

遍历¶
本章解释了金字塔中遍历如何工作的技术细节。
有关快速示例,请参见 你好,穿越世界 .
更多关于 why 您可以使用遍历,请参见 关于遍历的很多麻烦 .
A traversal 使用URL(通用资源定位器)查找 resource 位于A resource tree 这是一组嵌套的类似字典的对象。遍历是通过使用URL的路径部分的每个段在 resource tree . 您可能认为这是在文件系统中查找文件和目录。Traversal沿着路径一直走,直到找到一个发布的资源,类似于文件系统“目录”或“文件”。作为遍历结果找到的资源将成为 context 的 request . 然后, view lookup 子系统用于通过生成一个 response .
备注
使用 Traversal 将URL映射到代码是可选的。如果您正在创建第一个金字塔应用程序,使用它可能更有意义 URL dispatch 将URL映射到代码而不是遍历,因为新的金字塔开发人员倾向于发现URL调度稍微容易理解。如果您使用URL调度,则不需要阅读本章。
遍历详细信息¶
Traversal 依赖于中的信息 request 对象。每个 request 对象中包含URL路径信息 PATH_INFO 部分 WSGI 环境。这个 PATH_INFO 字符串是请求的URL的一部分,位于主机名和端口号之后,但位于任何查询字符串元素或片段元素之前。例如 PATH_INFO URL的一部分 http://example.com:8080/a/b/c?foo=1 是 /a/b/c .
遍历处理 PATH_INFO 作为路径段序列的URL段。例如, PATH_INFO 一串 /a/b/c 转换为序列 ['a', 'b', 'c'] .
然后使用此路径序列通过 resource tree ,为每个路径段查找资源。每次查找都使用 __getitem__ 树中资源的方法。
例如,如果路径信息序列是 ['a', 'b', 'c'] :
Traversal 从获取 root 通过调用 root factory . 这个 root factory 可以配置为返回任何合适的对象作为应用程序的遍历根。
下一个,第一个元素 (
'a')从路径段序列中弹出,用作查找根目录中相应资源的键。这将调用根资源的__getitem__使用该值的方法 ('a')作为一个论点。如果根资源“包含”具有键的资源
'a'它的__getitem__方法将返回它。这个 context 暂时成为“A”资源。下一段 (
'b')从路径序列中弹出,“A”资源的__getitem__用该值调用 ('b')作为一个论点,我们假定它会成功。“A”资源
__getitem__返回另一个资源,我们称之为“b”。这个 context 暂时成为“B”资源。
遍历将继续进行,直到路径段序列用尽或路径元素无法解析为资源。在这两种情况下, context 资源是遍历成功解析的最后一个对象。如果在遍历期间发现任何资源缺少 __getitem__ 方法,或者 __getitem__ 方法提出 KeyError ,遍历立即结束,该资源成为 context .
A的结果 traversal 还包括 view name . 如果在耗尽路径段序列之前遍历结束,则 view name 是 next 剩余的路径段元素。如果 traversal 花费所有路径段,然后 view name 是空字符串 ('' )
上下文资源和 view name 在同一个请求中稍后由 view lookup 要查找的子系统 view callable . 怎么用? Pyramid 执行视图查找在 查看配置 章。
资源树¶
资源树是一组嵌套的类似字典的资源对象,以 root 资源。为了使用 traversal 要将URL解析为代码,应用程序必须提供 resource tree 到 Pyramid .
为了为应用程序提供根资源, Pyramid Router 配置的回调称为 root factory . 根工厂由应用程序在启动时作为 root_factory 论据 Configurator .
根工厂是一个接受 request 对象,并返回 resource tree . 函数或类通常用作应用程序的根工厂。下面是一个简单的根工厂类示例:
1class Root(dict):
2 def __init__(self, request):
3 pass
下面是一个在启动配置中使用这个根工厂的示例,将它传递给 Configurator 已命名 config :
1config = Configurator(root_factory=Root)
这个 root_factory 论据 Configurator 构造函数注册此根工厂,以便在请求进入应用程序时调用它来生成根资源。以这种方式注册的根工厂也称为全局根工厂。根工厂也可以传递给 Configurator 作为一个 dotted Python name 它可以引用在不同模块中定义的根工厂。
如果没有 root factory 传递给 Pyramid Configurator 或者如果 root_factory 指定的值为 None ,A default root factory 使用。默认根工厂总是返回没有子资源的资源;它实际上是空的。
通常,基于遍历的应用程序的根工厂将比上述更复杂 Root 班级。特别是,它可能与数据库连接或其他持久性机制相关联。以上 Root 类类似于金字塔中存在的默认根工厂。默认的根工厂非常简单,也不是很有用。
备注
如果资源树中包含的项是“持久的”(它们的状态比单个进程的执行时间长),那么它们就类似于 domain model 许多其他框架使用的对象。
资源树包括 容器 资源和 leaf 资源。两者之间只有一个区别 容器 资源与A leaf 资源: 容器 资源拥有 __getitem__ 方法(使其“像字典一样”)同时 leaf 资源不是。这个 __getitem__ 方法被选作这两种资源类型之间的标志性差异,因为此方法的存在就是Python本身通常如何确定对象是否“容器化”(字典对象是“容器化”)。
假定每个容器资源都愿意返回子资源或引发 KeyError 基于传递给它的名称 __getitem__ .
