Microsoft Azure上的GeoMesa文件系统¶
可以在Azure Blob存储上使用GeoMesa文件系统,同时使用临时的Azure批处理集群运行ApacheSpark分析。这种运行GeoMesa的模式具有成本效益,因为存储(相对便宜)和计算(相对昂贵,但只有在需要时才收费)分开。下面的指南描述了如何设置Azure批处理集群,获取一些数据,然后在Jupyter笔记本中使用Spark(Scala)进行分析。
先决条件¶
您将需要具有足够信用的Microsoft Azure帐户或适当的支付方式。作为指南,运行本教程中的步骤的费用应该不超过5美元。如果您还没有帐户,您可以注册免费试用 here 。
安装和配置Azure分布式数据工程工具包¶
本指南使用 Azure Distributed Data Engineering Toolkit (AZTK) 以便建立一个短暂的星团。或者,您可能希望部署更永久的 Azure HDInsight 集群。后一种选择不在这里讨论,但后续操作中的大部分都是常见的。
请遵循 AZTK instructions 安装AZTK。
警告
确保选择与最新版本匹配的文档的正确分支(而不是 main )。
备注
建议将AZTK安装在 Anaconda environment ,或一个 Python virtual environment 。
总之,要安装AZTK:
pip install aztk在您选择的目录中,
aztk spark init使用 Azure Cloud Shell 以及
account_setup.sh要生成其内容的脚本.aztk/secrets.yaml为了你。或者,您也可以手动创建必要的资源组、批处理帐户、存储帐户等。或者,生成ssh密钥对并引用
.aztk/secrets.yaml。
备注
您可能需要注册 Microsoft.Batch provider in your Azure account. Check in the Azure Portal 在订阅...订阅名称...设置...资源提供程序下。
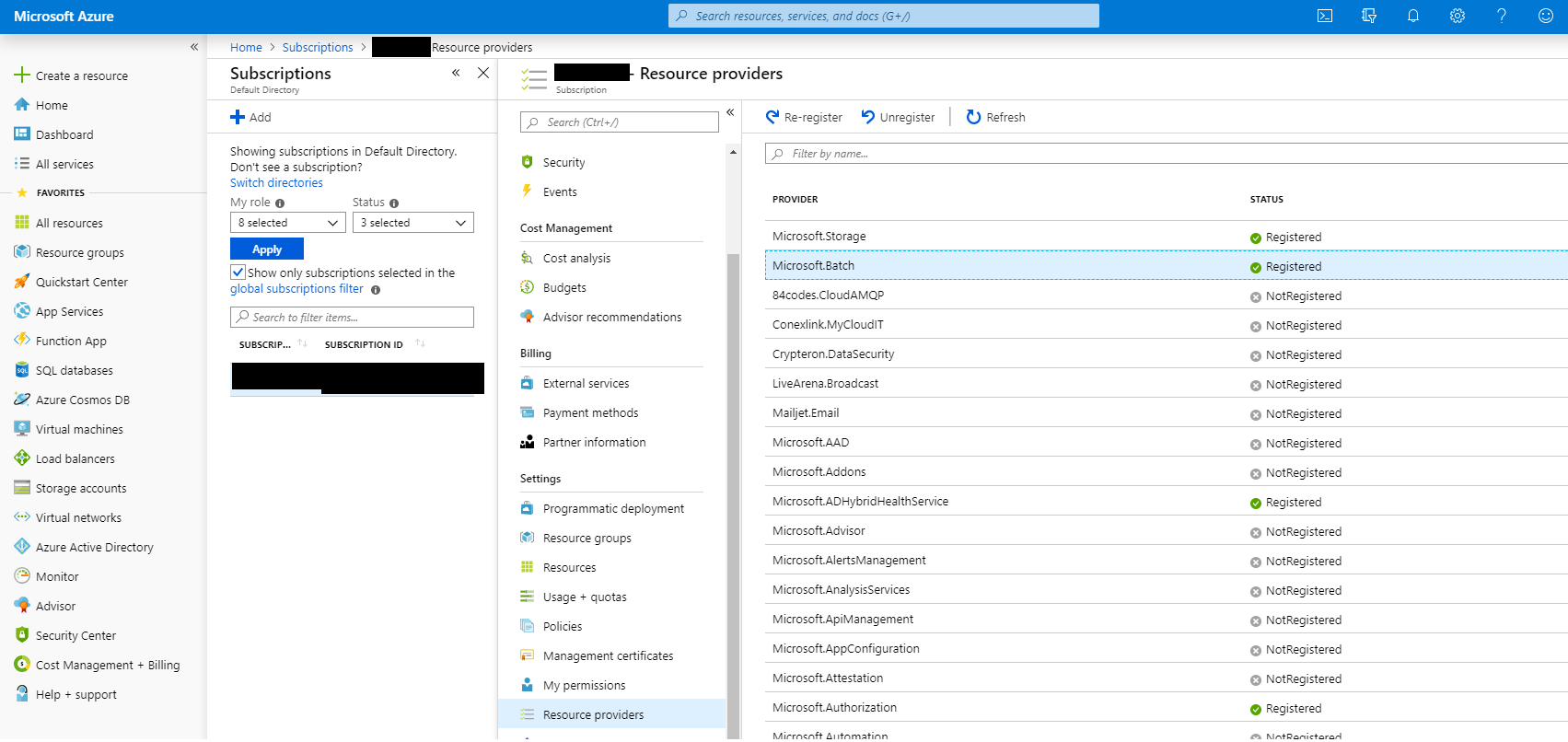
Microsoft Azure资源提供程序¶
警告
你的 secrets.yaml 文件现在包含敏感数据,应进行相应保护。
自定义群集默认配置¶
编辑 .aztk/cluster.yaml 详情如下:
注释掉
size:line. We will specify the cluster size on the command line and specifying the size here will cause issues with mixed normal and low priority nodes unless additional network configuration is performed (beyond the scope of this guide, but covered here )。集
environment: anaconda。确保
jupyter插件是 not 启用(我们稍后将手动安装Jupyter,以便添加Spark Scala支持)。集
worker_on_master至false要禁用在主服务器本身上运行的Apache Spark Executor,请执行以下操作。
定制Hadoop集群配置¶
将以下行添加到 .aztk/core-site.xml 要使Hadoop能够通过安全的 (wasbs )协议。替换 [storage account name] 和 [key] 具有适当的值。
<property>
<name>fs.AbstractFileSystem.wasbs.impl</name>
<value>org.apache.hadoop.fs.azure.Wasbs</value>
</property>
<property>
<name>fs.wasbs.impl</name>
<value>org.apache.hadoop.fs.azure.NativeAzureFileSystem</value>
</property>
<property>
<name>fs.azure.account.key.[storage account name].blob.core.windows.net</name>
<value>[key]</value>
</property>
警告
你的 core-site.xml 文件现在包含敏感数据,应进行相应保护。
创建用于接收的ApacheSpark集群¶
我们将首先创建一个最小的ApacheSpark集群,并使用主服务器下载和获取一些数据:
aztk spark cluster create --id geomesa --vm-size standard_f2 --size-low-priority 2 --docker-run-options="--privileged"
这应该会开始使用低优先级(即较便宜)节点创建集群。集群部署为每个节点上的Docker容器; --privileged 才能装载您刚刚创建的Azure文件共享。
如果您没有使用ssh密钥,系统将提示您输入 spark user. You can monitor cluster creation progress using aztk spark cluster list & aztk spark cluster get --id geomesa. You can also monitor cluster creation and status using Batch Explorer 。当所有节点都显示为空闲状态时,集群即为就绪状态,通常需要5-10分钟:
aztk spark cluster get --id geomesa
Cluster geomesa
------------------------------------------
State: steady
Node Size: standard_f2
Created: 2019-08-30 15:07:36
Nodes: 2
| Dedicated: 0
| Low priority: 2
| Nodes | State | IP:Port | Dedicated | Master |
|------------------------------------|---------------------|----------------------|------------|----------|
|tvmps_b2e6b9f170b73fe9f993d3e0f1cd2a40cd49041b54dfbf9774fbc07b2c883b03_p| idle | 51.105.13.125:50001 | | * |
|tvmps_cfd27f38197a963a04cb8363d6012067fd1d38ecb4fa86a406f89ed3e8f57154_p| idle | 51.105.13.125:50000 | | |
连接到群集¶
通常你会使用 aztk spark cluster ssh 为了连接到集群,通过ssh为各种服务转发有用的端口。但是,我们需要为Jupyter添加一个端口转发,因此改为执行以下操作:
aztk spark cluster ssh --id geomesa -u spark --no-connect
-------------------------------------------
spark cluster id: geomesa
open webui: http://localhost:8080
open jobui: http://localhost:4040
open jobhistoryui: http://localhost:18080
ssh username: spark
connect: False
-------------------------------------------
Use the following command to connect to your spark head node:
ssh -L 8080:localhost:8080 -L 4040:localhost:4040 -L 18080:localhost:18080 -t spark@51.105.13.125 -p 50001 'sudo docker exec -it spark /bin/bash'
使用提供的命令连接到您的群集,但需要进行以下更改:
