数据的表达与管理。若采用面向对象数据模型,语义将更加丰富,层次关系也更明了。可以说,面向对象数据模型是在包含关系数据库管理系统的功能基础上,增加面向对象数据模型的封装、继承、信息传播等功能。
下面是以土地利用管理GIS为例的面向对象的属性数据模型,如图6-6所示。
图 6-6 面向对象的属性数型
GIS中的地物可根据国家分类标准或实际情况划分类型。如土地利用管理GIS的目标可分为耕地、园地、林地、牧草地、居民点、交通用地、水域、和未利用地等几大类,地物类型的每一大类又可以进一步分类,如居民点可再分为城镇、农村居民点、工矿用地等子类。另外,根据需要还可将具有相同属性和操作的类型综合成一个超类。例如工厂、农场、商店、饭店属于产业,它有收入和税收等属性,可把它们概括成一个更高水平的超类——产业类。由于产业可能不仅与建筑物有关,还可能包含其它类型如土地等。所以可将产业类设计成一个独立的类,通过行政管理数据库来管理。在整个系统中,可采用双重继承工具,当要查询饭店类的信息时,既要能够继承建筑物类的属性与操作,又要继承产业类的属性与操作。
属性数据管理中也需用到聚集的概念和传播的工具。例如,在饭店类中,可能不直接存储职工总人数、房间总数和床位总数等信息,它可能从该饭店的子对象职员数据库、房间床位数据库等数据库中派生得到。