叶级实例不能有 __getitem__ . 如果你想离开的情况已经发生了 __getitem__ 通过一些历史上的不平等,您应该将这些资源类型分为子类,并导致它们 __getitem__ 简单地提高 KeyError . 或者干脆把它们扔掉,再想出另一个策略。
通常,遍历根是 容器 资源,因此它包含其他资源。但是,它没有 need 成为一个容器。资源树可以是浅的,也可以是深的。
通常,资源树从其根资源开始,使用由 PATH_INFO 当前请求的。如果存在路径段,则根资源的 __getitem__ 用下一个路径段调用,它将返回另一个资源。结果资源的 __getitem__ 用下一个路径段调用,它将返回另一个资源。这种情况发生了 无穷大 直到所有路径段耗尽。
遍历算法¶
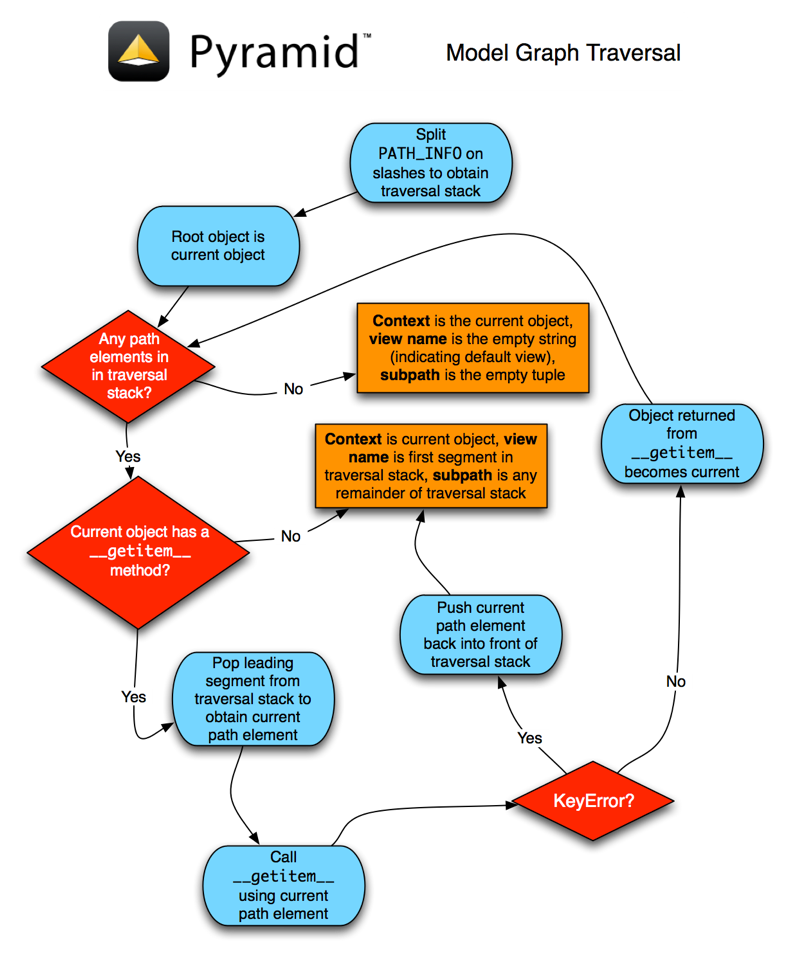
本节将尝试解释 Pyramid 遍历算法。我们将提供算法的描述、算法工作原理图以及一些示例遍历场景,这些场景可能有助于您了解算法如何针对特定的资源树进行操作。
我们也会谈谈 view lookup . 这个 查看配置 第章讨论 view lookup 详细地说,它是有关视图信息的规范源。技术上, view lookup 是一个 Pyramid 完全与遍历分离的子系统。但是,我们将在接下来的几节中的示例中描述视图查找的基本行为,让您了解遍历和视图查找是如何协作的,因为它们几乎总是一起使用的。
遍历算法的描述¶
当用户从支持遍历的应用程序请求页面时,系统使用此算法查找 context 资源与A view name .