增列
-L 8888:localhost:8888为了另外把木星送到前线(仅限Windows,当使用
cmd.exe) remove the single quotes around thesudo docker...指挥部。
输入您的私钥密码或您为 spark 用户,您应该会在运行ApacheSpark的Docker容器中获得一个根Shell。
root@883aa5f49ee64425964d1eb085366173000001:/#
备注
除非另行指定,否则所有后续命令都应在此容器内运行。
安装和配置GeoMesa文件系统CLI¶
为了获取数据,我们首先需要安装和配置GeoMesa文件系统CLI工具。替换 ${VERSION} 使用的是GeoMesa和Scala版本(例如 2.12-4.0.2 ):
cd /mnt/geomesa
wget https://github.com/locationtech/geomesa/releases/download/geomesa_${VERSION}/geomesa-fs_${VERSION}-bin.tar.gz
tar -xzvf geomesa-fs_${VERSION}-bin.tar.gz
备注
您可能需要更新GeoMesa版本以匹配最新版本。
为了在Azure Blob存储上使用GeoMesa文件系统,您需要复制以下JAR,并设置Hadoop配置目录环境变量,以便您的 core-site.xml 文件已被拾取。
cd /home/spark-current/jars
cp azure-storage-2.2.0.jar \
commons-configuration-1.6.jar \
commons-logging-1.1.3.jar \
guava-11.0.2.jar \
hadoop-auth-2.8.3.jar \
hadoop-azure-2.8.3.jar \
hadoop-common-2.8.3.jar \
hadoop-hdfs-client-2.8.3.jar \
htrace-core4-4.0.1-incubating.jar \
jetty-util-6.1.26.jar \
/mnt/geomesa/geomesa-fs_${VERSION}/lib
export HADOOP_CONF_DIR=/home/spark-current/conf
将数据接收到Azure Blob存储中¶
我们将首先从以下位置下载2.6 GB压缩数据 Marine Cadastre 。该文件包含大约7000万条船舶使用信标定位的记录 AIS 2017年7月在墨西哥湾。更多的数据可以从海洋地籍以及许多商业供应商那里获得。
cd /mnt/geomesa
mkdir data
cd data
wget https://coast.noaa.gov/htdata/CMSP/AISDataHandler/2017/AIS_2017_07_Zone15.zip
Optional :我们可以按如下方式测试转换器。
cd /mnt/geomesa/geomesa-fs_${VERSION}/bin
./geomesa-fs convert \
--spec marinecadastre-ais-csv \
--converter marinecadastre-ais-csv \
--max-features 10 \
../../data/AIS_2017_07_Zone15.zip
备注
在编写您自己的转换器时,强烈建议使用 convert 命令用于在摄取之前进行迭代测试。
接下来,我们可以按如下方式获取数据:
./geomesa-fs ingest \
--path wasbs://<blob container name>@<storage account>.blob.core.windows.net/<path> \
--encoding orc \
--partition-scheme daily,z2-20bits \
--spec marinecadastre-ais-csv \
--converter marinecadastre-ais-csv \
../../data/AIS_2017_07_Zone15.zip
