Geohash范围¶
对(几何图形、日期-时间)对进行编码只有在可以快速找到这些编码条目时才有用。这是查询规划者的工作。在这篇文章中,我们提出了GeoMesa中的查询规划者必须克服的一个挑战:如何识别覆盖查询多边形的Geohash前缀。
索引地理时间数据¶
Accumulo --GeoMesa的主要支持数据存储--是一个分布式的、排序的键值存储,其中唯一的系统级索引是键的词典顺序。索引地理时间数据的问题是找到一种合理的方法将三个维度的数据--经度、纬度和时间--展平为一个维度:Acumulo键列表。具体的展平由索引架构格式、可定制的 space-filling curve 它交错了位置的一部分 Geohash 日期-时间字符串的一部分。
下面的动画描绘了一条简单的空间填充曲线,其中的索引模式格式是遵循“YXTTYXTTYX”模式的10位,时间维度表示在Z轴上。这种编码是GeoMesa用作默认索引模式格式的简化版本。

时空立方体前面的两个色带表示单元标识符的单个逻辑列表(在前景中);以及相同的列表,其中每个单元被随机分配到四个分区中的一个(在背景中,每个分区由色带旁边的灰色或黑色条纹标识)。
计划查询¶
如果您记住了前面的时空立方体的图像,那么您可能会直觉地认为,查询计划实际上是落入所需地理区域和时间间隔内的连续单元格区域的列表。例如,假设我们有这样的查询:
-180≤经度<45
-90≤纬度<22.5
0<时间<9(在此插图中,取值范围为0到16)
这相当于三个维度中每一个最低值的一半多一点。在全局键列表和切分的键列表中直观地选择单元格及其位置如下图所示:

本例使用10位编码,因此多维数据集中只有1024个单元。默认的GeoMesa索引模式格式在编码中使用了超过55位,导致超过36千万亿个可能的单元,因此详尽的搜索将花费太长的时间而不实用。幸运的是,用于编码位置的Geohash和用于编码日期时间的字符串都是分层的:编码以“0100”开始的Geohash包含Geohash“01000”、“01001”、“010001011”以及编码以这四个数字开始的所有其他Geohash。日期的作用类似,因为2014年包括所有12个月以及所有365天。为了简化讨论,我们将省略日期部分,重点关注查询规划器如何识别连续的Geohash值的范围。
该算法¶
在Scala风格的伪代码中,算法是:
// assume that any Geohash that makes it into this function
// is already known to intersect the query polygon
def getGeohashPrefixes(gh: Geohash): Set = {
// if this Geohash is at the maximum precision,
// simply return it
if (gh.precision >= precision) gh
else {
// if the Geohash is wholly contained in the target
// polygon, we need look no further: all of its
// children will also be wholly contained, because
// they nest
if (polygon.contains(gh)) gh
else {