页面请求显示给 Pyramid router 就标准而言 WSGI 请求,由wsgi环境和wsgi表示
start_response可赎回的。路由器创建一个 request 基于wsgi环境的对象。
这个 root factory 是用 request . 它返回一个 root 资源。
路由器使用wsgi环境的
PATH_INFO确定要遍历的路径段的信息。前面的斜线被去掉了PATH_INFO,剩余的路径段在斜线字符上拆分,形成一个遍历序列。默认情况下,遍历算法首先尝试对URL进行无引号运算,然后对从中派生的每个路径段进行Unicode解码。
PATH_INFO从它的自然字符串表示。使用python标准库执行URL非引用urllib.unquote功能。尝试使用UTF-8编码从URL解码字符串转换为Unicode。如果在PATH_INFO无法使用UTF-8解码,aTypeError提高了。在将段传递到__getitem__遍历期间的任何资源。因此,请求
PATH_INFO变量/a/b/c映射到遍历序列['a', 'b', 'c'].Traversal 从根工厂返回的根资源开始。对于遍历序列
['a', 'b', 'c'],根资源的__getitem__用名称调用'a'. 遍历在序列中继续进行。在我们的示例中,如果根资源__getitem__用名字呼叫a返回一个资源(也就是说,资源“a”),该资源是__getitem__用名称调用'b'. 如果资源“A”在被请求时返回资源“B”'b'资源B__getitem__然后询问姓名'c',并可能返回资源“c”。当(a)整个路径耗尽,(b)任何资源引发
KeyError从其__getitem__,(c)当任何非最终路径元素遍历没有__getitem__方法(导致AttributeError)或(d)在任何路径元素前面加上一组字符@@(表示后面的字符@@令牌应被视为 view name )当遍历由于上一步中的任何原因而结束时,在遍历期间找到的最后一个资源将被视为 context . 如果遍历结束时路径已用尽,则 view name 被视为空字符串 (
'')但是,如果路径是 not 遍历终止前耗尽,剩余的第一个路径段将被视为视图名。后面的任何后续路径元素 view name 被发现被认为是 subpath . 子路径始终是来自
PATH_INFO这是遍历完成后的“剩余”。
一旦 context 资源 view name 以及相关的属性,例如 subpath 位于,工作 traversal 完成了。它将获取的信息传递给调用方, Pyramid Router ,随后调用 view lookup 包含上下文和视图名称信息。
遍历算法公开了两种特殊情况:
你通常会以 view name 这是特定遍历的结果为空字符串。这表示视图查找机器应查找 default view . 默认视图是一个没有名称注册的视图,或者是一个使用等于空字符串的名称注册的视图。
如果任何路径段元素以特殊字符开头
@@(把它们当作护目镜),该部分的值减去护目镜字符被认为是 view name 立刻,横移停止在那里。这允许您明确地寻址可能与树中资源名称同名的视图。
最后,Traversal负责定位 virtual root . 在“虚拟主机”期间使用虚拟根目录。见 虚拟主机 信息章节。在这一章里我们不会再多谈这件事了。
遍历算法示例¶
没有人可以单独通过类比和描述来理解遍历算法,所以让我们来研究一些使用具体URL和资源树组合的遍历场景。
让我们假设用户要求 http://example.com/foo/bar/baz/biz/buz.txt . 请求的 PATH_INFO 在那种情况下 /foo/bar/baz/biz/buz.txt . 让我们进一步假设当这个请求出现时,我们正在遍历以下资源树:
/--
|
|-- foo
|
----bar
以下是发生的事情:
traversal 遍历根,并尝试找到它找到的“foo”。
traversal 遍历“foo”,并尝试找到它找到的“bar”。
traversal 遍历“bar”,并尝试查找它找不到的“baz”(“bar”资源引发
KeyError当被问到“baz”时。
事实上,它在这一点上没有找到“baz”,并不意味着一个错误条件。它表示以下内容:
此时,遍历已结束,并且 view lookup 开始。
因为它是“上下文”资源,所以视图查找机制检查“栏”以找出它是什么“类型”。假设它发现上下文是 Bar 类型(因为“bar”恰好是类的一个实例 Bar )使用 view name (baz )类型“视图查找”要求 application registry 这个问题:
请给我找一个 view callable 注册使用 view configuration 具有可用于类的名称“baz”
Bar.