你应该换掉 <blob container name> , <storage account> 和 <path> 具有与您的环境相适应的值。
备注
因为我们的数据非常集中在特定的区域,所以我们使用大量的位来表示 z2 指数。在更现实的情况下,索引精度是从存储中读取大数据块(倾向于较低精度)和最小化离散文件或BLOB访问数量(倾向于较高精度)之间的权衡。这将取决于您的数据分布和访问/查询模式。
安装Jupyter、GeoMesa Jupyter宣传单和阿帕奇工具¶
在创建了我们的ApacheSpark集群并获取了一些数据之后,我们几乎准备好运行一些分析了。我们将结合使用Jupyter笔记本电脑平台和用于ApacheSpark的ApacheToree内核来执行交互式可伸缩分析。为了使我们的结果可视化,我们将使用GeoMesa Jupyter叶积分。
Optional :在使用最小的集群进行接收之后,您现在可能希望使用更多的节点来提高性能和可分析的数据集的大小。如果是,请删除您的现有集群 (aztk spark cluster delete --id=geomesa ),并像以前一样创建一个新节点,从而增加节点数量 (--size 和/或 --size-low-priority )和/或单个节点大小 (--vm-size )。请记住重新挂载Azure文件共享和导出 HADOOP_CONF_DIR 。
返回到主节点上的ApacheSpark容器中,运行以下命令:
cd /mnt/geomesa
pip install toree
wget https://repo1.maven.org/maven2/org/locationtech/geomesa/geomesa-spark-jupyter-leaflet_2.12/${VERSION}/geomesa-spark-jupyter-leaflet_${VERSION}.jar
jupyter toree install \
--spark_home=/home/spark-current \
--replace \
--spark_opts="--master spark://`hostname -i`:7077 --num-executors 2 --conf spark.dynamicAllocation.enabled=false --jars /mnt/geomesa/geomesa-fs_${VERSION}/dist/spark/geomesa-fs-spark-runtime_${VERSION}.jar,/mnt/geomesa/geomesa-spark-jupyter-leaflet_${VERSION}.jar"
如果您已增加了群集的大小,则还应增加 --num-executors 相应地。属性来设置其他执行器和驱动程序选项 spark_opts 内容。
运行Jupyter并打开笔记本¶
最后,我们将克隆教程存储库以获得样例笔记本,然后启动Jupyter:
git clone https://github.com/geomesa/geomesa-tutorials
jupyter notebook --allow-root &
警告
您可能需要签出 geomesa-tutorials 存储库,以便与您的GeoMesa文件系统版本匹配。
然后在您的本地机器上打开Jupyter提供的URL,包括LONG令牌。导航到 geomesa-fs-on-azure 然后打开 GeoMesa FileSystem on Azure.ipynb 。按照你自己的步调看笔记本。

显示GeoMesa单张集成的Jupyter笔记本¶
您可以通过以下方式访问ApacheSpark Master界面 http://localhost:8080 ,和通过以下方式提供的Apache Spark作业界面 http://localhost:4040 。

ApacheSpark Master用户界面¶
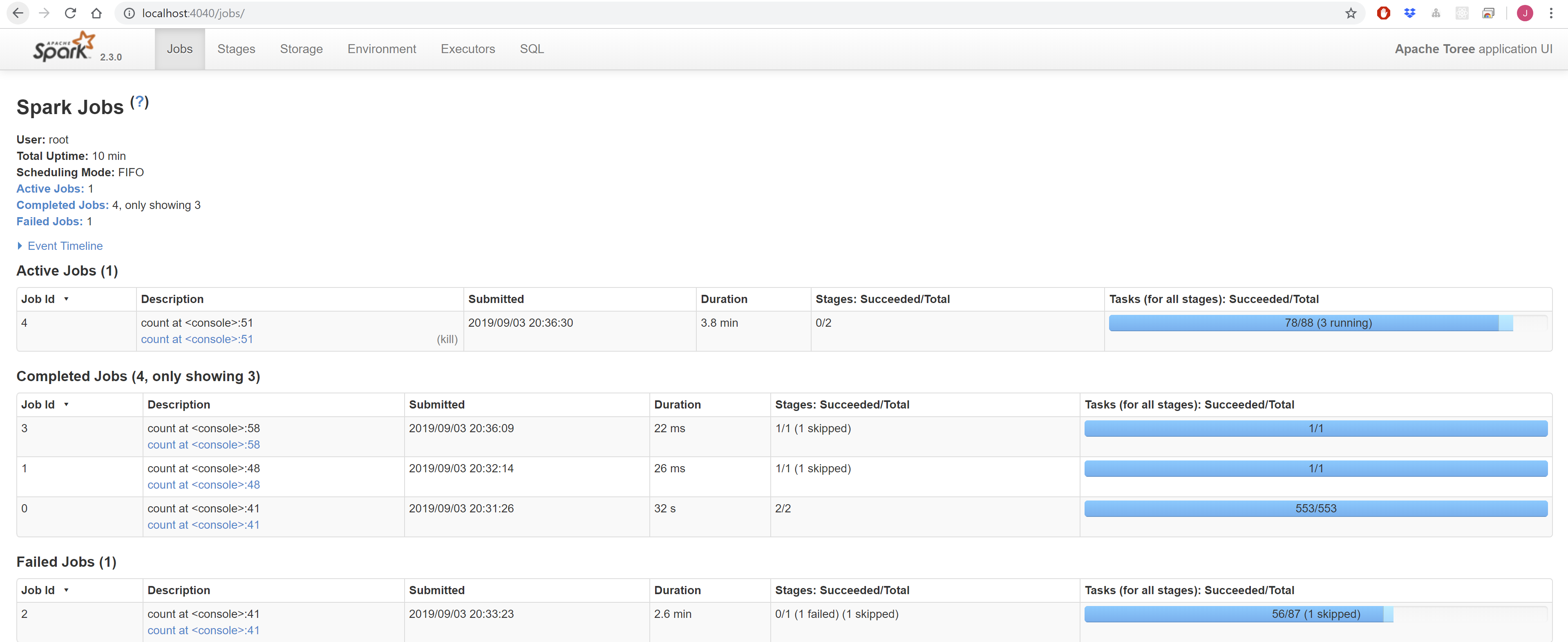
阿帕奇火花作业用户界面¶
删除您的临时群集¶
重要的是,记住在使用完Azure批处理集群后将其删除,否则 will 招致意想不到的费用。
aztk spark cluster delete --id=geomesa