3.2.1. 观点介绍¶
视图有许多用途:
- 过滤数据库中的文档以查找与特定进程相关的文档。
- 从文档中提取数据并按特定顺序显示。
- 构建有效的索引,以根据文档中驻留的任何值或结构查找文档。
- 使用这些索引来表示文档之间的关系。
- 最后,使用视图,您可以对文档中的数据进行各种计算。例如,如果文档表示公司的财务事务,则视图可以回答上一周、每月或一年的开支情况。
3.2.1.1. 什么是风景?¶
让我们看看不同的用例。第一种是按特定的顺序提取特殊用途所需的数据。对于首页,我们需要按日期排序的博客文章标题列表。我们将在浏览视图的工作方式时使用一组示例文档:
{
"_id":"biking",
"_rev":"AE19EBC7654",
"title":"Biking",
"body":"My biggest hobby is mountainbiking. The other day...",
"date":"2009/01/30 18:04:11"
}
{
"_id":"bought-a-cat",
"_rev":"4A3BBEE711",
"title":"Bought a Cat",
"body":"I went to the the pet store earlier and brought home a little kitty...",
"date":"2009/02/17 21:13:39"
}
{
"_id":"hello-world",
"_rev":"43FBA4E7AB",
"title":"Hello World",
"body":"Well hello and welcome to my new blog...",
"date":"2009/01/15 15:52:20"
}
举个例子就可以了。注意,文档是按“_id”排序的,这就是它们在数据库中的存储方式。现在我们定义一个视图。在我们向您展示一些代码时,请不要解释:
function(doc) {
if(doc.date && doc.title) {
emit(doc.date, doc.title);
}
}
这是一个 map function ,它是用JavaScript编写的。如果您不熟悉JavaScript,但使用过C或任何其他类似C的语言,如Java、PHP或C#,这应该看起来很熟悉。这是一个简单的函数定义。
将CouchDB作为字符串提供给CouchDB,存储在 views 设计文档的字段。要创建此视图,可以使用以下命令:
curl -X PUT http://admin:password@127.0.0.1:5984/db/_design/my_ddoc
-d '{"views":{"my_filter":{"map":
"function(doc) { if(doc.date && doc.title) { emit(doc.date, doc.title); }}"}}}'
您不需要自己运行JavaScript函数。相反,当你 query your view ,CouchDB获取源代码,并在定义视图的数据库中的每个文档上为您运行它。你 query your view 检索 view result 使用以下命令:
curl -X GET http://admin:password@127.0.0.1:5984/db/_design/my_ddoc/_view/my_filter
所有映射函数都有一个单参数doc。这是数据库中的一个文档。我们的map函数检查文档是否具有 date 和A title 属性(幸运的是,我们所有的文档都有它们),然后调用内置的 emit() 函数将这两个属性作为参数。
这个 emit() 函数总是接受两个参数:第一个是 key ,第二个是 value . 这个 emit(key, value) 函数在 view result . 还有一件事 emit() 函数可以在map函数中多次调用,以在单个文档的视图结果中创建多个条目,但我们还没有这样做。
CouchDB接受传入emit()函数的任何内容,并将其放入一个列表中(参见下面的表1“查看结果”)。该列表中的每一行都包含 key 和 value . 更重要的是,列表是按键排序的(按 doc.date 在我们的案例中)。视图结果最重要的特性是它的排序依据 key . 我们会一次又一次地回到这个问题上来做一些整洁的事情。敬请期待。
表1。查看结果:
| 键 | 价值 |
|---|---|
