主键¶
为了在表上启用事务性扩展(对于事务性WFS),该表必须具有主键。没有主键的表被视为对geoserver是只读的。
geoserver有一个公开主键值的选项(使过滤器更容易)。请记住,这些值仅为您的方便而公开-任何试图使用WFS-T更新修改这些值的操作都将被静默忽略。当主键值用于定义FeatureID时,就有了这个限制。如果必须更改FeatureID,则可以使用WFS-T删除和添加单个事务请求来定义替换功能。
PostGIS 是基于 PostgreSQL 是目前最流行的开放源码空间数据库之一。
与所有格式一样,将shapefile添加到geoserver涉及将新存储添加到现有存储 商店 通过 Web管理界面 .
要开始,请导航到 .
填写 基本商店信息 用于在管理层时标识数据库。
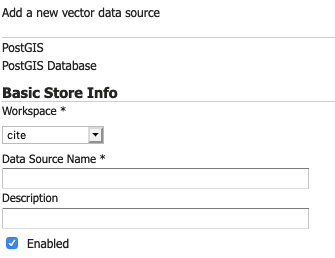
添加PostGIS数据库¶
基本商店信息 |
描述 |
|---|---|
Workspace |
要包含数据库的工作区的名称。这也将是从数据库中的表创建的任何层名称的前缀。 |
Data Source Name |
数据库的名称。这可能与PostgreSQL/Postgis已知的名称不同。 |
Description |
数据库/存储的描述。 |
Enabled |
启用商店。如果禁用,将不提供数据库中的数据。 |
转到用于连接数据库和与数据库交互的连接参数。
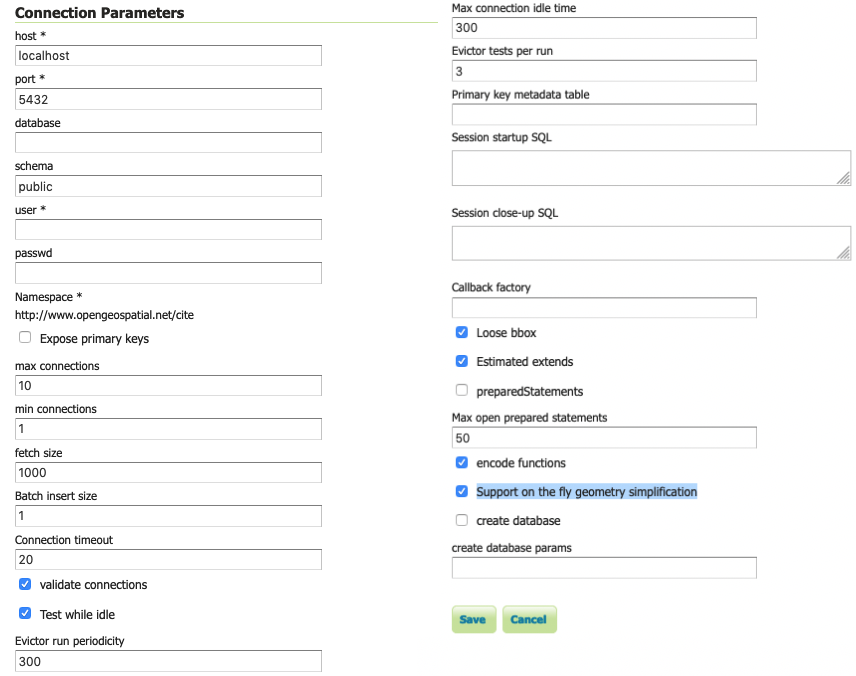
PostGIS连接参数¶
这个 dbtype 和 namespace 连接参数不可直接编辑。这个 dbtype 参数仅供内部使用(并且只能通过REST API访问)。
连接参数 |
描述 |
|---|---|
dbtype |
数据库的类型。内部值,将此值保留为默认值。 |
namespace |
要与数据库关联的命名空间。通过更改工作区名称可以更改此字段。 |
建立数据库连接的连接参数(请参见 数据库连接池 ):
连接参数 |
描述 |
|---|---|
host |
数据库所在的主机名。 |
port |
连接到上述主机的端口号。 |
database |
主机上已知的数据库名称。 |
schema |
以上数据库中的架构。 |
user |
连接到数据库的用户名。 |
passwd |
与上述用户关联的密码。 |
max connections |
与数据库的最大打开连接数。 |
min connections |
最小池连接数。 |
fetch size |
每次与数据库交互时读取的记录数。 |
Connection timeout |
连接池将在超时前等待的时间(秒)。 |
validate connections |
使用前检查连接是否处于活动状态。 |
Evictor run periodicity |
空闲对象收回器运行之间的秒数。 |
