先进的¶
Cherrypy支持这些部分将描述的更高级的功能。
目录
设置页面处理程序的别名¶
由 cherrypy.expose() decorator支持别名。
让我们使用提供的模板 tutorial 03 :
import random
import string
import cherrypy
class StringGenerator(object):
@cherrypy.expose(['generer', 'generar'])
def generate(self, length=8):
return ''.join(random.sample(string.hexdigits, int(length)))
if __name__ == '__main__':
cherrypy.quickstart(StringGenerator())
在本例中,我们为页面处理程序创建本地化别名。这意味着可以通过以下方式访问页面处理程序:
/生成
/Generer(法语)
/Generar(西班牙语)
显然,您的别名可能是任何适合您需要的。
注解
别名可以是单个字符串或它们的列表。
休息式调度¶
术语 RESTful URL 有时用于讨论友好的URL,这些URL可以很好地映射到应用程序公开的实体。
重要
我们将不讨论什么是RESTful,什么不是RESTful,但我们将展示两种机制来在您的Cherrypy应用程序中实现通常的想法。
假设您希望创建一个应用程序来公开音乐乐队及其唱片。您的应用程序可能具有以下URL:
http://hostname/<artist>/
http://hostname/<artist>/albums/<album_title>/
很明显,您不会创建一个以世界上每个可能的波段命名的页面处理程序。这意味着您将需要一个页面处理程序作为所有页面处理程序的代理。
默认调度器无法单独处理该方案,因为它希望在源代码中显式声明页处理程序。幸运的是,Cherrypy提供了支持这些用例的方法。
参见
本节引自 stackoverflow response .
特殊的调度方法¶
_cp_dispatch 是您在任何 controller 在Cherrypy开始处理之前按摩剩余的部分。这为您提供了删除、添加或以其他方式处理您希望的任何段的能力,甚至可以完全更改其余部分。
import cherrypy
class Band(object):
def __init__(self):
self.albums = Album()
def _cp_dispatch(self, vpath):
if len(vpath) == 1:
cherrypy.request.params['name'] = vpath.pop()
return self
if len(vpath) == 3:
cherrypy.request.params['artist'] = vpath.pop(0) # /band name/
vpath.pop(0) # /albums/
cherrypy.request.params['title'] = vpath.pop(0) # /album title/
return self.albums
return vpath
@cherrypy.expose
def index(self, name):
return 'About %s...' % name
class Album(object):
@cherrypy.expose
def index(self, artist, title):
return 'About %s by %s...' % (title, artist)
if __name__ == '__main__':
cherrypy.quickstart(Band())
注意控制器如何定义 _cp_dispatch ,它只需要一个参数,URL路径信息被分割成若干段。
该方法可以检查和操作段列表,可以在任何位置删除任何段或添加新段。然后将新的段列表发送给调度器,调度器将使用它来定位适当的资源。
在上面的示例中,您应该能够转到以下URL:
这个 /nirvana/ 段与带和 /nevermind/ 片段与专辑相关。
为了实现这一点, _cp_dispatch 方法的工作原理是,默认调度器根据页面处理程序签名及其在处理程序树中的位置匹配URL。
在本例中,我们获取URL中的动态段(带和记录名称),将它们注入请求参数中,然后将它们从段列表中删除,就好像它们从未出现过一样。
换言之, _cp_dispatch 使其看起来像在处理以下URL:
Popargs装饰师¶
cherrypy.popargs() 更直截了当的是,它给了Cherrypy无法解释的任何部分一个名字。这使得片段与页面处理程序签名的匹配更容易,并帮助Cherrypy了解URL的结构。
import cherrypy
@cherrypy.popargs('band_name')
class Band(object):
def __init__(self):
self.albums = Album()
@cherrypy.expose
def index(self, band_name):
return 'About %s...' % band_name
@cherrypy.popargs('album_title')
class Album(object):
@cherrypy.expose
def index(self, band_name, album_title):
return 'About %s by %s...' % (album_title, band_name)
if __name__ == '__main__':
cherrypy.quickstart(Band())
这与 _cp_dispatch 但是,如上所述,它更为明确和本地化。上面写着:
取第一段并将其存储到名为
band_name再次获取第一个段(因为我们删除了前一个段),并将其存储到名为
album_title
注意,修饰符接受不止一个绑定。例如:
@cherrypy.popargs('album_title')
class Album(object):
def __init__(self):
self.tracks = Track()
@cherrypy.popargs('track_num', 'track_title')
class Track(object):
@cherrypy.expose
def index(self, band_name, album_title, track_num, track_title):
...
这将处理以下URL:
最后请注意,如何将整个段堆栈传递给每个页面处理程序,以便获得完整的上下文。
错误处理¶
CherryPy的 HTTPError 类支持在出现错误时立即发出响应。
class Root:
@cherrypy.expose
def thing(self, path):
if not authorized():
raise cherrypy.HTTPError(401, 'Unauthorized')
try:
file = open(path)
except FileNotFoundError:
raise cherrypy.HTTPError(404)
HTTPError.handle 是一个上下文管理器,它支持将应用程序中引发的异常转换为适当的HTTP响应,如第二个示例所示。
class Root:
@cherrypy.expose
def thing(self, path):
with cherrypy.HTTPError.handle(FileNotFoundError, 404):
file = open(path)
流式处理响应主体¶
Cherrypy处理HTTP请求,打包和解包低级细节,然后将控制权传递给应用程序 page handler 从而产生响应体。Cherrypy允许您返回各种类型的正文内容:字符串、字符串列表和文件。Cherrypy还允许你 产量 内容,而不是 返回 内容。当您使用“yield”时,您还可以选择流式传输输出。
一般来说,不流输出更安全、更容易。 因此,流输出在默认情况下是关闭的。流输出和使用会话需要很好地理解 how session locks work .
“正常”切瑞皮反应过程¶
当您从页面处理程序提供内容时,Cherrypy会像这样管理HTTP服务器和代码之间的对话:
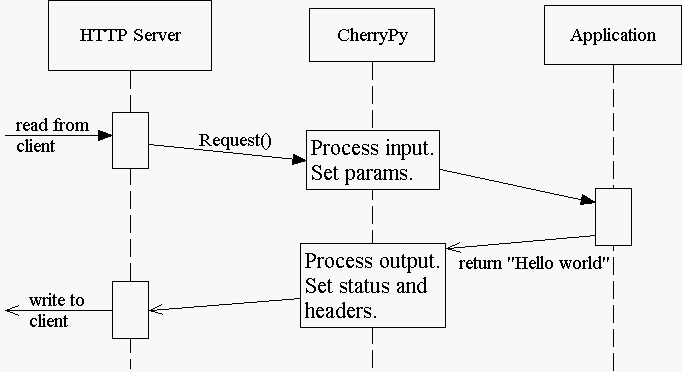
请注意,HTTP服务器首先收集所有输出,然后立即将所有内容写入客户机:状态、头和正文。对于静态或简单的页面来说,这很好,因为整个响应可以在任何时候更改,无论是在应用程序代码中,还是在Cherrypy框架中。
“流输出”如何与Cherrypy一起工作¶
当您将配置条目“response.stream”设置为true(并使用“yield”)时,cherrypy将管理HTTP服务器和代码之间的对话,如下所示:
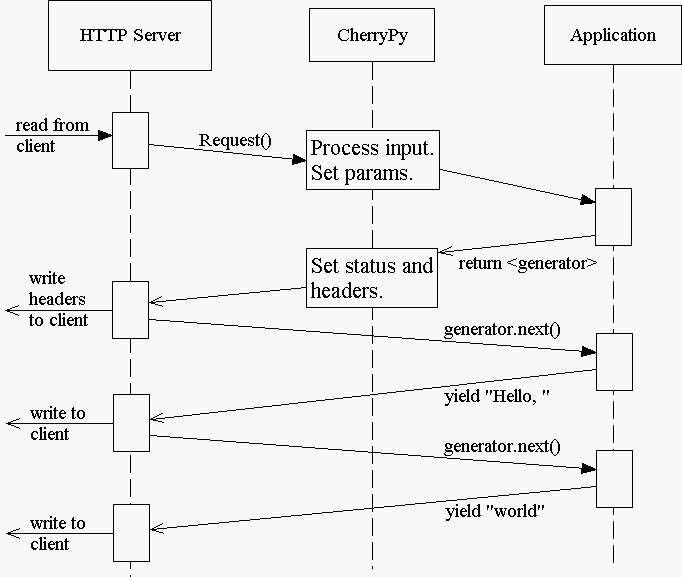
流式处理时,应用程序不会立即将原始正文内容传递回Cherrypy或HTTP服务器。相反,它传递回一个发电机。在这一点上,Cherrypy最终确定了状态和标题, 之前 发电机已被消耗,或已产生任何输出。这对于允许HTTP服务器在消息头和消息体可用时发送消息头和消息体片段是必要的。
一旦Cherrypy设置了状态和头,它就会将它们发送到HTTP服务器,然后由HTTP服务器将它们写出给客户机。从那时起,cherrypy框架基本上已经过时了,HTTP服务器基本上直接从应用程序代码(页面处理程序方法)请求内容。
因此,当进行流式处理时,如果页面处理程序中发生错误,Cherrypy将无法捕获它——HTTP服务器将捕获它。因为头(可能还有一些主体)已经写入客户机,所以服务器 不能 了解处理错误的安全方法,因此只需关闭连接(当前的内置服务器实际上会在正文中写出一条简短的错误消息,但这可能会发生更改,并且不能保证您可能与CherryPy一起使用的所有HTTP服务器的行为)。
此外,如果页处理程序方法是流生成器,则不能手动修改页处理程序中的状态或头,因为在头写入客户端之前,不会对该方法进行迭代。 这包括引发异常,如httperror、notfound、internalredirect和httpredirect。 要在修改标题时使用流生成器,您必须返回一个独立于(或嵌入)页面处理程序的生成器。例如:
class Root:
@cherrypy.expose
def thing(self):
cherrypy.response.headers['Content-Type'] = 'text/plain'
if not authorized():
raise cherrypy.NotFound()
def content():
yield "Hello, "
yield "world"
return content()
thing._cp_config = {'response.stream': True}
流生成器很性感,但它们会破坏HTTP。Cherrypy允许您为特定情况流式输出:需要花费数分钟才能生成的页面,或者需要立即将部分内容输出到客户机的页面。由于上述问题, 通常最好扁平化(缓冲)内容,而不是流内容 .否则,只有当流媒体的好处大于风险时才能这样做。
响应时间¶
Cherrypy的回答包括一个属性:
response.time:time.time()反应开始时
处理信号¶
这个 engine plugin 自动实例化为 cherrypy.engine.signal_handler .然而,它只是 已订阅 自动由 cherrypy.quickstart() .因此,如果您想要信号处理,并且正在呼叫:
tree.mount()
engine.start()
engine.block()
在启动发动机之前,请务必自行添加:
engine.signals.subscribe()
Windows控制台事件¶