| “2009/01/15 15 15:52:20” | “你好,世界” |
| “2009年1月30日18:04:11” | “骑自行车” |
| “2009/02/17 21:13:39” | “买了只猫” |
当您查询视图时,CouchDB获取源代码并在数据库中的每个文档上运行它。如果您有大量的文档,这需要相当长的时间,您可能会怀疑这样做是否效率低下。是的,应该是这样,但是CouchDB的设计是为了避免任何额外的开销:它只在您第一次查询视图时运行一次所有文档。如果更改了文档,映射函数只运行一次,以重新计算该文档的键和值。
视图结果存储在B树中,就像负责保存文档的结构一样。视图B树存储在它们自己的文件中,因此对于高性能CouchDB的使用,您可以将视图保存在它们自己的磁盘上。B-tree提供了按键对行的快速查找,以及对键范围内的行进行高效的流式处理。在我们的例子中,一个视图可以回答所有涉及时间的问题:“把上周的所有博客文章给我”、“上个月”或“今年”。非常简洁。
当我们查询视图时,我们会返回按日期排序的所有文档的列表。每一行还包括文章标题,这样我们就可以构建到文章的链接。表1只是视图结果的图形化表示。实际结果是JSON编码的,并且包含更多的元数据:
{
"total_rows": 3,
"offset": 0,
"rows": [
{
"key": "2009/01/15 15:52:20",
"id": "hello-world",
"value": "Hello World"
},
{
"key": "2009/01/30 18:04:11",
"id": "biking",
"value": "Biking"
},
{
"key": "2009/02/17 21:13:39",
"id": "bought-a-cat",
"value": "Bought a Cat"
}
]
}
现在,实际结果的格式不是很好,也没有包含任何多余的空白或换行符,但这对您(和我们)更好阅读和理解。结果行中的“id”成员来自何处?以前没有。那是因为我们早些时候为了避免混淆而省略了它。CouchDB自动在视图结果中包含创建条目的文档的文档ID。我们在构建博客文章页面的链接时也会用到这个。
警告
不要将整个文档作为 emit(key, value) 除非你确定你想要它。这将在视图的辅助索引中存储文档的整个附加副本。视图 emit(key, doc) 更新所需的时间更长,写入磁盘的时间也更长,而且占用的磁盘空间也大大增加。唯一的优点是它们比使用 ?include_docs=true 查询视图时的参数。
在发布整个文档之前,请考虑权衡。通常,在您的视图中只发出文档的一部分,或者只发出一个键/值对就足够了。
3.2.1.2. 高效查找¶
让我们继续讨论视图的第二个用例:“构建有效的索引,根据文档中驻留的任何值或结构来查找文档。”我们已经解释了高效索引,但是我们跳过了一些细节。现在是结束这一讨论的好时机,因为我们正在研究更复杂的映射函数。
首先,回到B树!我们解释过,当您第一次查询视图时,支持键排序视图结果的B树只构建一次,所有后续查询将只读取B树,而不会再次对所有文档执行map函数。但是,当您更改文档、添加新文档或删除文档时,会发生什么情况?简单:CouchDB足够聪明,可以在视图结果中找到由特定文档创建的行。它将它们标记为无效,以便它们不再显示在视图结果中。如果文档被删除,我们很好-结果B树反映了数据库的状态。如果更新了一个文档,新文档将通过map函数运行,并将生成的新行插入到B树的正确位置。新文档的处理方式相同。B-tree是一种非常有效的数据结构,CouchDB数据库的纯崩溃设计也被转移到视图索引中。
在效率讨论中再增加一点:通常在视图查询之间更新多个文档。上一段中解释的机制适用于自上一次在批处理操作中查询视图以来数据库中的所有更改,这使得事情变得更快,并且通常可以更好地利用资源。
3.2.1.2.1. 找一个¶
到更复杂的映射函数。我们说的是“通过驻留在文档中的任何值或结构来查找文档”,我们已经解释了如何提取一个用于对视图列表进行排序的值(我们的日期字段)。相同的机制用于快速查找。要查询以获取视图结果的URI是 /database/_design/designdocname/_view/viewname . 这将为您提供视图中所有行的列表。我们只有三个文件,所以事情很小,但是有成千上万的文件,这可能会很长。您可以向URI添加视图参数以约束结果集。假设我们知道一篇博客文章的日期。要找到一个文档,我们可以使用 /blog/_design/docs/_view/by_date?key="2009/01/30 18:04:11" 得到“骑自行车”的博客帖子。请记住,您可以在emit()函数的键参数中放置您喜欢的任何内容。不管你放在那里什么,我们现在可以用它来准确快速地查找。
