NETCDF¶
添加netcdf数据存储¶
要添加NetCDF数据存储,用户必须转到 Stores --> Add New Store --> NetCDF .

栅格数据存储列表中的netcdf¶
配置NetCDF数据存储¶
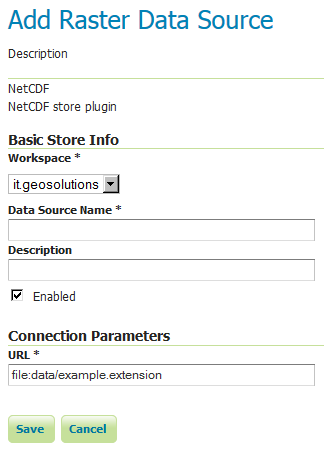
配置NetCDF数据存储¶
Option |
Description |
|
|
|
|
|
|
|
|
|
有关支持的NetCDF的说明¶
geoserver的netcdf插件支持网格化netcdf文件,这些文件的维度遵循coards约定(自定义、时间、高程、纬度、经度)。netcdf插件支持纯netcdf数据集(.nc文件)以及.ncml文件(聚合和/或修改一个或多个数据集)和功能集合。它支持预测模型运行收集聚合(fmrc),无论是通过ncml还是功能收集语法。它支持无限量的自定义维度,包括运行时。
ToolsUI 是由UCAR开发的一个有用的java工具,可以用于对数据集进行初步检查。使用该工具打开示例NetCDF将在“查看器”选项卡中显示如下输出:
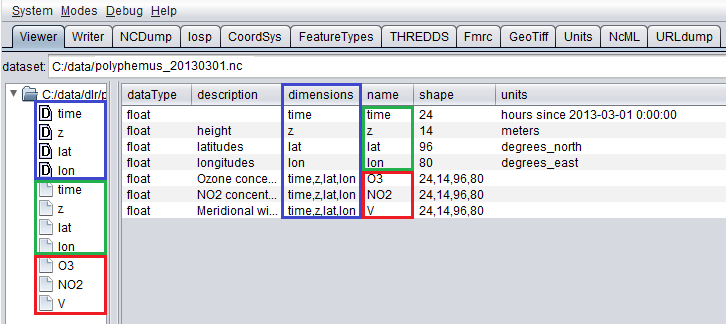
ToolsUI中的NetCDF查看器¶
这个数据集有4个维度(时间、z、lat、lon,由GUI左侧的D图标标记)。屏幕截图中的蓝色矩形标记了它们)。
每个维度都有一个关联的独立坐标变量(用绿色矩形标记)。
最后,数据集有3个地球物理变量,用一个红色矩形标记,每个都有4个维度。
NetCDF插件完全支持数据集,其中每个变量的轴由独立的坐标变量标识,如前一个示例所示。对二维坐标变量的支持有限(参见 二维坐标变量 ),作为聚合结果的一部分(例如时间、运行时-在运行时聚合的情况下)。当前不支持二维非独立经纬度坐标变量。类似的数据集在ToolsUI中将是这样的。看看红色标记的经纬度坐标变量,每个变量都由y,x 2D矩阵标识。
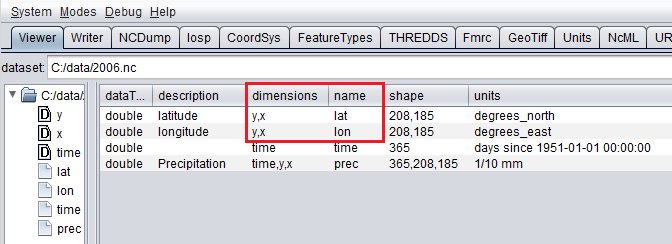
用于二维坐标变量的toolsui中的netcdf查看器¶
二维坐标变量¶
二维坐标变量在geoserver中显示为一维。它们的域在getCapabilities中作为可能值的简单列表公开。但是,它们意味着不同维度之间的相互依赖性,其中存在一些值组合(有数据),而其他组合则不存在。例如:
运行时 |
时间 |
|||
|---|---|---|---|---|
0 |
1 |
2 |
||
0 |
2017年1月1日 |
2017年1月1日 |
2017年1月2日 |
2017年1月4日 |
1 |
2017年1月2日 |
2017年1月2日 |
2017年1月3日 |
XXXX |
2 |
2017年1月3日 |
2017年1月3日 |
XXXX |
XXXX |
因此,地理服务器中的时间维度将暴露为1/1/2017、1/2/2017、1/3/2017、1/4/2017。但是,组合(运行时=1/1/2017,时间=1/3/2017),(运行时=1/2/2017,时间=1/1/2017),(运行时=1/2/2017,时间=1/4/2017),(运行时=1/3/2017,时间=1/1/2017),(运行时=1/3/2017,时间=1/2/2017)和(运行时=1/3/2017,时间=1/4/2017)不存在。
引入了一些附加功能,以最大限度地利用二维坐标变量:
对于不指定特定维度值的请求,我们希望选择对以下维度值有意义的默认值 were 在请求中指定。更具体地说,我们希望域的最大值或最小值与指定请求的其他维度值匹配;而不是整个域的最大值或最小值。
用户可能希望查询哪些维度值组合确实存在,哪些不存在。这可以通过发布整个索引的辅助向量存储来完成。
许多系统属性允许我们配置此行为:
org.geotools.coverage.io.netcdf.param.max以逗号分隔的维度列表,当请求中缺少这些维度的值时,必须将其最大化。在层配置中,这些维度的默认值必须设置为“内置”。
org.geotools.coverage.io.netcdf.param.min以逗号分隔的维度列表,当请求中缺少维度值时,必须将其最小化。在层配置中,这些维度的默认值必须设置为“内置”。
org.geotools.coverage.io.netcdf.auxiliary.store设置为TRUE可在Geoserver中显示“NetCDF Auxiliary Store”选项。必须发布NetCDF辅助存储 之后 发布实际的NetCDF存储。
对于不包含两个主要空间维度的每个可能的维度值组合,netcdf辅助存储区都返回这样的WFS记录:
<topp:my-aux-store gml:id="1">
<topp:the_geom>
<gml:Polygon srsName="http://www.opengis.net/gml/srs/epsg.xml#4326" srsDimension="2">
<gml:exterior><gml:LinearRing>
<gml:posList>259.96003054 -0.04 259.96003054 70.04 310.03999998 70.04 310.03999998 -0.04 259.96003054 -0.04</gml:posList>
</gml:LinearRing></gml:exterior>
</gml:Polygon>
</topp:the_geom>
<topp:imageindex>160</topp:imageindex>
<topp:depth>0.0</topp:depth>
<topp:time>2017-01-01T00:00:00Z</topp:time>
<topp:runtime>2017-01-02T00:00:00Z</topp:runtime>
</topp:my-aux-store>
支持自定义netcdf坐标参考系统¶
网格映射属性¶
从GeoServer 2.8.x开始,NetCDF相关模块(NetCDF/GRIB存储、基于NetCDF/GRIB数据集的imageMosaic存储和NetCDF输出格式)允许支持自定义坐标参考系统和投影。据报道 NetCDF CF documentation, Grid mappings section NetCDF CF文件可以公开gridmapping属性来描述底层投影。一个 grid_mapping 变量中的属性引用包含网格映射定义的变量的名称。
geotools netcdf机器将解析基础netcdf数据集中包含的属性(如果有),以设置ogc coordinatereferencesystem对象。创建后,将进行CRS查找,以标识用户定义的自定义EPSG(如果有),以匹配该投影。如果netcdf网格映射基本上与epsg条目相同,但没有匹配,则可以考虑调整比较容限:请参见 坐标参考系配置 , 增加比较公差段 .