Max connection idle time |
在Evictor开始考虑关闭连接之前,连接需要保持空闲的秒数。 |
Evictor tests per run |
空闲连接收回器为其每次运行检查的连接数。 |
管理SQL生成的连接参数:
连接参数 |
描述 |
|---|---|
Expose primary keys |
将主键列公开为适合筛选的值。 |
Primary key metadata table |
提供定义如何生成主键值的表(请参见 控制空间数据库中特征ID的生成 ) |
Session startup SQL |
SQL在使用前应用于连接(请参见 自定义SQL会话启动/停止脚本 ) |
Session close-up SQL |
使用后应用于连接的SQL(请参见 自定义SQL会话启动/停止脚本 ) |
preparedStatements |
为SQL生成而不是文本替换启用准备好的语句。 |
Max open prepared statements |
可用的已准备语句数。 |
管理数据库交互的连接参数:
连接参数 |
描述 |
|---|---|
Loose bbox |
仅对边界框执行主过滤器。请参见 使用松散边界框 有关详细信息。 |
Estimated extends |
使用空间索引快速估计边界,而不是检查每一行。 |
Encode functions |
将支持的筛选函数生成到它们的等效SQL中。 |
Support on the fly geometry simplification |
允许使用PostGIS几何简化 |
支持初始数据库创建的连接参数:
连接参数 |
描述 |
|---|---|
create database |
启用以在连接时定义新数据库 |
create database params |
其他创建数据库定义,示例 WITH TEMPLATE=postgis |
完成后,单击 Save .
地理服务器还可以使用 JNDI (Java命名和目录接口)。
要开始,请导航到 .
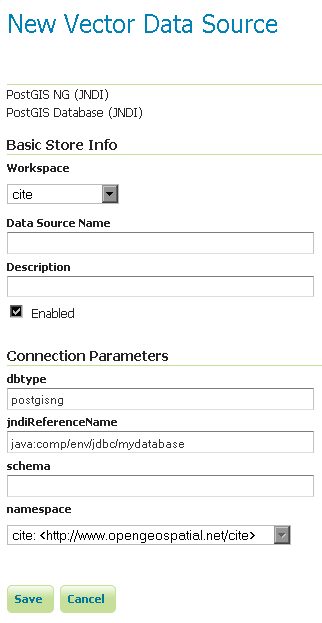
添加PostGIS数据库(使用JNDI)¶
期权 |
描述 |
|---|---|
Workspace |
要包含存储的工作区的名称。这也是从存储创建的所有层名称的前缀。 |
Data Source Name |
数据库的名称。这可能与PostgreSQL/Postgis已知的名称不同。 |
Description |
数据库/存储的描述。 |
Enabled |
启用商店。如果禁用,将不提供数据库中的数据。 |
dbtype |
数据库的类型。将此值保留为默认值。 |
jndiReferenceName |
数据库的JNDI路径。 |
schema |
上述数据库的架构。 |
namespace |
要与数据库关联的命名空间。通过更改工作区名称可以更改此字段。 |
完成后,单击 Save .