注意,在多行具有相同键的情况下(也许我们设计了一个视图,其中key是文章作者的名字),键查询可以返回多行。
3.2.1.2.2. 找到很多¶
我们讨论过“获取上个月的所有帖子”。如果现在是2月份,这很简单:
/blog/_design/docs/_view/by_date?startkey="2010/01/01 00:00:00"&endkey="2010/02/00 00:00:00"
这个 startkey 和 endkey 参数指定我们可以搜索的包含范围。
为了使事情变得更好,并为将来的示例做准备,我们将更改日期字段的格式。我们将使用一个数组而不是一个字符串,其中单个成员是时间戳的一部分,其重要性逐渐降低。这听起来很花哨,但很容易。而不是::
{
"date": "2009/01/31 00:00:00"
}
我们使用:
{
"date": [2009, 1, 31, 0, 0, 0]
}
我们的map函数不必为此更改,但我们的视图结果看起来有些不同:
表2。新结果视图:
| 键 | 价值 |
|---|---|
| [2009年1月15日15日52 20日] | “你好,世界” |
| [2009年2月17日21 13 39日] | “骑自行车” |
| [2009年1月30日18 4 11日] | “买了只猫” |
我们的问题变为:
/blog/_design/docs/_view/by_date?startkey=[2010, 1, 1, 0, 0, 0]&endkey=[2010, 2, 1, 0, 0, 0]
不管你怎么说,这只是语法上的改变,而不是意义上的改变。但它向你展示了观点的力量。不仅可以用字符串和整数等标量值构造索引,还可以使用JSON结构作为视图的键。假设我们用一个标记列表标记文档并希望查看所有标记,但我们不关心尚未标记的文档。
{
...
tags: ["cool", "freak", "plankton"],
...
}
{
...
tags: [],
...
}
function(doc) {
if(doc.tags.length > 0) {
for(var idx in doc.tags) {
emit(doc.tags[idx], null);
}
}
}
这显示了一些新事物。你可以在结构上有条件 (if(doc.tags.length > 0) )而不仅仅是价值观。这也是一个map函数如何调用的示例 emit() 每个文档多次。最后,可以向value参数传递null而不是值。关键参数也是如此。我们稍后会看到这有多有用。
3.2.1.2.3. 颠倒的结果¶
要以相反的顺序检索视图结果,请使用 descending=true 查询参数。如果您正在使用 startkey 参数,您将发现CouchDB返回不同的行或根本不返回行。怎么回事?
当您看到视图查询选项是如何在幕后工作时,很容易理解的。视图存储在树结构中,以便快速查找。无论何时查询视图,CouchDB的操作方式如下:
- 从顶部开始阅读,或者在
startkey指定(如果存在)。 - 每次返回一行,直到结束或到达为止
endkey,如果存在的话。
如果您指定 descending=true ,则读取方向相反,而不是视图中行的排序顺序。此外,遵循同样的两步程序。
假设您的视图结果如下所示:
| 键 | 价值 |
|---|---|
| 0 | “福” |
| 1 | “酒吧” |
| 2 | “巴兹” |
以下是潜在的查询选项: ?startkey=1&descending=true . CouchDB会怎么做?参见上面的#1:它跳到 startkey ,这是带有键的行 1 ,并开始向后阅读,直到到达视图的末尾。因此,具体结果是:
| 键 | 价值 |
|---|---|
| 1 | “酒吧” |
| 0 | “福” |
这很可能不是你想要的。获取包含索引的行 1 和 2 以相反的顺序,您需要切换 startkey 到 endkey : endkey=1&descending=true :
| 键 | 价值 |
|---|---|
| 2 | “巴兹” |
| 1 | “酒吧” |
现在看来好多了。CouchDB开始从视图的底部开始读取,然后向后移动,直到它命中为止 endkey .