假设视图查找找不到匹配的视图类型。在这种情况下, Pyramid router 返回的结果 Not Found View 请求结束。
但是,对于这棵树:
/--
|
|-- foo
|
----bar
|
----baz
|
biz
用户要求 http://example.com/foo/bar/baz/biz/buz.txt
traversal 遍历“foo”,并尝试找到它找到的“bar”。
traversal 遍历“bar”,并尝试找到它找到的“baz”。
traversal 横穿“baz”,并试图找到“biz”,它发现。
traversal 遍历“biz”,并试图找到它找不到的“buz.txt”。
此时,它没有找到与“buz.txt”相关的资源,这并不意味着存在错误条件。它表示以下内容:
此时,遍历已结束,并且 view lookup 开始。
因为它是“上下文”资源,所以视图查找机制检查“biz”资源,找出它是什么“类型”。假设它发现资源是 Biz 类型(因为“biz”是python类的一个实例 Biz )使用 view name (buz.txt )类型“视图查找”要求 application registry 这个问题:
请给我找一个 view callable 注册于 view configuration 用名字
buz.txt可以用来上课的Biz.
假设这个问题是由应用程序注册中心回答的。在这种情况下,应用程序注册表返回 view callable . 然后用当前的 WebOb request 作为唯一的论据, request . 它将返回一个响应。
在视图配置中使用资源接口¶
而不是用 context 命名了一个python资源 班 ,您可以选择使用 context 这是一个 interface . 接口可以任意附加到任何资源对象。视图查找专门处理上下文接口,因此资源的标识可以与实现它的类的标识分离。因此,将视图与接口关联可以提供更大的灵活性,以便在资源类型的两个或多个不同实现之间共享单个视图。例如,如果具有不同python类类型的两个资源对象共享同一个接口,则可以使用相同的视图配置将它们指定为 context .
为了在视图调度期间使用应用程序中的接口,必须创建一个接口,并用引用此接口的接口声明标记资源类或实例。
将接口附加到资源 班 ,定义接口并使用 zope.interface.implementer() 类修饰器,用于将接口与类关联。
1from zope.interface import Interface
2from zope.interface import implementer
3
4class IHello(Interface):
5 """ A marker interface """
6
7@implementer(IHello)
8class Hello(object):
9 pass
将接口附加到资源 实例 ,定义接口并使用 zope.interface.alsoProvides() 函数将接口与实例关联。此函数以接口附加到实例的方式改变实例。
1from zope.interface import Interface
2from zope.interface import alsoProvides
3
4class IHello(Interface):
5 """ A marker interface """
6
7class Hello(object):
8 pass
9
10def make_hello():
11 hello = Hello()
12 alsoProvides(hello, IHello)
13 return hello
无论如何将接口与资源实例或资源类关联,将该接口与可调用视图关联的结果代码都是相同的。假设上面的代码定义了 IHello 接口位于应用程序的根目录中,其模块名为“resources.py”,下面的接口声明将与 mypackage.views.hello_world 使用实现或提供此接口的资源进行查看。
1# config is an instance of pyramid.config.Configurator
2
3config.add_view('mypackage.views.hello_world', name='hello.html',
4 context='mypackage.resources.IHello')
任何时候确定为 context 提供此接口和名为 hello.html 是根据URL查找的, mypackage.views.hello_world 将调用View Callable。
注意,如果视图是针对资源类注册的,而视图也是针对资源类实现的接口注册的,则会产生歧义。为资源类注册的视图优先于为资源类实现的任何接口注册的任何视图。因此,如果一个视图配置命名为 context 资源的类类型和另一个视图配置名称的 context 对于由资源的类实现的接口,并且两个视图配置在其他方面相同,为上下文的类注册的视图将“获胜”。
有关使用接口定义资源以在视图配置中使用的更多信息,请参阅 实现接口的资源 .
工具书类¶
演示如何 traversal 可以在 Pyramid 应用程序存在于 zodb+遍历wiki教程 .
见 查看配置 详细信息章节 view lookup .
这个 pyramid.traversal 模块包含处理遍历的API函数,例如应用程序代码中的遍历调用。
这个 pyramid.request.Request.resource_url() 方法在给定从资源树检索到的资源时生成URL。