正确加载后,数据库中的所有表对geoserver都可见,但在geoserver提供服务之前,它们需要单独配置。请参见 层 有关如何添加和编辑新图层的信息。
当选择 loose bbox 如果启用,则仅使用几何体的边界框。这可能会导致显著的性能提高,但会牺牲总的精度;某些几何图形在技术上不是这样的情况下,可以考虑在边界框内。
如果主要通过WMS连接到此数据,则可以安全设置此标志,因为通常可以接受某些精度的损失。但是,如果使用WFS,特别是使用bbox过滤功能,则不应设置此标志。
发布视图的过程与发布表的过程相同。唯一的附加步骤是手动确保视图在 geometry_columns 桌子。
例如,考虑一个带有模式的表:
my_table( id int PRIMARY KEY, name VARCHAR, the_geom GEOMETRY )
还要考虑以下视图:
CREATE VIEW my_view as SELECT id, the_geom FROM my_table;
在geoserver提供此视图之前,需要执行以下步骤手动创建 geometry_columns 条目::
INSERT INTO geometry_columns VALUES ('','public','my_view','my_geom', 2, 4326, 'POINT' );
GEOS (几何引擎,开源)是PostGIS安装的可选组件。建议将geos与geoserver使用的任何postgis实例一起安装,因为这允许geoserver在执行空间操作时利用其功能。当GEO不可用时,这些操作会在内部执行,这会导致性能下降。
强烈建议在具有空间组件(即包含几何图形列)的表上创建空间索引。任何没有空间索引的表都可能对查询响应缓慢。
为了在表上启用事务性扩展(对于事务性WFS),该表必须具有主键。没有主键的表被视为对geoserver是只读的。
geoserver有一个公开主键值的选项(使过滤器更容易)。请记住,这些值仅为您的方便而公开-任何试图使用WFS-T更新修改这些值的操作都将被静默忽略。当主键值用于定义FeatureID时,就有了这个限制。如果必须更改FeatureID,则可以使用WFS-T删除和添加单个事务请求来定义替换功能。
要插入多行文本(用于标签),请记住使用转义文本:
INSERT INTO place VALUES (ST_GeomFromText('POINT(-71.060316 48.432044)', 4326), E'Westfield\nTower');
GeoServer能够翻译 jsonPointer 函数转换为使用PostgreSQL对JSON类型的支持的查询。实施的主要特点如下:
jsonPointer函数语法如下: jsonPointer(attributeName,'/path/to/json/attribute') .
该函数可以通过指定json路径eg中的目标元素的索引来选择json数组中的属性。 '/path/to/array/element/0' .
当访问JSON属性时,隐式地假设同一属性在所有特性上都具有相同的类型,否则数据库将抛出cast异常。
GeoServer将自动对计算中的expect类型执行强制转换;强制转换完全委托给数据库。
如果该属性不存在,则不会发出错误,但具有该属性的功能将被排除;因此,我们希望查询的属性并非在所有功能中都是强制的。
有一个json列存储json值,如下所示,
{ "name": "city name",
"description": "the city description",
"districts": [
{
"name":"district1",
"population": 2000
},
{
"name":"district2",
"population": 5000
}
]
"population":{
"average_age": 35,
"toal": 50000
}
}
假设属性名为 city ,有效的jsonPointer函数为:
jsonPointer(city, '/name') .
jsonPointer(city, '/population/average_age') .
jsonPointer(city, '/districts/0/name') .
一个cql_过滤器的例子是 jsonPointer(city, '/population/average_age') > 30 .
而sld样式表中的示例规则可以是:
<Rule>
<Name>Cities</Name>
<ogc:Filter>
<ogc:PropertyIsEqualTo>
<ogc:Function name="jsonPointer">
<ogc:PropertyName>city</ogc:PropertyName>
<ogc:Literal>/population/average_age</ogc:Literal>
</ogc:Function>
<ogc:Literal>35</ogc:Literal>
</ogc:PropertyIsEqualTo>
</ogc:Filter>
<PointSymbolizer>
<Graphic>
<Mark>
<WellKnownName>square</WellKnownName>
<Fill>
<CssParameter name="fill">#FF0000</CssParameter>
</Fill>
</Mark>
<Size>16</Size>
</Graphic>
</PointSymbolizer>
</Rule>
PostgreSQL定义了两种JSON数据类型:
json它存储输入文本的精确副本。
jsonb它以分解的二进制格式存储值。
jsonPointer函数既支持这两种格式,也支持文本格式(如果它包含有效的json表示)。无论如何,PostgreSQL文档推荐使用jsonb,因为它处理起来更快。
PostgreSQL还支持json类型的索引。可以按如下方式创建特定json属性的索引:
CREATE INDEX description_index ON table_name ((column_name -> path -> to ->> json_attribute )) .
也可以部分指定索引:
CREATE INDEX description_index ON table_name ((column_name -> path -> to ->> json_attribute )) WHERE (column_name -> path -> to ->> json_attribute) IS NOT NULL .