3.2.1.3. 获取帖子评论的视图¶
我们在这里使用数组键来支持 group_level 减少查询参数。CouchDB的视图存储在B-tree文件结构中。由于B树的构造方式,我们可以将中间reduce结果缓存到树的非叶节点中,因此reduce查询可以在对数时间内沿任意键范围计算。参见图1,“注释映射函数”。
在博客应用程序中,我们使用 group_level 通过使用不同的方法查询同一个视图索引,减少查询以计算每个帖子和总计的评论数。使用一些数组键,并假设每个键都有 1 :
["a","b","c"]
["a","b","e"]
["a","c","m"]
["b","a","c"]
["b","a","g"]
reduce视图:
function(keys, values, rereduce) {
return sum(values)
}
或:
_sum
它是一个内置的CouchDB reduce函数(其他是 _count 和 _stats ) _sum 这里返回开始键和结束键之间的总行数。所以 startkey=["a","b"]&endkey=["b"] (包括上述键的前三个)结果将相等 3 . 其效果是计算行数。如果您想在不依赖行值的情况下计算行数,可以打开 rereduce 参数:
function(keys, values, rereduce) {
if (rereduce) {
return sum(values);
} else {
return values.length;
}
}
注解
上面的JavaScript函数可以被内置的 _count .

图1。注释映射函数
这是示例应用程序使用的reduce视图来计数注释,同时利用映射输出注释,这比 1 一遍又一遍。花点时间来研究map和reduce函数是值得的。Fauxton可以这样做,但是它没有提供对所有查询参数的完全访问权。用您选择的语言为视图编写自己的测试代码是探索CouchDB增量MapReduce系统的细微差别和功能的一个很好的方法。
不管怎样,用一个 group_level 查询,您基本上是在运行一系列缩小范围的查询:在查询级别显示的每个组对应一个查询。让我们重新打印前面的密钥列表,分组到级别 1 :
["a"] 3
["b"] 2
在 group_level=2 :
["a","b"] 2
["a","c"] 1
["b","a"] 2
使用参数 group=true 让它表现得好像 group_level=999 在我们的例子中,我们会给出当前的例子 1 对于每个键,因为没有完全重复的键。
3.2.1.4. 减少/减少¶
我们简单地讨论了 rereduce reduce函数的参数。我们将在本节中解释它是怎么回事。到现在为止,您应该已经知道为了提高效率,视图结果存储在B树索引结构中。存在和使用 rereduce 参数与B树索引的工作方式紧密耦合。
考虑地图结果为:
"afrikaans", 1
"afrikaans", 1
"chinese", 1
"chinese", 1
"chinese", 1
"chinese", 1
"french", 1
"italian", 1
"italian", 1
"spanish", 1
"vietnamese", 1
"vietnamese", 1
例1。示例视图结果(mmm,food)
当我们想知道每个产地有多少盘菜时,我们可以重用前面所示的简单reduce函数:
function(keys, values, rereduce) {
return sum(values);
}
图2,“B树索引”显示了B树索引的简化版本。我们缩短了键串。
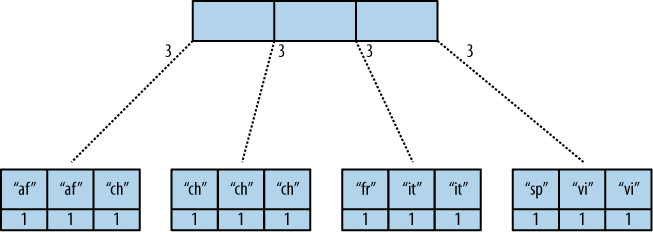
图2。B树索引
