15.1. Lesson: 数据库概论
在使用PostgreSQL之前,让我们通过介绍一般的数据库理论来确定我们的基础。您不需要输入任何示例代码;它仅用于演示目的。
The goal for this lesson: 了解基本的数据库概念。
15.1.1. 什么是数据库?
数据库由用于一种或多种用途的数据的有序集合组成,通常以数字形式存在。 - Wikipedia
数据库管理系统(DBMS)由操作数据库的软件组成,提供存储、访问、安全、备份和其他设施。 - Wikipedia
15.1.2. 表格
在关系数据库和平面文件数据库中,表是使用垂直列(由其名称标识)和水平行的模型组织的一组数据元素(值)。表具有指定数量的列,但可以有任意数量的行。每行由已被标识为候选关键字的特定列子集中出现的值来标识。 - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
在SQL数据库中,表也称为 relation.
15.1.3. 列/字段
列是一组特定简单类型的数据值,表的每行对应一个数据值。列提供了组成行所依据的结构。术语field经常与Column互换使用,尽管许多人认为使用field(或field值)来特指存在于一行和一列交叉处的单个项目更为正确。 - Wikipedia
A栏:
| name |
+-------+
| Tim |
| Horst |
A字段:
| Horst |
15.1.4. 记录
记录是存储在表行中的信息。对于表中的每一列,每条记录都有一个字段。
2 | Horst | 88 <-- one record
15.1.5. 数据类型
数据类型限制可以存储在列中的信息类型。 - Tim and Horst
数据类型有很多种。让我们来关注一下最常见的:
String-存储自由格式的文本数据Integer-存储整数Real-存储十进制数字Date-储存霍斯特的生日,这样就没有人会忘记了Boolean-存储简单的真/假值
您可以告诉数据库也允许您在一个字段中不存储任何内容。如果字段中没有任何内容,则将该字段内容称为 'null' value :
insert into person (age) values (40);
select * from person;
结果:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
您可以使用更多的数据类型- check the PostgreSQL manual!
15.1.6. 对地址数据库进行建模
让我们使用一个简单的案例研究来了解数据库是如何构建的。我们想创建一个地址数据库。
Try Yourself 
写下组成简单地址的属性,以及我们想要存储在数据库中的属性。
回答
对于我们的理论地址表,我们可能需要存储以下属性:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
在创建表示Address对象的表时,我们将创建列来表示这些属性中的每一个,并使用与SQL兼容且可能是缩写的名称来命名它们:
house_number
street_name
suburb
city
postcode
country
地址结构
描述地址的属性是列。存储在每列中的信息类型就是其数据类型。在下一节中,我们将分析我们的概念地址表,看看如何改进它!
15.1.7. 数据库理论
创建数据库的过程包括创建真实世界的模型;获取真实世界的概念并在数据库中将其表示为实体。
15.1.8. 正常化
数据库的主要思想之一是避免数据复制/冗余。从数据库中删除冗余的过程称为正常化。
标准化是一种系统的方法,用于确保数据库结构适合于通用查询,并且没有某些可能导致数据完整性损失的不良特征--插入、更新和删除异常。 - Wikipedia
有不同类型的正常化‘形式’。
让我们来看一个简单的例子:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
想象一下,你有很多朋友都有相同的街道名称或城市。每次复制此数据都会消耗空间。更糟糕的是,如果城市名称更改,您必须做大量工作来更新您的数据库。
15.1.9. Try Yourself
重新设计理论 people 表,以减少重复并使数据结构正常化。
您可以阅读有关数据库规范化的更多信息 here
回答
最大的问题是 people 表中只有一个地址字段,其中包含一个人的整个地址。关于我们的理论思考 address 表中,我们知道地址由许多不同的属性组成。通过将所有这些属性存储在一个字段中,我们使更新和查询数据变得更加困难。因此,我们需要将地址字段拆分为各种属性。这将为我们提供一个具有以下结构的表:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