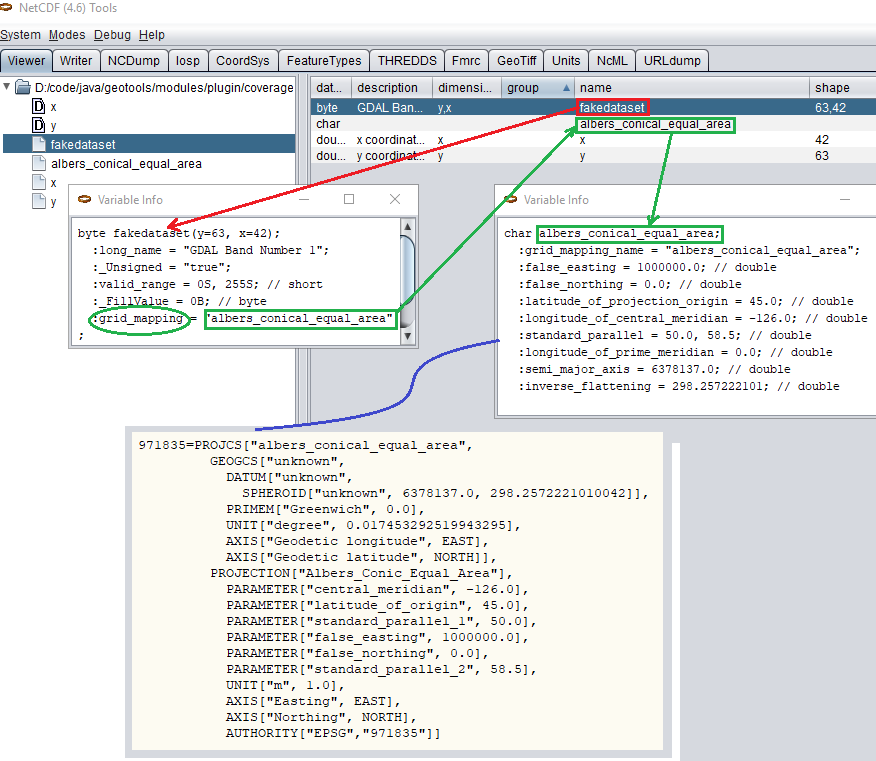
网格映射和相关的自定义EPSG定义¶
需要在中提供用户定义的NetCDF坐标参考系统及其自定义EPSG user_projections\netcdf.projections.properties 数据目录中的文件(如果缺少,则必须创建该文件)。
该属性文件中的示例条目可能如下所示:
971835=项目 ["albers_conical_equal_area", GEOGCS["unknown", DATUM["unknown", SPHEROID["unknown", 6378137.0, 298.2572221010042] ],质数 [“格林威治”,0.0] ,单位 [“度”,0.017453292519943295] ,轴 [“大地经度”,东] ,轴 [“大地纬度”,北] ],投影 ["Albers_Conic_Equal_Area"] ,参数 ["central_meridian", -126.0] ,参数 ["latitude_of_origin", 45.0] ,参数 ["standard_parallel_1", 50.0] ,参数 ["false_easting", 1000000.0] ,参数 ["false_northing", 0.0] ,参数 ["standard_parallel_2", 58.5] ,单位 [“M”,1.0] ,轴 [“东向”,东] ,轴 [“北”,北] ,权威 [“爱普生”,“971835”] ]
备注
注意geogcs、datum和spheroid元素的“未知”名称。这就是底层netcdf机器如何命名自定义元素。
备注
注意WKT前面的数字。这将决定EPSG代码。在这个例子中,epsg代码是971835。
备注
在处理基于PostGIS的记录索引时,请确保自定义代码不大于998999。(我们花了一段时间来理解为什么我们在使用PostGIS作为颗粒索引的自定义代码方面有一些问题。更多细节, here )
备注
如果“中央子午线”或“原点经度”等参数或其他经度相关值超出范围 [-180,180] ,请确保将此值调整为属于标准范围。例如,265的中央子午线应设为-95。
您可以通过向该文件添加更多行来指定进一步的自定义netcdf epsg引用。
在文件末尾插入投影的代码WKT(在单行上或使用反斜杠字符)::
971835=PROJCS["albers_conical_equal_area", \ GEOGCS["unknown", \ DATUM["unknown", \ SPHEROID["unknown", 6378137.0, 298.2572221010042]], \ PRIMEM["Greenwich", 0.0], \ UNIT["degree", 0.017453292519943295], \ AXIS["Geodetic longitude", EAST], \ AXIS["Geodetic latitude", NORTH]], \ PROJECTION["Albers_Conic_Equal_Area"], \ PARAMETER["central_meridian", -126.0], \ PARAMETER["latitude_of_origin", 45.0], \ PARAMETER["standard_parallel_1", 50.0], \ PARAMETER["false_easting", 1000000.0], \ PARAMETER["false_northing", 0.0], \ PARAMETER["standard_parallel_2", 58.5], \ UNIT["m", 1.0], \ AXIS["Easting", EAST], \ AXIS["Northing", NORTH], \ AUTHORITY["EPSG","971835"]]
保存文件。
重新启动geoserver。
如果没有列出投影,请检查日志中是否有任何错误。
轴线投影坐标(km)¶
对于GeoServer<2.16.x,以km为单位的投影坐标将自动转换为米,而相关的ProjectedCRS也以米为单位。因此,存储在几何图形表中的多边形的坐标以米为单位。
从GeoServer 2.16.x开始,为了直接支持km坐标,默认情况下将禁用从km到m的自动转换。因此,如果你想支持的话,一定要用km单位定义一个合适的自定义CRS。(如果要将索引发布为矢量层,也需要这样做)。
例如::
971815=PROJCS["albers_conical_equal_area", \
GEOGCS["unknown", \
DATUM["unknown", \
SPHEROID["unknown", 6378137.0, 298.2572221010042]], \
PRIMEM["Greenwich", 0.0], \
UNIT["degree", 0.017453292519943295], \
AXIS["Geodetic longitude", EAST], \
AXIS["Geodetic latitude", NORTH]], \
PROJECTION["Albers_Conic_Equal_Area"], \
PARAMETER["central_meridian", -126.0], \
PARAMETER["latitude_of_origin", 45.0], \
PARAMETER["standard_parallel_1", 50.0], \
PARAMETER["false_easting", 1000000.0], \
PARAMETER["false_northing", 0.0], \
PARAMETER["standard_parallel_2", 58.5], \
UNIT["km", 1000.0], \
AXIS["Easting", EAST], \
AXIS["Northing", NORTH], \
AUTHORITY["EPSG","971815"]]
注:
UNIT["km", 1000.0], \
集合 -Dorg.geotools.coverage.io.netcdf.convertAxis.km 到 true 激活自动转换或 false 去激活它。
备注
这是一个全局JVM设置:在交换转换行为之前配置坐标(单位为km)的任何数据集都需要重新配置,以设置新的几何图形和CRS。
通过系统属性指定外部文件¶
也可以通过设置 Java系统特性 指向指定文件的链接。例如: -Dnetcdf.projections.file=/full/path/of/the/customfile.properties
WKT属性¶
一些netcdf可能包含一个文本属性,其中包含坐标参考系的wkt定义。当存在时,geoserver将解析它以设置CRS,并执行查找以查看是否有任何epsg匹配它。
- spatial_ref
GDAL spatial_ref 属性
- esri_pe_string
只读目录中的netcdf文件¶
geoserver在访问netcdf文件时创建隐藏的索引文件。由于这些索引文件与每个netcdf文件在同一目录中创建,因此如果缺少对包含目录的写入权限,geoserver将无法发布netcdf文件。
要允许访问只读目录中的NetCDF文件,请通过设置 NETCDF_DATA_DIR Java系统属性:
-DNETCDF_DATA_DIR=/path/to/writeable/index/file/directory
支持自定义netcdf单元¶
netcdf格式使用一种我们的单元解析器并不总是能理解的语法来表示单元,并且通常使用不可识别的符号或简单未知的单元名称。系统已经有了一些智能,但是如果一个单元不能被识别,就可以对配置进行操作并对其进行扩展。
可以设置两个属性文件来修改单元映像,一个是别名文件,另一个是替换文件:
“别名”是基本单元的不同符号/名称(例如,netcdf文件可能使用“grammes”,而不是使用“g”)。
(文本)“替换”用于当单元是派生单元、需要完整表达式或单元语法无法识别时。
别名文件被调用 netcdf-unit-aliases.properties ,如果未提供这些内容,则假定:
# Aliases for unit names that can in turn be used to build more complex units
Meter=m
meter=m
Metre=m
microgram=µg
microgrammes=µg
nanograms=ng
degree=deg
percentage=%
celsius=°C
````
替换文件被调用 netcdf-unit-replacements.properties ,如果未提供,则假定以下内容:
microgrammes\ per\ cubic\ meter=µg*m^-3
DU=µmol*m^-2*446.2
m2=m^2
m3=m^3
s2=s^2
两个文件都将netcdf单元表示为密钥,并将标准符号或替换文本表示为值。
可以将文件放在三个不同的位置:
如果
NETCDF_UNIT_ALIASES和/或NETCDF_UNIT_REPLACEMENTS定义了系统变量,将在指定位置查找相应的文件(必须是完整路径,包括文件名)如果上面缺少,并且外部NetCDF data dir是通过
NETCDF_DATA_DIR然后文件会在里面查到如果上面缺少,将搜索geoserver数据目录的根目录。
如果上面没有提供文件,那么将使用内置配置
缓存¶
打开NetCDF文件时,需要设置元数据和结构,例如坐标参考系和相关坐标系、可选的数据存储配置、Coverages结构(模式和尺寸)。根据文件本身的复杂程度,这些任务可能非常耗时。持续和重复访问相同文件的操作将受此影响。因此,从Geoserver 2.20.x开始,已经设置了缓存机制。
可以考虑的一些实体 static 解析后在内部缓存:它们包括数据存储区属性文件上的NetCDF数据存储区配置设置、在辅助XML文件上构建的索引器以及变量的度量单位。
备注
如果其中一个配置文件被修改或更新,请确保重新加载Geoserver,以清除缓存并允许使用新设置。
文件缓存¶
可以手动启用附加级别的缓存,以便可以缓存和重复使用NetCDF文件。缓存的对象不是整个文件,而是一个 NetcdfDataset 对象,该对象构建在分析的元数据之上,包括坐标系信息。无论何时访问NetCDF数据集,都会提供一个缓存的实例,并在访问完成后释放回缓存池。因此,如果有10个并发请求访问相同的NetCDF文件,则最多将使用10个不同的NetCDF数据集缓存实例。
可以设置以下Java系统变量来启用和配置文件缓存:
org.geotools.coverage.io.netcdf.cachefile:布尔型。将其设置为True可启用数据集缓存。(默认:FALSE,无文件缓存)org.geotools.coverage.io.netcdf.cache.min:表示要保存在缓存中的数据集的最小数量的整数值(默认值:200)。org.geotools.coverage.io.netcdf.cache.max:整数值,表示触发清理之前要在缓存中保留的最大数据集数量(默认值:300)。org.geotools.coverage.io.netcdf.cache.cleanup.period:表示下一次缓存清理之前的时间段(以秒为单位)的整数值(0表示不定期清理,默认为12分钟)
备注
在启用文件缓存并设置NetCDF的ImageMosaic时,请考虑从Coverage配置中禁用延迟加载,以便底层读取器可以访问NetCDF数据集,并在读取完成后立即释放它们。
NetCDF文件的马赛克¶
设置基本马赛克¶
NetCDF文件的马赛克与通常有所不同,因为每个NetCDF文件可以包含多个Coverage。因此,马赛克设置需要额外的配置文件, indexer.xml 充当马赛克索引,并使用 _auxiliary.xml 描述了NetCDF文件的内容。
设置这些文件可能是一个繁琐的过程,因此已经编写了一个实用程序,该实用程序根据样例NetCDF文件自动填充它们的内容(假设马赛克中的所有NetCDF文件共享相同的变量和尺寸)。
给定一个样例NetCDF文件,您可以进入马赛克目录并运行 CreateIndexer 工具(对于NetCDF投影文件,请参见上文)。在Windows上:
java -cp <path-to-geoserver>\WEB-INF\lib\*.jar org.geotools.coverage.io.netcdf.tools.CreateIndexer <path-to-sample-nc-file> [-p <path-to-netcdf-projections>] [<path-to-output-directory>]
在Linux上:
java -cp '<path-to-geoserver>/WEB-INF/lib/*' org.geotools.coverage.io.netcdf.tools.CreateIndexer <path-to-sample-nc-file> [-p <path-to-netcdf-projections>] [<path-to-output-directory>]
警告
在较早的Geoserver版本上,该命令可能会失败,并报告找不到 org.jaxen.NamespaceContext 。如果是这样,请下载 Jaxen 1.1.6 ,将其添加到地理服务器中 WEB-INF/lib 目录,然后重试。
这将生成文件,如果每个NetCDF包含相同的Coverage就足够了。这个 indexer.xml 文件可能如下所示:
<?xml version="1.0" encoding="UTF-8"?><Indexer>
<domains>
<domain name="time">
<attributes><attribute>time</attribute></attributes>
</domain>
</domains>
<coverages>
<coverage>
<name>dbz</name>
<schema name="dbz">
<attributes>
the_geom:Polygon,imageindex:Integer,location:String,time:java.util.Date
</attributes>
</schema>
<domains>
<domain ref="time" />
</domains>
</coverage>
</coverages>
<parameters>
<parameter name="AuxiliaryFile" value="/path/to/the/mosaic/_auxiliary.xml" />
<parameter name="AbsolutePath" value="true" />
</parameters>
</Indexer>
而当 _auxiliary.xml 文件可能如下所示:
<?xml version="1.0" encoding="UTF-8"?><Indexer>
<coverages>
<coverage>
<schema name="dbz">
<attributes>
the_geom:Polygon,imageindex:Integer,time:java.util.Date
</attributes>
</schema>
<origName>dbz</origName>
<name>dbz</name>
</coverage>
</coverages>
</Indexer>
如果在同一马赛克中存在包含不同Coverage的不同NetCDF文件,则必须:
为每个Coverage使用不同的样例NetCDF文件运行上述命令,并在不同的文件夹中生成输出。
手动将它们合并到统一的
indexer.xml和_auxiliary.xml它将被放置在马赛克目录中。
NetCDF文件通常包含时间维度,因此,不可能依赖基于shapefile的索引,而是使用关系数据库。因此,添加一个 datastore.properties 文件放到马赛克目录中,指向所选的数据库。以下是一个适用于连接到启用了PostGIS的数据库的示例文件,该文件具有专用于包含马赛克索引的架构(确保它已存在于数据库中,Geoserver不会创建它):
SPI=org.geotools.data.postgis.PostgisNGDataStoreFactory
host=localhost
port=5432
database=netcdf
schema=mosaic_indexes
user=user
passwd=pwd
Loose\ bbox=true
Estimated\ extends=false
validate\ connections=true
Connection\ timeout=10
preparedStatements=true
max\ connections=20
有了这些,就可以在Geoserver中创建商店和层:
创建一个新的图像马赛克存储,指向马赛克目录。
经过一些处理后,应该会出现可用Coverage的列表,准备创建层。
创建每个层,并记住在“维度”选项卡中配置时间、海拔和自定义维度。
如果在设置过程中出现错误,应采用以下建议:
删除马赛克可能在马赛克目录中创建的所有额外文件。
删除数据库中最终创建的新表。
启用
GeoTools developer logging全局设置中的配置文件。再次运行马赛克创建,检查日志以找出原因(通常是由于数据库权限或不符合CF约定的NetCDF文件)。
从顶部开始重复,直到马赛克创建成功。
将NetCDF内部索引存储在集中索引中¶
默认情况下,netcdf reader会创建一个隐藏目录,作为侧视图或netcdf data dir,其中包含一个低级索引文件以加快切片查找,以及一个h2数据库,其中包含有关切片索引和与其关联的维度的信息。每次读取关联的netcdf时,都会打开和关闭此h2存储区,从而导致地图渲染的性能低于最佳性能。
作为替代方案,可以将H2中的所有切片元数据存储到一个集中的数据库中,并让Geoserver管理与其连接的存储,从而使其始终处于打开状态。人们认为,要实现这一目标,需要做一些工作。
第一步,创建名为的存储连接属性文件 netcdf_datastore.properties 。以下是一个适用于连接到启用了PostGIS的数据库的示例文件,它使前面介绍的 datastore.properties **
SPI=org.geotools.data.postgis.PostgisNGDataStoreFactory
host=localhost
port=5432
database=netcdf
schema=netcdf_indexes
user=user
passwd=pwd
Loose\ bbox=true
Estimated\ extends=false
validate\ connections=true
Connection\ timeout=10
preparedStatements=true
max\ connections=20
注意NetCDF索引将如何存储在不同的数据库模式中,以防止最终的表名冲突(同样,请确保该模式已存在于数据库中)。
需要将此新配置文件通知Geoserver,方法是编辑 indexer.xml 文件,并在参数部分添加以下新行:
<parameter name="AuxiliaryDatastoreFile" value="netcdf_datastore.properties" />
这个 _auxiliary.xml 文件也需要修改,请打开它并更改 attributes 元素(S),添加一个 location:String 属性紧跟在 imageIndex:Integer 属性(位置很重要,如果属性放错位置,则马赛克构建将失败):
<attributes>the_geom:Polygon,imageindex:Integer,location:String,time:java.util.Date</attributes>
此时,可以从图形用户界面重复马赛克构造,就像正常的NetCDF图像马赛克一样。
将带有h2 netcdf索引文件的镶嵌迁移到集中索引¶
而上面的设置允许对NetCDF文件内容进行集中索引。如果已经有NetCDF文件的(非常)大图像马赛克,则必须重新获取NetCDF文件可能非常耗时,而且通常不切实际。
已经创建了一个实用程序来执行现有马赛克到集中式数据库索引的迁移,即 H2Migrate 工具。
在Windows上:
java -cp <path-to-geoserver>/WEB-INF/lib/*.jar org.geotools.coverage.io.netcdf.tools.H2Migrate -m <path-to-mosaic-directory> -is <indexPropertyFile> -v
在Linux上:
java -cp '<path-to-geoserver>/WEB-INF/lib/*' org.geotools.coverage.io.netcdf.tools.H2Migrate -m <path-to-mosaic-directory> -is <indexPropertyFile> -v
该工具还支持其他选项,可以在不带任何参数的情况下运行工具来发现它们。
警告
在较早的Geoserver版本上,该命令可能会失败,并报告找不到 org.apache.commons.cli.ParseException 。如果是这样,请下载 commons-cli 1.1.4 ,将其添加到地理服务器中 WEB-INF/lib 目录,然后重试。
H2Migrate 将使用indexPropertyFile中的信息连接到目标存储,检查镶嵌内容定位要迁移的粒,创建 netcdf_index.properties 文件包含 StoreName=storeNameForIndex 并更新镶嵌以使用它(基本上,更新indexer.xml和所有Coverage属性文件以具有 AuxiliaryDatastoreFile 属性指向 netcdf_indexer.properties )。
它还会生成两个文件, migrated.txt 和 h2.txt :
migrated.txt包含已成功迁移的文件列表,用于审核目的
h2.txt现在可以删除的H2数据库文件的列表。该工具不会自动执行,以确保迁移,但使用此工具可以自动删除,例如,在Linux上cat h2.txt | xargs rm会做这个把戏(<name>.log.db文件经常更名,很可能不得不用其他方法搜索并删除它们,例如,如果在Linux上,使用“find”)。
如果要迁移的马赛克有 OpenSearch 索引,则工具将无法打开马赛克(需要在GeoServer中运行),因此连接参数将必须在第二个属性文件中提供,以及包含“location”属性中的颗粒路径的表列表,例如:
java-cp<path to geoserver>/WEB-INF/lib/ * .jar文件org.geotools.coverage网站.io.netcdf.工具.H2Migrate-m<path to mosaic directory>-ms<mosaicStorePropertyFile>-mit granular-is<indexPropertyFile>-is<storeNameForIndex>-v
成功迁移后,需要执行最后一个手动步骤。和以前一样, _auxiliary.xml 文件也需要修改。打开它并更改 attributes 元素(S),添加一个 location:String 属性紧跟在 imageIndex:Integer 属性(位置很重要,如果属性间隔错误,则马赛克构建将失败):
<attributes>the_geom:Polygon,imageindex:Integer,location:String,time:java.util.Date</attributes>
同样,找到包含类似配置的索引器的每个XML文件,并添加参数 AuxiliaryDatastoreFile 参数:
<parameter name="AuxiliaryDatastoreFile" value="<path/to/mosaic/directory/>netcdf_datastore.properties" />
最后,对每个Coverage的属性文件执行相同的操作,添加:
AuxiliaryDatastoreFile=<path/to/mosaic/directory/>netcdf_datastore.properties
通向 netcdf_datastore.properties 也可以是相对的,但仅当图像马赛克配置为使用相对路径时。
如果Geoserver在移植过程中正在运行,则需要重置刚刚移植的马赛克存储,以便它再次读取其配置:转到马赛克存储,打开其配置,在不更改任何参数的情况下再次保存它:马赛克支持的层现在可以使用了。