这个视图的结果就是计算机科学毕业生所谓的“预购”遍历树。我们从左边开始查看每个节点中的每个元素。每当我们看到有一个子节点要下降,我们下降并开始读取该子节点中的元素。当我们穿过整棵树,我们就完了。
您可以看到CouchDB在每个叶节点中存储键和值。在我们的情况下,它总是 1 ,但您可能有一个值,在该值中计算其他结果,然后所有行都具有不同的值。重要的是CouchDB将节点内的所有元素运行到reduce函数中(设置 rereduce 参数设置为false)并将结果存储在父节点内,以及子节点的边。在我们的例子中,每条边都有一个3,代表它所指向的节点的reduce值。
注解
实际上,节点中有1600多个元素。CouchDB对单个节点中的元素多次迭代计算所有元素的结果,而不是一次计算所有元素的结果(这对于内存消耗来说是灾难性的)。
现在让我们看看运行查询时会发生什么。我们想知道我们有多少“中文”条目。查询选项很简单: ?key="chinese" . 参见图3,“B-树索引减少结果”。
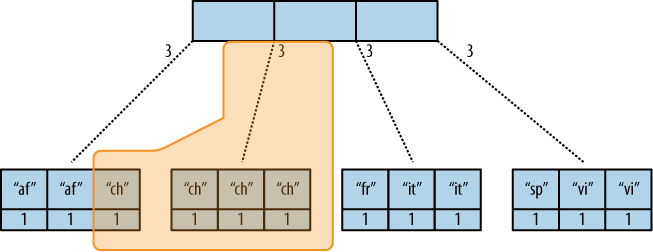
图3。B-树索引归约结果
CouchDB检测子节点中的所有值都包含“chinese”键。它的结论是,只需要与该节点关联的3个值即可计算最终结果。然后,它会找到左边的节点,并看到它是一个键在请求范围之外的节点 (key= 起始值和结束值是相同的范围)。结论是必须使用“chinese”元素的值和另一个节点的值,并使用 rereduce 参数设置为true。
reduce函数在查询时有效地计算3+1并返回所需的结果。下一个示例显示了一些伪代码,这些伪代码显示了reduce函数的最后一次调用和实际值:
function(null, [3, 1], true) {
return sum([3, 1]);
}
现在,我们说过reduce函数必须实际地减少值。如果你看到了B树,当你不减少你的值时,会发生什么就变得很明显了。考虑下面的map结果和reduce函数。这一次,我们希望获得视图中所有唯一标签的列表:
"abc", "afrikaans"
"cef", "afrikaans"
"fhi", "chinese"
"hkl", "chinese"
"ino", "chinese"
"lqr", "chinese"
"mtu", "french"
"owx", "italian"
"qza", "italian"
"tdx", "spanish"
"xfg", "vietnamese"
"zul", "vietnamese"
我们不在乎这里的钥匙,只列出我们所有的标签。我们的reduce函数删除重复项:
function(keys, values, rereduce) {
var unique_labels = {};
values.forEach(function(label) {
if(!unique_labels[label]) {
unique_labels[label] = true;
}
});
return unique_labels;
}
这转换为图4,“溢出reduce index”。
我们希望你能明白。B-tree存储的工作方式意味着,如果不在reduce函数中实际减少数据,那么CouchDB将大量数据复制到视图中,这些数据会随着视图中的行数线性增长(如果不是更快的话)。
CouchDB将能够计算最终结果,但仅限于具有几行的视图。任何更大的东西都将经历一个可笑的缓慢的视图构建时间。为了帮助解决这个问题,如果reduce函数不减少它的输入值,couchdbsinversion0.10.0将抛出一个错误。
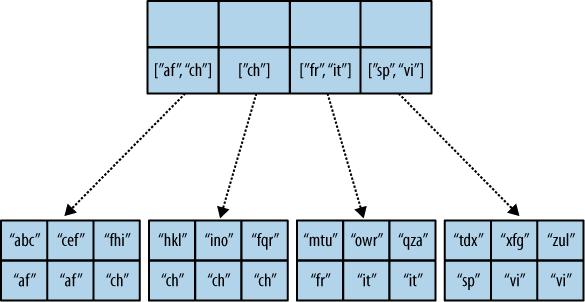
图4。溢出减少指数
3.2.1.5. 一个设计文档与多个设计文档¶
一个常见的问题是:何时应将多个视图拆分为多个设计文档,还是将它们放在一起?