在下一节中,您将了解外键关系,这些外键关系可以在本例中用来进一步改进我们的数据库结构。
15.1.10. 索引
数据库索引是一种数据结构,可提高对数据库表的数据检索操作的速度。 - Wikipedia
想象一下,你正在阅读一本教科书,正在寻找一个概念的解释--而教科书上没有索引!你必须从一个封面开始阅读,然后通读整本书,直到找到你需要的信息。书后的索引可帮助您快速跳转到包含相关信息的页面:
create index person_name_idx on people (name);
现在,对姓名的搜索将更快:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. 数列
序列是唯一的数字生成器。它通常用于为表中的列创建唯一的标识符。
在本例中,id是一个序列--每次向表中添加记录时,该数字都会递增:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. 实体关系图绘制
在标准化的数据库中,您通常有许多关系(表)。实体关系图(ER图)用于设计关系之间的逻辑依赖关系。考虑到我们的非正常化 people 本课前面的表格:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
只需做一点工作,我们就可以将它分成两张桌子,不需要重复居住在同一条街道上的个人的街道名称:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
以及:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
然后,我们可以使用‘key’链接这两个表 streets.id 和 people.streets_id 。
如果我们为这两个表绘制ER图,它将如下所示:

ER图帮助我们表达“一对多”的关系。在这种情况下,箭头符号表明一条街道可以有许多人居住在上面。
Try Yourself 
我们的 people 模型仍然有一些正常化的问题--试着看看你是否可以进一步正常化它,并通过ER图来展示你的想法。
回答
我们的 people 表当前如下所示::
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
这个 street_id 列表示People对象和相关Street对象之间的“一对多”关系,该关系位于 streets 桌子。
进一步规格化表的一种方法是将名称字段拆分为 first_name 和 last_name **
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
我们还可以为城镇或城市名称和国家/地区创建单独的表,将它们链接到我们的 people 通过一对多关系的表格::
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
表示这一点的ER图如下所示:
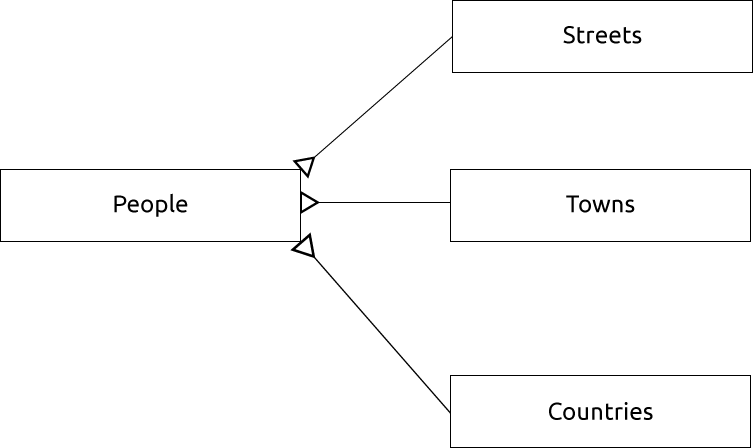
15.1.13. 约束、主键和外键
数据库约束用于确保关系中的数据与建模者关于数据应该如何存储的视图相匹配。例如,对您的邮政编码的限制可以确保数字落在 1000 和 9999 。
主键是使记录唯一的一个或多个字段值。通常,主键称为id,是一个序列。
外键用于引用另一个表上的唯一记录(使用另一个表的主键)。
在ER图中,表之间的链接通常基于外键链接到主键。
如果我们查看People示例,表定义显示Street列是引用Streets表上的主键的外键:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. 交易记录
在数据库中添加、更改或删除数据时,如果出现错误,保持数据库处于良好状态始终是很重要的。大多数数据库都提供一种称为事务支持的功能。事务允许您创建一个回滚位置,如果您对数据库的修改没有按计划运行,则可以返回到该位置。
以您有会计系统的场景为例。您需要从一个帐户转账并将其添加到另一个帐户。步骤的顺序如下所示:
从Joe上取下R20
将R20添加到Anne
如果在此过程中出现问题(如断电),则事务将回滚。
15.1.15. In Conclusion
数据库允许您使用简单的代码结构以结构化的方式管理数据。
15.1.16. What's Next?
现在我们已经了解了数据库在理论上是如何工作的,让我们创建一个新的数据库来实现我们所讨论的理论。