Microsoft Windows使用控制台事件来传递某些信号,如ctrl-c。在Windows平台上部署cherrypy需要 Python for Windows Extensions ,它是自动安装的,与环境标记有额外的依赖关系。安装后,Cherrypy将自动处理ctrl-c和其他控制台事件(ctrl-c-u事件、ctrl-logoff-u事件、ctrl-break-u事件、ctrl-shutdown-u事件和ctrl-close-u事件),关闭总线以准备退出进程。
保护服务器安全¶
注解
本节并不是保护Web应用程序或生态系统的完整指南。请查看提供的各种指南 OWASP .
有几种设置可以使Cherrypy页面更安全。其中包括:
传输数据:
使用安全cookie
呈现页面:
设置httponly cookies
设置xframe选项
启用XSS保护
设置内容安全策略
实现这一点的一个简单方法是使用工具设置头文件并用它包装整个Cherrypy应用程序:
import cherrypy
# set the priority according to your needs if you are hooking something
# else on the 'before_finalize' hook point.
@cherrypy.tools.register('before_finalize', priority=60)
def secureheaders():
headers = cherrypy.response.headers
headers['X-Frame-Options'] = 'DENY'
headers['X-XSS-Protection'] = '1; mode=block'
headers['Content-Security-Policy'] = "default-src 'self';"
注解
阅读更多有关 those headers .
然后,在 configuration file (或您要启用该工具的任何其他位置):
[/]
tools.secureheaders.on = True
如果你使用 sessions 您还可以启用这些设置:
[/]
tools.sessions.on = True
# increase security on sessions
tools.sessions.secure = True
tools.sessions.httponly = True
如果使用SSL,还可以启用严格的传输安全性:
# add this to secureheaders():
# only add Strict-Transport headers if we're actually using SSL; see the ietf spec
# "An HSTS Host MUST NOT include the STS header field in HTTP responses
# conveyed over non-secure transport"
# http://tools.ietf.org/html/draft-ietf-websec-strict-transport-sec-14#section-7.2
if (cherrypy.server.ssl_certificate != None and cherrypy.server.ssl_private_key != None):
headers['Strict-Transport-Security'] = 'max-age=31536000' # one year
接下来,您可能应该使用 SSL .
多个HTTP服务器支持¶
每当您启动引擎时,Cherrypy都会启动自己的HTTP服务器。在某些情况下,您可能希望在多个端口上承载应用程序。这很容易实现:
from cherrypy._cpserver import Server
server = Server()
server.socket_port = 8090
server.subscribe()
您可以创建尽可能多的 server 服务器实例,根据需要,一次 subscribed 他们将遵循奇瑞比发动机的生命周期。
WSGi支持¶
Cherrypy支持在中定义的wsgi接口 PEP 333 以及在 PEP 3333 .其含义如下:
您可以用Cherrypy服务器托管外部WSGi应用程序
Cherrypy应用程序可以由另一个WSGi服务器托管。
使您的Cherrypy应用程序成为WSGi应用程序¶
可以从您的应用程序中获取wsgi应用程序,如下所示:
import cherrypy
wsgiapp = cherrypy.Application(StringGenerator(), '/', config=myconf)
只需使用 wsgiapp 任何WSGi感知服务器中的实例。
在Cherrypy中宿主国外的WSGi应用程序¶
假设您有一个支持wsgi的应用程序,您可以使用 cherrypy.tree.graft 设施。
def raw_wsgi_app(environ, start_response):
status = '200 OK'
response_headers = [('Content-type','text/plain')]
start_response(status, response_headers)
return ['Hello world!']
cherrypy.tree.graft(raw_wsgi_app, '/')
重要
不能将工具与外部WSGi应用程序一起使用。但是,您仍然可以从 CherryPy bus .
不需要wsgi接口?¶
默认的cherrypy HTTP服务器支持在中定义的wsgi接口。 PEP 333 和 PEP 3333 .但是,如果您的应用程序是纯Cherrypy应用程序,那么您可以切换到一个完全通过wsgi层的HTTP服务器。它将提供轻微的性能提升。
import cherrypy
class Root(object):
@cherrypy.expose
def index(self):
return "Hello World!"
if __name__ == '__main__':
from cherrypy._cpnative_server import CPHTTPServer
cherrypy.server.httpserver = CPHTTPServer(cherrypy.server)
cherrypy.quickstart(Root(), '/')
重要
使用本机服务器,您将无法移植wsgi应用程序,如前一节所示。这样做将导致运行时出现服务器错误。
WebSocket支持¶
WebSocket 是HTML5工作组为响应双向通信需求而开发的最新应用程序协议。已经提出了各种各样的黑客攻击,如Comet、轮询等。
WebSocket是一个从HTTP升级请求开始其生命周期的套接字。执行升级后,底层套接字将保持打开状态,但不再用于HTTP上下文。相反,两个连接的端点都可以使用套接字将数据推送到另一端。
Cherrypy本身不支持WebSocket,但该功能由名为 ws4py .
数据库支持¶
Cherrypy不捆绑任何数据库访问,但其体系结构使集成通用数据库接口(如中指定的db-api)变得容易。 PEP 249 .或者,也可以使用 ORM 如 SQLAlchemy 或 SQLObject .
你可以在 cherrypy-recipes 这解释了如何使用 plugins 和 tools .
HTML模板支持¶
测试应用程序¶
Web应用程序和任何其他类型的代码一样,必须进行测试。Cherrypy提供了 helper class 以便于编写功能测试。
下面是一个基本Echo应用程序的简单示例:
import cherrypy
from cherrypy.test import helper
class SimpleCPTest(helper.CPWebCase):
def setup_server():
class Root(object):
@cherrypy.expose
def echo(self, message):
return message
cherrypy.tree.mount(Root())
setup_server = staticmethod(setup_server)
def test_message_should_be_returned_as_is(self):
self.getPage("/echo?message=Hello%20world")
self.assertStatus('200 OK')
self.assertHeader('Content-Type', 'text/html;charset=utf-8')
self.assertBody('Hello world')
def test_non_utf8_message_will_fail(self):
"""
CherryPy defaults to decode the query-string
using UTF-8, trying to send a query-string with
a different encoding will raise a 404 since
it considers it's a different URL.
"""
self.getPage("/echo?message=A+bient%F4t",
headers=[
('Accept-Charset', 'ISO-8859-1,utf-8'),
('Content-Type', 'text/html;charset=ISO-8859-1')
]
)
self.assertStatus('404 Not Found')
如您所见,测试继承自该助手类。您应该设置您的应用程序并按常规安装它。然后,定义各种测试并调用助手 getPage() 执行请求的方法。只需使用各种专门的assert*方法来验证您的工作流和数据。
然后可以使用 py.test 如下:
$ py.test -s test_echo_app.py
这个 -s 是必需的,因为CherryPy类也包装stdin和stdout。如果没有该标志,测试可能会挂起等待输入的失败断言。
避免这个问题的另一个选择(例如,如果您正在IDE中运行测试)是禁用默认启用的交互模式。可以禁用设置 WEBTEST_INTERACTIVE 环境变量到 False 或 0 .
如果您不想更改环境变量来简单地运行一组测试,您也可以将 helper class ,集合 helper.CPWebCase.interactive = False 然后从自定义类派生所有测试类:
import cherrypy
from cherrypy.test import helper
class TestsBase(helper.CPWebCase):
helper.CPWebCase.interactive = False
注解
尽管它们是使用典型的模式编写的, unittest 模块支持,它们不是裸单元测试。实际上,一个完整的cherrypy堆栈是为您启动并运行您的应用程序的。如果您真的想对Cherrypy应用程序进行单元测试,也就是说不必启动服务器,您可能想看看这个 recipe .
注解
这个 helper class 来源于 unittest.TestCase 班级。因为这个原因,从 pytest ,在标准方面有一些限制 pytest 测试,尤其是在测试类中对测试进行分组时。更多详情请访问 this page .