您创建的每个视图对应于一个B树。单个设计文档中的所有视图都将位于磁盘上的同一组索引文件中(每个数据库碎片一个文件;在2.0+中,默认情况下,每个节点8个文件)。
将视图拆分为单独的文档最实际的考虑是更改这些视图的频率。如果视图经常更改,并且与其他视图位于同一设计文档中,则在编写设计文档时,这些视图的索引将失效,从而强制所有视图从头开始重建。很明显,你会希望在生产中避免这种情况!
但是,当在同一个设计文档中有多个具有相同映射函数的视图时,CouchDB将优化并只计算该映射函数一次。这使您有两个不同的视图 减少 功能(例如,一个 _sum 和一个 _stats )但只生成映射索引的单个副本。它还可以节省磁盘空间和将多个副本写入磁盘的时间。
在同一个设计文档中拥有多个视图的另一个好处是索引文件可以保留从docid到行的向后引用的单个索引。CouchDB需要这些“back refs”在删除文档时使视图中的行无效(否则,删除将强制进行完全重建!)
另一个考虑是每个独立的设计文档都会产生另一个(集) couchjs 生成视图的进程,每个碎片一个。根据服务器上核心的数量,这可能是高效的(使用您拥有的所有空闲内核)或低效(服务器上的CPU过载)。具体情况将取决于您的部署架构。
那么,您应该使用一个还是多个设计文档?选择权在你。
3.2.1.6. 经验教训¶
- 如果不在map函数中使用key字段,那么很可能是错误的。
- 如果您试图使reduce函数中的值列表是唯一的,那么您可能是做错了。
- 如果不将值缩减为单个标量值或小的固定大小的对象或数组,则可能是您做错了。
3.2.1.7. 总结¶
Map函数是无副作用的函数,它以文档为参数 emit 键/值对。CouchDB通过构造一个已排序的B树索引来存储发出的行,因此按键进行的行查找以及跨一系列行的流式操作可以在较小的内存和处理空间内完成,而写操作则可以避免查找。生成视图需要 O(N) 在哪里 N 视图中的总行数。然而,查询视图非常快,因为B树即使包含很多很多键,也仍然很浅。
Reduce函数对地图视图函数发出的已排序行进行操作。CouchDB的reduce功能利用了B树索引的一个基本属性:对于每个叶节点(一个已排序的行),都有一个内部节点链回到根节点。B-树中的每个叶节点都承载一些行(根据行大小,以十为顺序),每个内部节点可以链接到几个叶节点或其他内部节点。
reduce函数在树中的每个节点上运行,以计算最终的reduce值。最终结果是一个reduce函数,它可以在map函数发生更改时递增更新,同时重新计算最小节点数的缩减值。树中每个节点(内部和叶)计算一次初始缩减。
在叶节点(包含实际的映射行)上运行时,reduce函数的第三个参数, rereduce ,为false。本例中的参数是map函数输出的键和值。该函数有一个返回的reduction值,该值存储在一组叶子节点共同拥有的内部节点上,并在以后的reduce计算中用作缓存。
当reduce函数在内部节点上运行时 rereduce 旗是 true . 这使函数能够考虑到它将接收自己的先前输出这一事实。什么时候? rereduce 为true,则传递给函数的值是从以前的计算中缓存的中间还原值。当树的深度超过两层时 rereduce 阶段是重复的,消耗前一级的输出块,直到在根节点计算出最终的reduce值。
新CouchDB用户犯的一个常见错误是试图用reduce函数构造复杂的聚合值。完全减少应该得到一个标量值,比如5,而不是一个JSON哈希,其中包含一组唯一键和每个键的计数。这种方法的问题是最终会得到非常大的最终值。唯一键的数量几乎可以与全部键的数量一样大,即使对于一个大的集合也是如此。将一些标量计算合并到一个reduce函数中是很好的;例如,在一个函数中查找一组数字的总和、平均值和标准差。
如果您对推动CouchDB的incremental reduce功能感兴趣,可以看看 Google’s paper on Sawzall ,它给出了一些在具有类似约束的系统中可以实现的更奇异的约简的示例。