// recurse into all children that intersect the
// query polygon, but start with the child whose
// centroid is closer to that of the target
val leftChild = GeoHash(gh.binaryString + "0")
val rightChild = GeoHash(gh.binaryString + "1")
if (distance(polygon, leftChild) <= distance(polygon, rightChild) {
// the left child is closer, so start there
(if (polygon.intersects(leftChild) getGeohashPrefixes(leftChild) else Nil) +
(if (polygon.intersects(rightChild) getGeohashPrefixes(rightChild) else Nil)
} else {
// right right child is closer, so start there
(if (polygon.intersects(rightChild) getGeohashPrefixes(rightChild) else Nil) +
(if (polygon.intersects(leftChild) getGeohashPrefixes(leftChild) else Nil)
}
}
}
}
// fetch all prefixes that intersect the target polygon,
// starting with the 0-bit Geohash, the entire world
getGeoHashPrefixes(GeoHash())
这是一个动画GIF,它展示了在给定一个大致接近美国大陆的查询多边形的情况下,该算法如何逐步识别精度小于或等于10位的Geohash前缀:
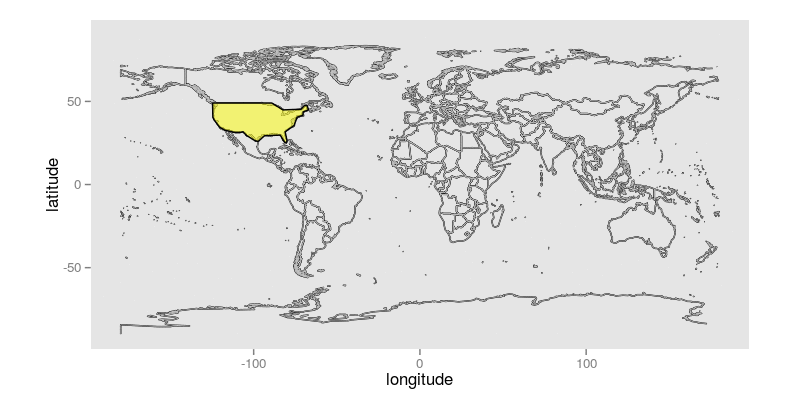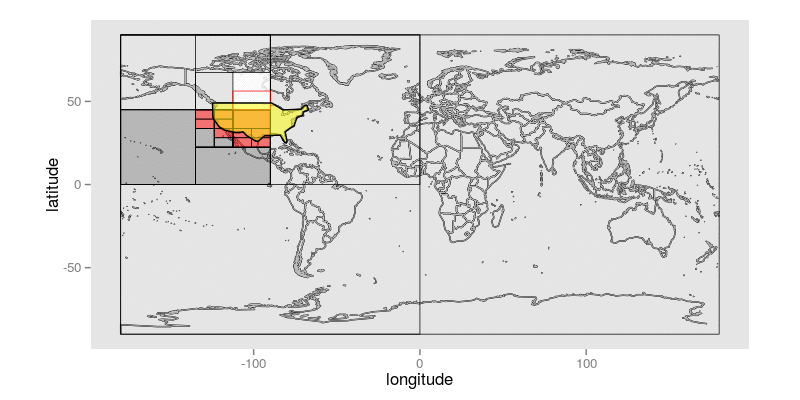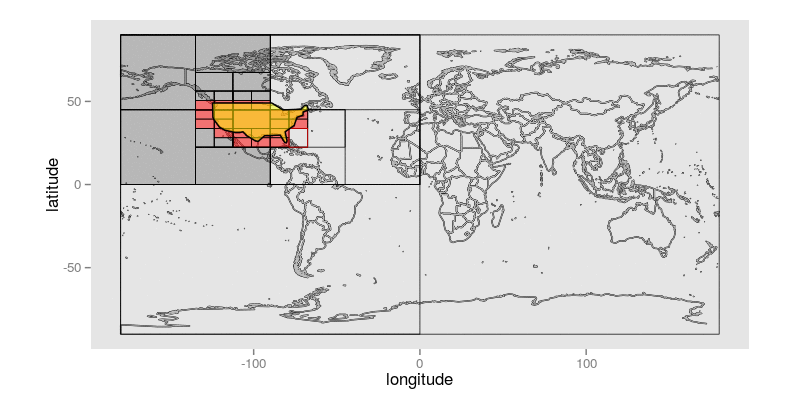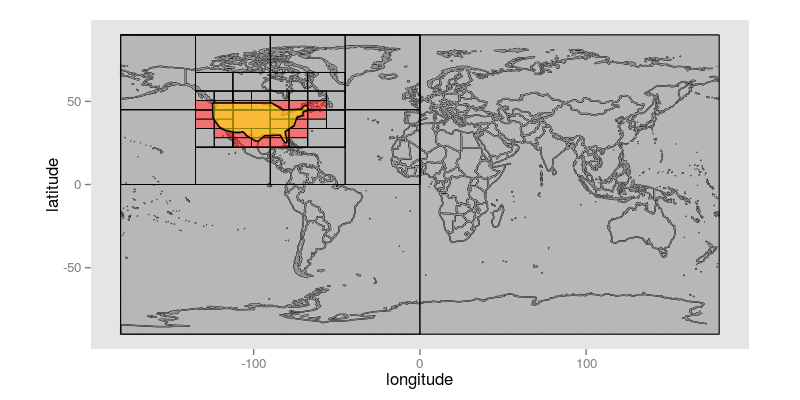
查询多边形显示为黄色。与查询多边形相交的每个非终端Geohash都带有白色阴影和红色正方形,指示其两个子对象中的哪一个将是第一个考虑的候选对象。未着色的Geohash是尚未显式访问的Geohash;带红色阴影的Geohash是构成保留在最终结果集中的前缀的Geohash;带深灰色阴影的Geohash是已被拒绝的Geohash,因为它们根本不与目标面相交。
对该算法的讨论比较粗略,部分原因是它在整个查询过程中的作用已被简化,以简化本简短说明中的说明。在查询规划器中使用的完整版本可以在 getUniqueGeohashSubstringsInPolygon 方法,它使GeoMesa能够快速高效地枚举较大Geohash的唯一子字符串,从而加快整个查询规划过程。
增编¶
如果你仍然感兴趣,你可能会成为GeoMesa的一个很好的贡献者。请便吧!在此期间,以下是一些提供额外背景的主题: